






前言
微服务环境下,服务发现、负载均衡、健康检查以及必要的服务治理措施都依赖于注册中心,如果将整套环境迁移到k8s上,那么注册中心的存留就值得一番思考了。
如果我们像一线大厂那种单元化架构搞异地多活,那么注册中心是必须是单独的存在,注册中心是指哪打哪,灾备、单元化负载均衡,动态单元化切流,一旦脱离了注册中心,整个体系是玩不转的;
但是如果你只是用注册中心做服务发现和负载均衡的话,那么注册中心真的是可有可无。
因此中小系统的架构下,将服务迁移到k8s里,用service name去做服务间的调用就是一种低成本的服务发现策略。
通过service name,其实背后的体系还是k8s的dns(kube dns/core dns)总之service name就是k8s内的一套名字服务。假如kp-id命名空间内存在一个service名为user-info-svc的service,那么其在集群中的完整A记录为:
user-info-svc.kp-id.svc.cluster.local |
如果是在同一个命名空间则可以直接以user-info-svc访问其背后的pod。
此处user-info-svc起到了服务发现和负载均衡的作用,而且是高可用的,其背后的机制是kube-proxy来维系iptables或者ipvs来实现,是由内核直接支持的。
因此服务可以使用该service name,将其当成域名来使用。这套机制和阿里的vipserver是类似的。

故障
有个线下集群,存在很多命名空间部署了很多服务,但是发现某些服务调用其他服务的时候报无法解析service name:

注意,该种提示和以下的错误提示的原因是完全不同的:

“Unknown host ruleengine-for-admin”代表查询dns但是dns没有查到,说明dns的链路是正常的,但是图1的提示则完全不是,代表没有dns服务。
由于是代表没有dns服务,那么去排查dns的问题,找到dns的ClusterIP,ping一下:

同时检查端口是否有listen:
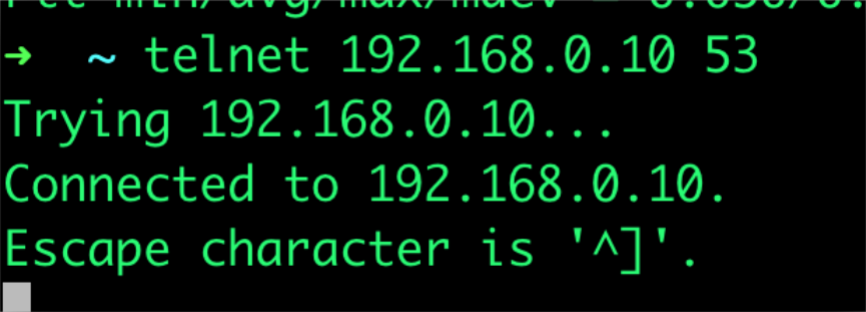
看来服务是正常的。那么就需要全链路的排查一下从pod到kube-dns整个过程中有什么问题。

DNS解析链路排查
首先创建一个DNS诊断工具的pod:

使用该pod检测:
kubectl exec -i -t dnsutils -- nslookup kubernetes.default |
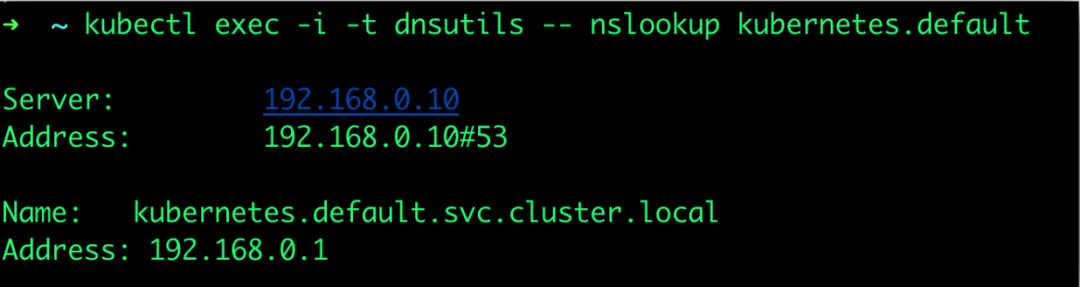
发现没有问题,排除。
然后检查本地dns配置文件:
kubectl exec -ti dnsutils -- cat etc/resolv.conf |

发现search域也没有问题。排除。
然后再检查dns的pod有无问题:
kubectl get pods --namespace=kube-system -l k8s-app=kube-dns |

Dns正常ready状态。排除
DNS的Endpoints:

代表dns的service name的pod,有时候service创建成功,但是其背后的pod并未和service关联上,也就是service并没有Endpoints,describe一下dns service同样可以检查:
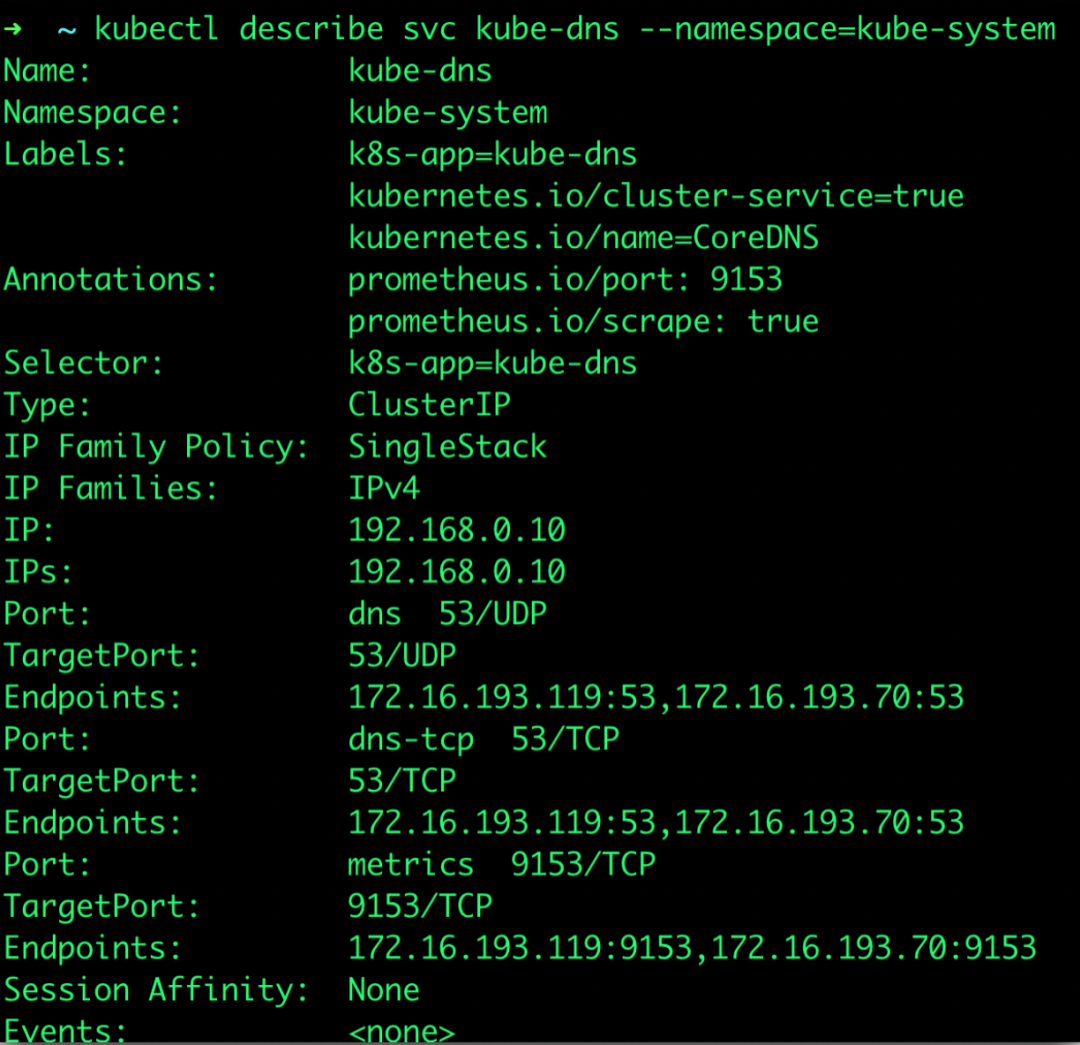
同样没有问题,排除掉。
下面就要看dns服务具体是怎么回事了,修改dns的配置,调整日志开关,打印日志:
kubectl -n kube-system edit configmap coredns |
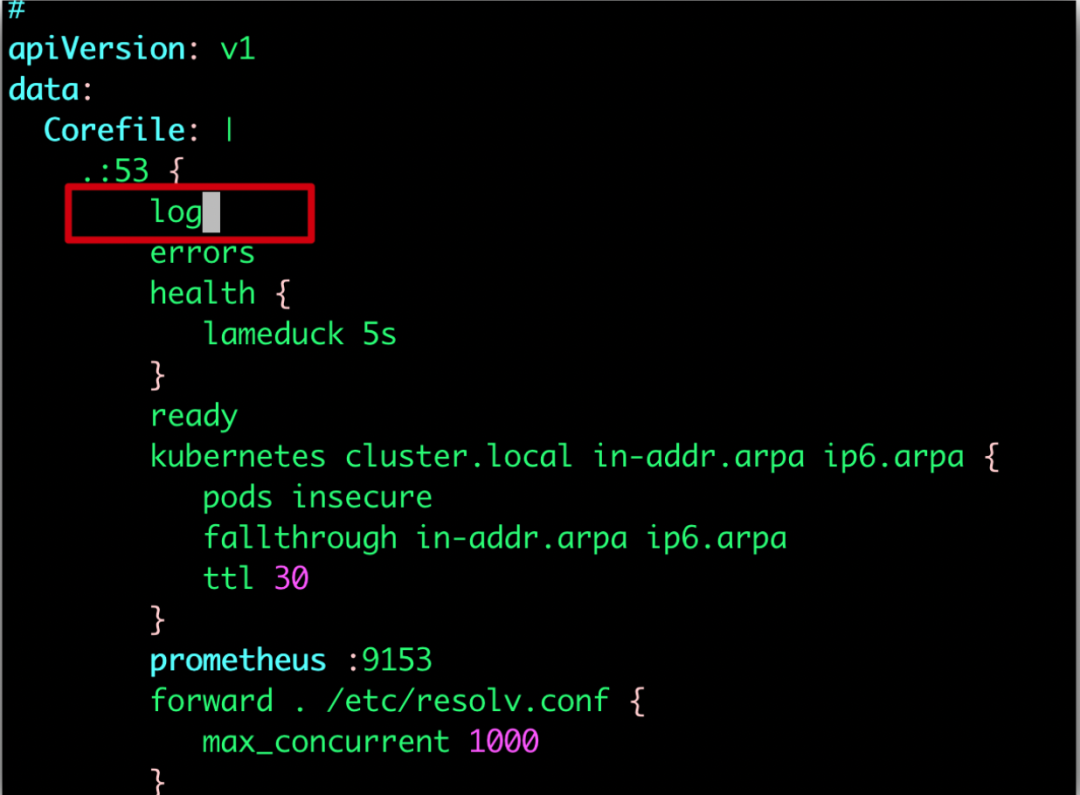
观察了一会,并且重建service 和pod,未发现明显的报错信息:
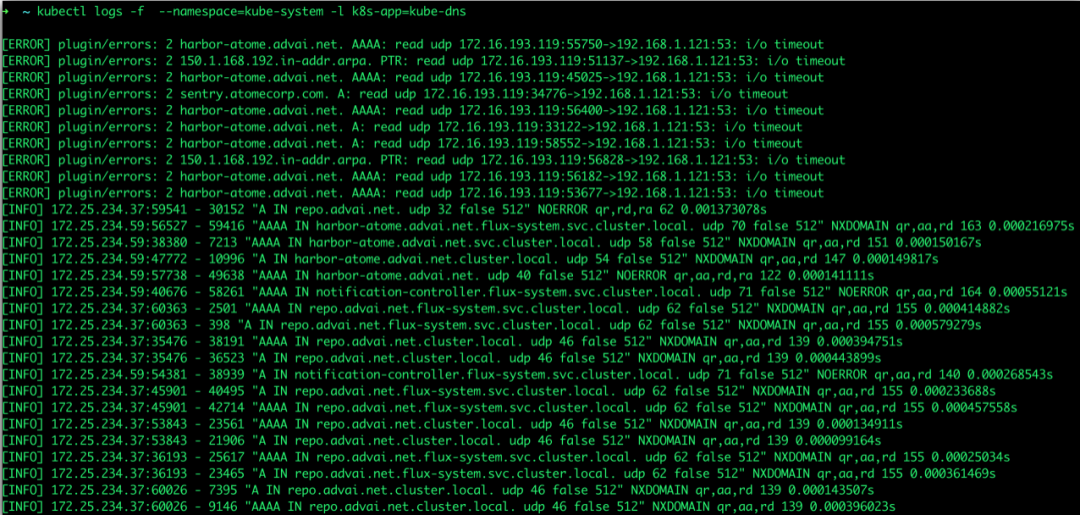

焦虑
排查到此,发现DNS是正常的,而且意外发现,有些service是可以解析,有些却不能解析,这个很奇怪,集中看了下不能解析service的pod,发现这些pod都在某一台worker上:
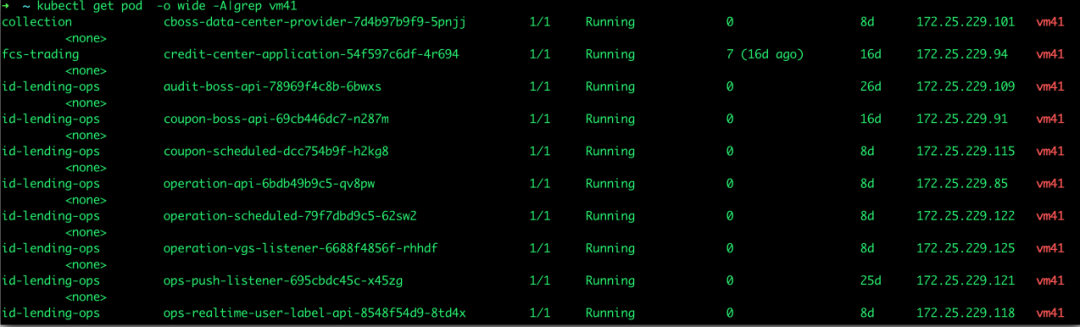
这个worker是几天前新加入的节点,集群的资源不够了,临时扩容了一下,难道是这个节点有问题吗?可是刚扩容之后是好的,经询问得知,该节点刚刚死机了一次重启过。回顾了下时间点,恰好是重启之后就出现了该问题。
检查了一下kube-proxy等相关进程都没有问题,此时陷入了沉思。
又将proxy mode从iptables和ipvs间切换了几次,将worker驱逐重建等,依然不好使。
查阅了很多资料,有指出是ipv6的问题,也有指出是1.18版本对ipv6支持不好,需要升级linux内核等措施,但是分析下来,依然觉得不像是,首先这个worker内核的版本是和其他节点相同的,没理由只是这个节点不兼容。

解决
又分析了一下,dns没有问题,会不会是网络的问题呢?是否是在链路层面?于是将关注点意向了网络插件,于是扫了一下calico,发现41节点上的calico重启的次数毕竟多,而且若干次之后偶尔就绪偶尔没有就绪:
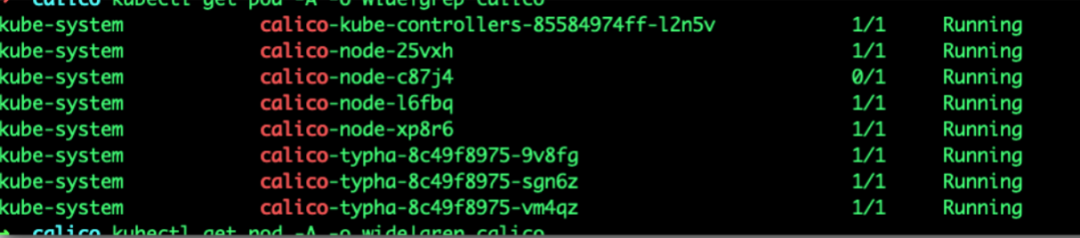
之前其实检查过calico,但是由于习惯的看是否 是Running,忽略了是否就绪,而且有时候就绪的状态瞬间就没了,印象中没有发现它的问题就直接略过了,因此一直没有注意calico,而且最开始就尝试在pod内是可以ping通dns service的IP的,因此没有考虑是网络问题。
看了下Caliao的日志:

原来是Calico并没有在本地网卡上绑定成功,没有ready,从而没有构建起BGP网络。
这个的原因没有深入分析,大致分析下有可能是41这个机器上启动了一个docker,以单机及compose的方式运行了一些中间件。导致Calico在初始化的时候错误的绑定了网卡,没有构建起正常的三层路由网络。
于是,将Calico的配置改一下,使用静态网卡绑定,强制绑定到eth3这个网卡上:

然后将kube-rpxy删除,calico删除重建,发现依然不行:

提示eth3处于down的状态,查看了下41的网卡设备,发现并无eth3的网卡,原来该机器和其他机器的网卡名称不同。
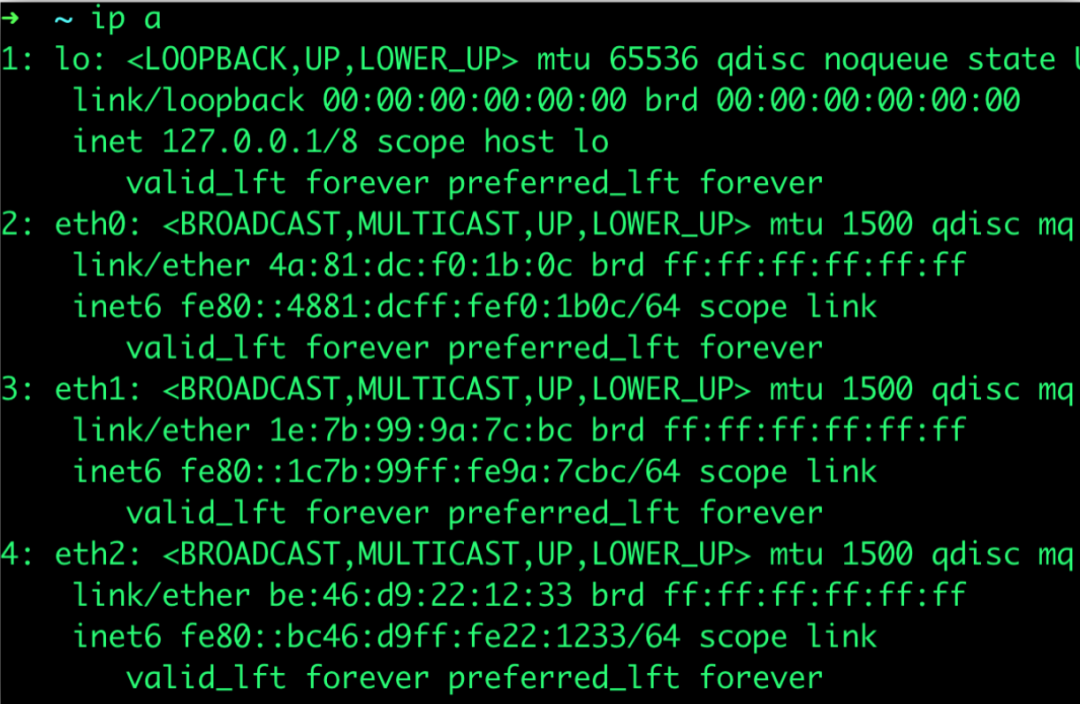
将网卡名称更改为eth3解决:

Calico顺利启动:
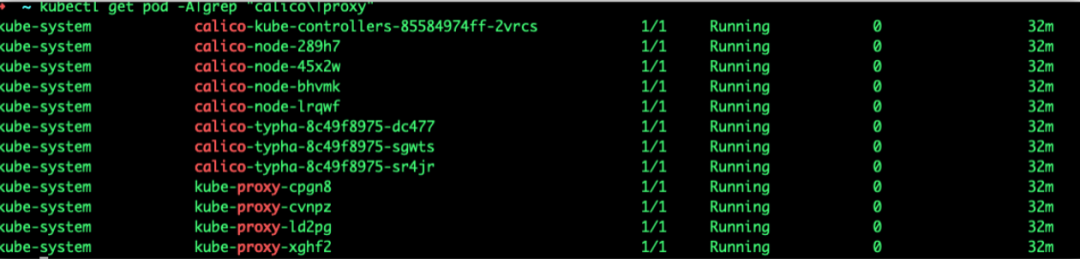

总结
该问题的原因是Calico的三层路由网络构架失败导致,因此也表现为被调度到该node上的pod无法解析service,失败的原因可能是该节点上本来就存在的docker构建的bridge网络对Calico产生了干扰,导致Calico初始化失败,最后通过静态绑定到固定的网卡来解决。

感谢阅读「技术创想」第50期文章
领创集团正在招聘中
期待你的加入
点击文末
“阅读原文”
获取更多
招聘信息
关于领创集团

