一、Kafka概述
Apache Kafka是一个分布式发布 - 订阅消息系统和一个强大的队列,可以处理大量的数据,并使您能够将消息从一个端点传递到另一个端点。 Kafka适合离线和在线消息消费。 Kafka消息保留在磁盘上,并在群集内复制以防止数据丢失。 Kafka构建在ZooKeeper同步服务之上。 Kafka支持低延迟消息传递,并在出现机器故障时提供对容错的保证。 它具有处理大量不同消费者的能力。 Kafka非常快,执行2百万写/秒。 Kafka将所有数据保存到磁盘,这实质上意味着所有写入都会进入操作系统(RAM)的页面缓存。 这使得将数据从页面缓存传输到网络套接字非常有效。
二、Kafka示例环境搭建
本示例搭建的Kafka环境为示例代码演示环境,生产环境一般为集群配置。
官网下载kafka并解压:Apache Kafka
启动zookeeper:Kafka依赖zookeeper服务,cd到Kafka解压目录,执行如下命令启动zookeeper。
bin/zookeeper-server-start.sh config/zookeeper.properties

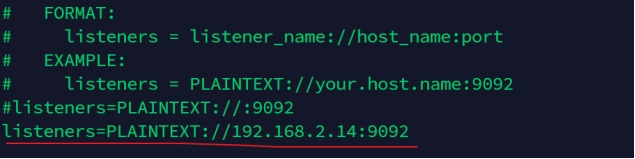
启动Kafka:配置config/server.properties,增加listeners配置如下,其中IP地址为本机IP,保存配置。
listeners=PLAINTEXT://192.168.2.14:9092
执行bin/kafka-server-start.sh config/server.properties启动Kafka。
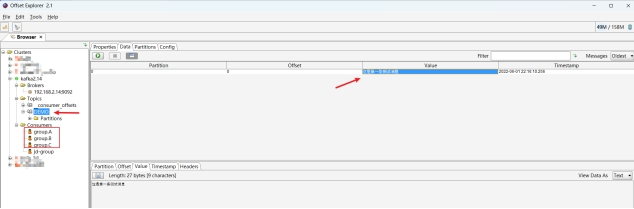
安装Kafka可视化工具:Offset Explorer (kafkatool.com)。
如果正常工作环境为Windows系统,可以下载安装Kafka可视化工具,方便查看Kafka Topic消息及消费组信息等。
安装完毕后,打开Offset Explorer,参照如下配置新建连接,可以查看Brokers、Topic以及Consumers信息,初次打开的话内容应该为空,没有新建的Topic、也没有Consumer。
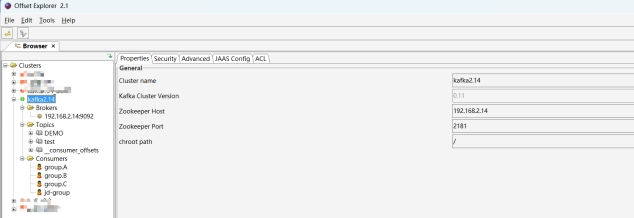
三、多个消费组独立消费同一个消息队列示例
Kafka一个很重要的特性就是,只需写入一次消息,可以支持任意多的应用读取这个消息。 换句话说,每个应用都可以读到全量的消息。为了使得每个应用都能读到全量消息,应用需要有不同的消费组。接下来通过java编写代码来演示该能力。
创建java maven工程,pom.xml添加Kafka依赖。
<dependencies> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>2.8.1</version> </dependency> </dependencies>
创建ProducerDemo类,代码及注释如下:
package com.demo.kafka;
import java.util.Properties;
import java.util.Scanner;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
public class ProducerDemo {
// Kafka消息主题
public final static String TOPIC = "DEMO";
// Kafka Broker Server
public final static String BROKER_LIST = "192.168.2.14:9092";
public static void main(String[] args) {
Properties props = new Properties();
// 设置key序列化器
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 设置value序列化器
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 设置重试次数
props.put(ProducerConfig.RETRIES_CONFIG, 10);
// 设置集群服务地址
props.put("bootstrap.servers", BROKER_LIST);
// 根据上述属性配置创建生产者
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
while (true) {
// 控制台接收用户输入消息,回车发送
Scanner input = new Scanner(System.in);
if (input.hasNextLine()) {
String message = input.nextLine();
ProducerRecord<String, String> record = new ProducerRecord<String, String>(TOPIC, message);
try {
producer.send(record);
} catch (Exception e) {
e.printStackTrace();
producer.close();
}
}
}
}
}创建ConsumerDemo类,代码及注释如下:
package com.demo.kafka;
import java.time.Duration;
import java.util.Arrays;
import java.util.Collections;
import java.util.Properties;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
public class ConsumerDemo extends Thread {
// Kafka消息主题
public final static String TOPIC = "DEMO";
// Kafka Broker Server
public final static String BROKER_LIST = "192.168.2.14:9092";
public static void main(String[] args) {
Properties props = new Properties();
// 设置key反序列化器
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 设置value反序列化器
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 设置集群服务地址
props.put("bootstrap.servers", BROKER_LIST);
// 创建消费组A
props.put("group.id", "group.A");
KafkaConsumer<String, String> consumerA = new KafkaConsumer<>(props);
// 创建消费组B
props.put("group.id", "group.B");
KafkaConsumer<String, String> consumerB = new KafkaConsumer<>(props);
// 创建消费组C
props.put("group.id", "group.C");
KafkaConsumer<String, String> consumerC = new KafkaConsumer<>(props);
// 消费组A、B、C订阅同一个消息队列
consumerA.subscribe(Collections.singletonList(TOPIC));
consumerB.subscribe(Collections.singletonList(TOPIC));
consumerC.subscribe(Collections.singletonList(TOPIC));
while (true) {
// 消费组A消费TOPIC中的消息,拉取间隔为1s
ConsumerRecords<String, String> records = consumerA.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
System.out.println("consumerA消费消息:");
System.out.printf("offset = %d, value = %s", record.offset(), record.value());
System.out.println();
}
// 消费组B消费TOPIC中的消息,拉取间隔为1s
records = consumerB.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
System.out.println("consumerB消费消息:");
System.out.printf("offset = %d, value = %s", record.offset(), record.value());
System.out.println();
}
// 消费组C消费TOPIC中的消息,拉取间隔为1s
records = consumerC.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
System.out.println("consumerC消费消息:");
System.out.printf("offset = %d, value = %s", record.offset(), record.value());
System.out.println();
}
}
}
}运行ConsumerDemo.main(),该类共创建了三个消费组consumerA、consumerB、consumerC,均订阅了同一个消息主题DEMO,并持续在控制台打印消费的消息。
- 运行ProducerDemo.main(),该类创建了一个生产者并持续接收控制台用户的输入作为消息内容,并向消息主题DEMO发送消息。
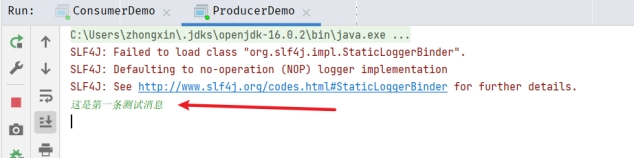
现在,试着在控制台输入一条消息并回车。
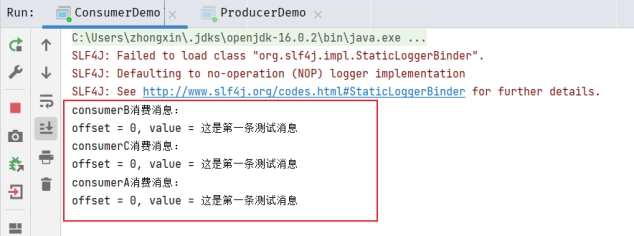
然后查看ConsumerDemo页签查看各消费组消费的消息信息,可以发现三个消费组都消费了同一个主题信息。
- 通过Offset Explorer可视化工具也可以查看到对应TOPIC下的消息,以及创建的消费组。