




sklearn (scikit-learn) 是基于 Python 语言的机器学习工具
简单高效的数据挖掘和数据分析工具
可供大家在各种环境中重复使用
建立在 NumPy ,SciPy 和 matplotlib 上
开源,可商业使用 - BSD许可证
sklearn库的导图
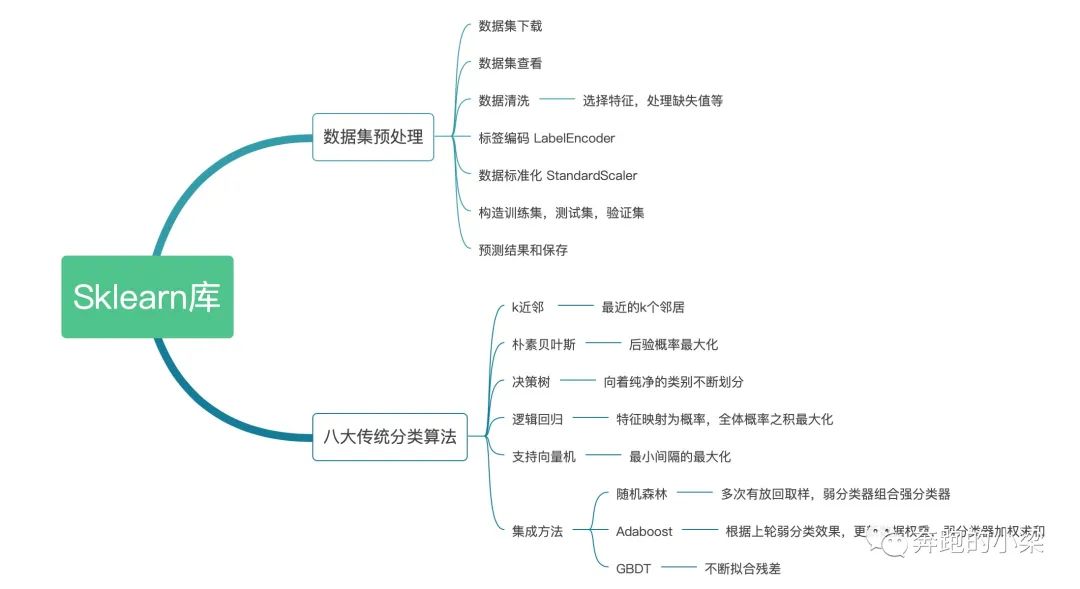
1、数据预处理
数据预处理就是通过对数据的一些转换,取特征,填充等等操作,使得数据组织形式、特征更加符合后续分类算法的要求!!需要一定的经验。
import seaborn as sns#加载数据集iris = sns.load_dataset("iris")#数据清洗,筛去部分特征iris_simple = iris.drop(["sepal_length", "sepal_width"], axis=1)iris_simple.head()#标签编码,将字符串映射为整数from sklearn.preprocessing import LabelEncoderencoder = LabelEncoder()iris_simple["species"] = encoder.fit_transform(iris_simple["species"])#构建训练集和测试集合from sklearn.model_selection import train_test_splittrain_set, test_set = train_test_split(iris_simple, test_size=0.2)test_set.head()#分离训练集的特征和标签iris_x_train = train_set[["petal_length", "petal_width"]]iris_y_train = train_set["species"].copy()#分离测试集的特征和标签iris_x_test = test_set[["petal_length", "petal_width"]]iris_y_test = test_set["species"].copy()
2、k近邻算法
对某个点做预测,就是将距离该点最近的k个点取出来,并且将该点预测为取出的k个点中最多的那个类别。
from sklearn.neighbors import KNeighborsClassifier#构建分类器对象,目的就是训练出这个对象clf = KNeighborsClassifier()#训练分类器对象clf.fit(iris_x_train, iris_y_train)#将训练好的分类器来预测测试集结果res = clf.predict(iris_x_test)print(res)print(iris_y_test.values)#评估结果accuracy = clf.score(iris_x_test, iris_y_test)print("预测正确率:{:.0%}".format(accuracy))#存储数据out = iris_x_test.copy()out["y"] = iris_y_testout["pre"] = resout.to_csv("iris_predict.csv")
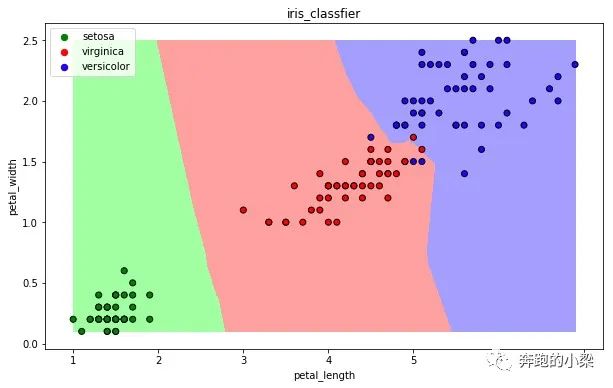
可视化结果
import numpy as npimport matplotlib as mplimport matplotlib.pyplot as pltdef draw(clf):# 将数据特征网格化M, N = 500, 500x1_min, x2_min = iris_simple[["petal_length", "petal_width"]].min(axis=0)x1_max, x2_max = iris_simple[["petal_length", "petal_width"]].max(axis=0)t1 = np.linspace(x1_min, x1_max, M)t2 = np.linspace(x2_min, x2_max, N)x1, x2 = np.meshgrid(t1, t2)# 用分类器预测每一个网格x_show = np.stack((x1.flat, x2.flat), axis=1)y_predict = clf.predict(x_show)# 配色cm_light = mpl.colors.ListedColormap(["#A0FFA0", "#FFA0A0", "#A0A0FF"])cm_dark = mpl.colors.ListedColormap(["g", "r", "b"])# 绘制预测区域图plt.figure(figsize=(10, 6))plt.pcolormesh(t1, t2, y_predict.reshape(x1.shape), cmap=cm_light)# 绘制原始数据点plt.scatter(iris_simple["petal_length"], iris_simple["petal_width"], label=None,c=iris_simple["species"], cmap=cm_dark, marker='o', edgecolors='k')plt.xlabel("petal_length")plt.ylabel("petal_width")# 绘制图例color = ["g", "r", "b"]species = ["setosa", "virginica", "versicolor"]for i in range(3):plt.scatter([], [], c=color[i], s=40, label=species[i]) # 利用空点绘制图例plt.legend(loc="best")plt.title('iris_classfier')#调用函数draw(clf)
3、朴素贝叶斯
训练集中特征(x1,x2,x3)中出现了结果(y1,y2),如果y1出现的次数比y2多,那么就将特征(x1,x2,x3)预测为y1
from sklearn.naive_bayes import GaussianNB#构建分类器对象,目的就是训练这个对象clf = GaussianNB()#训练clf.fit(iris_x_train, iris_y_train)#预测res = clf.predict(iris_x_test)print(res)print(iris_y_test.values)#评估结果accuracy = clf.score(iris_x_test, iris_y_test)print("预测正确率:{:.0%}".format(accuracy))可视化draw(clf)
后续的分类算法的使用流程都和上述一致:
1、从sklearn中导入对应的分类器
2、构建分类器对象,我们的目标就是训练这个对象
3、训练分类器对象
4、利用这个训练好的对象预测结果
5、评估结果
6、可视化【可视化就是将数据特征进行网格化,如何用训练好的分类器去预测每一个网格的结果,如何再可视化展示】
说明一下后面的算法思想:
1、决策树:每次都是通过一个特征将数据尽可能分为纯净的两类数据,如果其中一类已经完全存,则完全纯净的类就结束划分,否则迭代下去继续划分。
2、逻辑回归:
训练:通过一个映射方式,将特征X=(x1, x2) 映射成 P(y=ck), 求使得所有概率之积最大化的映射方式里的参数。
预测:计算p(y=ck) 取概率最大的那个类别作为预测对象的分类。
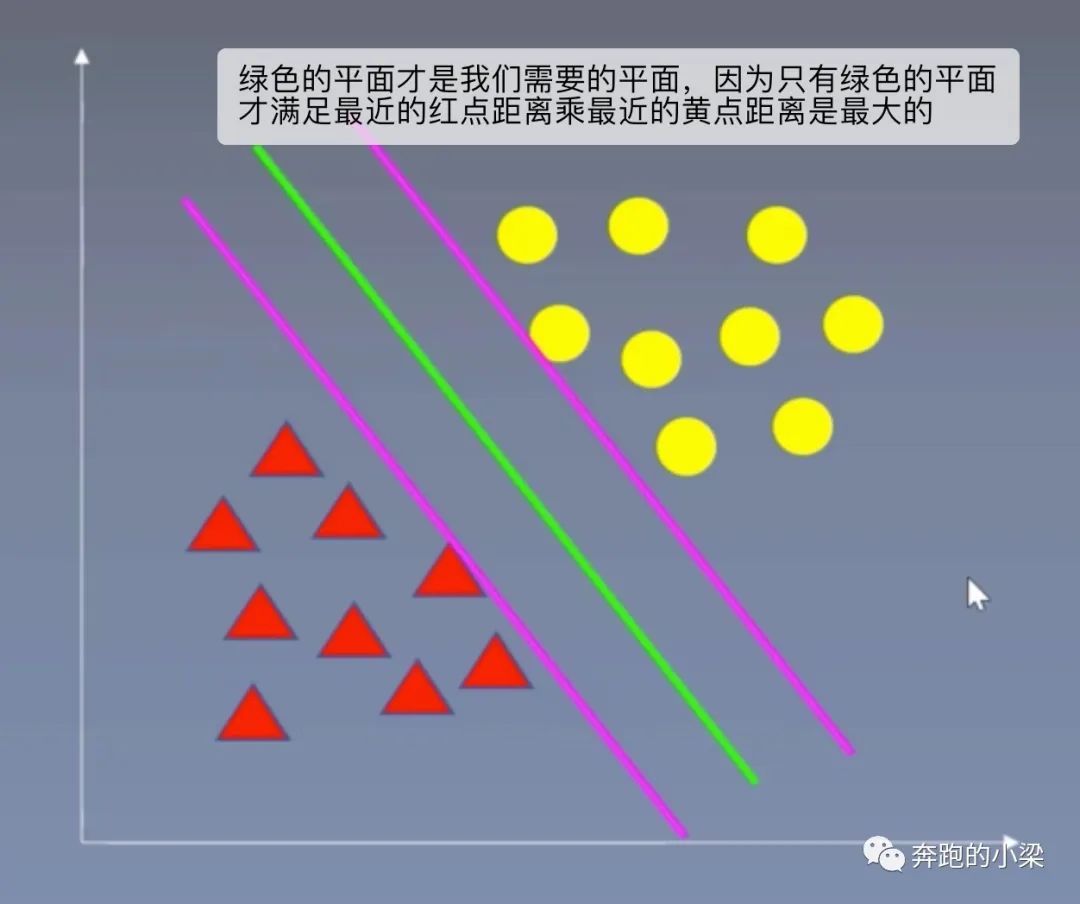
3、支持向量积:以二分类为例,假设数据可用一个超平面将两类数据完全分开(这样的超平面很多),要求是求出每个类别最近点到平面的距离之积最大的那个平面。
文章转载自梁霖编程工具库,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
