




定义⼀个接⼝interface TestInterface {void method();}static void main(String[] args) {定义接⼝的匿名实现TestInterface testInterface = new TestInterface() {@Overridepublic void method() {System.out.println("hello world");}};调⽤接⼝testInterface.method();}
/ 定义⼀个接⼝@FunctionalInterface //注意这⾥添加了注解interface TestInterface {void method();}static void main(String[] args) {// 定义接⼝的匿名实现TestInterface testInterface = () -> {System.out.println("hello world");};// 调⽤接⼝testInterface.method();}

Publisher
Subscriber
Subcription
⼀句话,Reactive Programming是⼀种编程⽅式;Reactive Streams是针对ReactiveProgramming制定的编程规范;Reactor是实现了Reactive Streams的编程框架(有具体的组件包),这些为spring webflflux提供了组件基础。

Thread per Connection:即⼀请求⼀线程,为每个请求分配⼀个线程,此线程负责请求的执⾏,当请求执⾏结束时,线程也随之结束。在没有nio之前,这是传统的java⽹络编程和servlet等所采⽤的即为线程模型。此⽅案的优点即实现简单,缺点则是⽅案的伸缩性受到线程数的限制。
Reactor in Single Thread:即为将需要执⾏的多个任务放置到⼀个队列中,并通过事件驱动的⽅式(通常做法),将每个任务交由某个线程去执⾏。在此⽅式下,即使只有⼀个线程,也可以实现⼀种伪多线程(参考python的协程),此⽅式的实现⽅式之⼀即为IO多路复⽤。此⽅案的优点是不受线程数的限制,且适合于CPU资源紧张的应⽤上。基于nio的mina、netty等框架,就是使⽤的此⽅式;缺点是受限于使⽤场景,仅适合于IO密集的应⽤,不太适合CPU密集的应⽤。

@RestController@RequestMapping("/test")public class TestController {@RequestMapping("/hello")public String demo(){return "hello world";}}
@RestController@RequestMapping("/test")public class TestController {@RequestMapping(value = "/foobar")public Mono<String> demo() {return Mono.just("hello world");}}

Mono
Flux
A Reactive Streams Publisher with rx operators that emits 0 to N elements, andthen completes (successfully or with an error). The recommended way to learnabout the Flux API and discover new operators is through the referencedocumentation, rather than through this javadoc (as opposed to learning moreabout individual operators). See the "which operator do I need?" appendix . It isintended to be used in implementations and return types. Input parameters shouldkeep using raw Publisher as much as possible. If it is known that the underlyingPublisher will emit 0 or 1 element, Mono should be used instead. Note that usingstate in the java.util.function / lambdas used within Flux operators should beavoided, as these may be shared between several Subscribers.subscribe(CoreSubscriber) is an internal extension to subscribe(Subscriber) usedinternally for Context passing. User provided Subscriber may be passed to this"subscribe" extension but will loose the available per-subscribeHooks.onLastOperator.
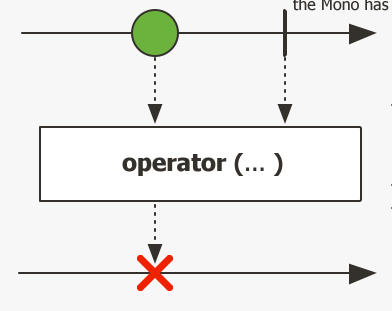
通俗来说,Mono就是Reactor中⼀个基础的任务单元,或者说是⼀段lamda表达式指令。所以我们查看Mono的各种⽅法时,⼊参基本都是 FunctionalInterface ,这这段指令内,我们可以接收若⼲参数,同时返回若⼲结果值;甚⾄可以返回另⼀个Mono对象。
Mono.just("hello world")//从字符串创建⼀个Mono对象,当任务被执⾏时,会返回此字符串.subscribe();Mono.just(123)//从int创建⼀个Mono对象.subscribe();Mono.empty()//创建⼀个不返回任何值的Mono对象,函数原型为`public static <T> Mono<T> empty()`,//因此返回值可以被当作任何类型.subscribe();
Mono.fromRunnable(()->{//从Runnable创建,这⾥使⽤了lamda表达式,当Mono被执⾏时,此lamda包裹的代码段会被执⾏System.out.println("hello world");});Mono.fromCallable(() -> {//从Callable创建,和Runnable的区别是带返回值return "Hello world";}).subscribe()
Mono.defer(()->{return Mono.just("hello world");//注意这⾥返回了⼀个Mono,⽽⾮其他类型}).subscribe();
Mono.empty().then(Mono.fromRunnable(() -> {System.out.println("hello world");})).subscribe();
Mono.just("hello world").doOnNext((e) -> {//e的类型为Mono.just()返回的类型System.out.println(e);//打印hello world}).doOnNext((e) -> {//这⾥调⽤了两次doOnNext,因为变量会在doOnNext间传递System.out.println(e);//打印hello world}).subscribe();
Mono.just("hello world").map((e) -> {System.out.println(e);//打印hello worldreturn "simon's dream";//这⾥返回了⼀个新的变量}).doOnNext((e) -> {System.out.println(e);//打印simon's dream}) .subscribe();Mono.just("hello world").flatMap((e) -> {//这⾥使⽤了flatMap,flatMap和map的区别是,//map是直接转换,flatMap是返回⼀个包裹了新值的MonoSystem.out.println(e);//打印hello worldreturn Mono.just("simon's dream");}).doOnNext((e) -> {System.out.println(e);//打印simon's dream}) .subscribe();
Mono a1 = Mono.defer(() -> {System.out.println("start");return Mono.just("a"); });a1.subscribe((e) -> {System.out.println("s1:" + e); });a1.subscribe((e) -> {System.out.println("s2:" + e); });System.out.println("==============================");a1 = a1.cache() ;a1.subscribe((e) -> {System.out.println("s21:" + e); });a1.subscribe((e) -> {System.out.println("s22:" + e); });
Mono.just("hello world").map((e) -> {throw new RuntimeException("这是⼿动扔出的异常");}).doOnError(e -> {//doOnError会拦截到异常,但不会捕获异常,这⾥可以打印异常的信息,同时异常会被继续向上抛e.printStackTrace();}).onErrorResume(e -> {//onErrorResume会捕获异常,同时产⽣⼀个新的Mono继续后续其他操作e.printStackTrace();return Mono.just("simon's dream");}).doOnNext(e -> {System.out.println(e);//打印simon's dream}).doOnSuccess(e -> {System.out.println(e);//打印simon's dream}) ;
int count = 0;Mono.fromRunnable(() -> {System.out.println("hello world");//会被打印3次}).repeatWhen(Repeat.onlyIf((e) -> {count++;return count < 3;})).subscribe() ;
int count = 0;Mono.fromRunnable(() -> {System.out.println("hello world");//会打印三次throw new RuntimeException("⼿动扔出的异常");}).retryWhen(Retry.onlyIf((e) -> {count++;return count < 3;})).onErrorResume((e) -> {System.out.println(e.getMessage());//打印⼀次return Mono.empty();}).subscribe() ;
Mono.just(10).filter((e) -> {return e > 5;}).doOnNext((e) -> {System.out.println("after filter1:" + e);//正常输出}).filter((e) -> {return e < 5;}).doOnNext((e) -> {System.out.println("after filter2:" + e);//没有输出}).then(Mono.fromRunnable(() -> {System.out.println("then");//正常输出})).subscribe();
Mono.just("hello world").doOnSuccess((e) -> {System.out.println(e);//打印hello world}).doFinally((e) -> {System.out.println("doFinally");//打印doFinally}).subscribe();Mono.just("hello world").doOnNext((e) -> {System.out.println(e);//打印hello worldthrow new RuntimeException("⼿动扔出的异常");}).doOnSuccess((e) -> {//因为出现了Exception,因此doOnSuccess并不会被执⾏System.out.println("doOnSuccess:" + e);}).doOnError((e) -> {System.out.println(e.getMessage());//打印异常信息}).doFinally((e) -> {System.out.println("doFinally");//打印doFinally}).subscribe();
Mono<Integer> mono1 = Mono.just(1);Mono<Integer> mono2 = Mono.just(2);Mono<Integer> mono3 = Mono.just(3);Mono.zip(mono1, mono2, mono3).doOnNext(e -> {System.out.println("结果:" + e);//输出[1,2,3],注意e是⼀个Tripple类型}).subscribe()
Mono<Integer> mono1 = Mono.just(1);Mono<Integer> mono2 = Mono.just(2);Mono<Integer> mono3 = Mono.just(3);Mono.zip((e) -> {return e;}, mono1, mono2, mono3).doOnNext(e -> {System.out.println("结果:" + Arrays.asList(e));//输出[1,2,3],注意e是⼀个Object[]类型}).subscribe() ;
Mono
FLux
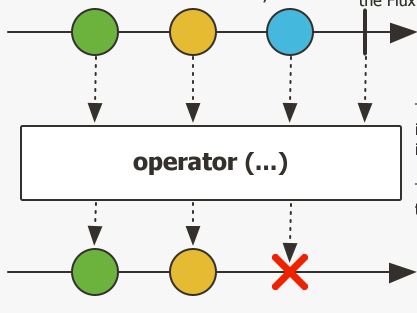
Flux.just(1,2,3,4,5,6,7,8,9)//这⾥可以理解为同时产⽣了多个Mono,且每个Mono包裹了⼀个元素,//每个Mono会被分别交给后续的任务进⾏处理.filter((e) -> { //每个元素都会被此过滤器过滤,其中通过的元素会流动到后续其他任务return e > 5;}).collectList()//收集所有元素并产⽣⼀个List.doOnNext((list) -> {//这⾥的⼊参是⼀个ListSystem.out.println("after filter1:" + list);//输出 after filter1:[6, 7, 8, 9]}).then(Mono.fromRunnable(() -> {System.out.println("then");//输出then})).subscribe() ;x.fromIterable(list) .reduce(set, (initial, e) -> {//将每个元素过滤并添加到Set中 if (e > 5) { initial.add(e); } return initial; }) .doOnNext(e -> {//e是Set类型 System.out.println("结果:" + e);//输出:[6, 7, 8, 9] }) .subscribe() ;
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);Set set = new HashSet();Flux.fromIterable(list).reduce(set, (initial, e) -> {//将每个元素过滤并添加到Set中if (e > 5) {initial.add(e);}return initial;}).doOnNext(e -> {//e是Set类型System.out.println("结果:" + e);//输出:[6, 7, 8, 9]}).subscribe() ;



