





前言
一个信息系统从前期的规划,到具体的建设,再到最终建成,往往耗时数月甚至数年时间。信息系统建成后,伴随着业务的发展会面临着系统的不断迭代,如旧业务的升级、新需求的加入等,这将导致信息系统的规模越来越大,在数据库层面表现为数据量不断增长、负载增加等,会带来存储空间不足、响应时间变长甚至无响应等一系列问题,此时就需要对信息系统进行优化,从而更好支撑用户的业务开展。
数据库的优化是信息系统优化的重中之重,涉及多个维度,如 SQL 语句优化、合理添加索引、分库分表、数据分区、数据库引擎加速机制、基于代价估算的查询优化策略、多版本并发控制技术、数据库参数配置优化、高效的数据缓冲机制、定期 Vacuum 和 Analyse、数据库应用设计优化等技术来提升数据库整体性能。

1. 数据库层面
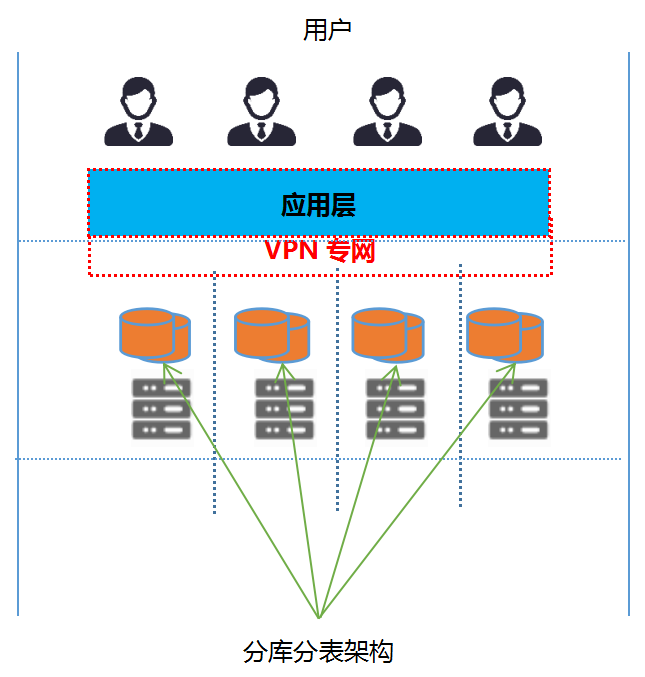
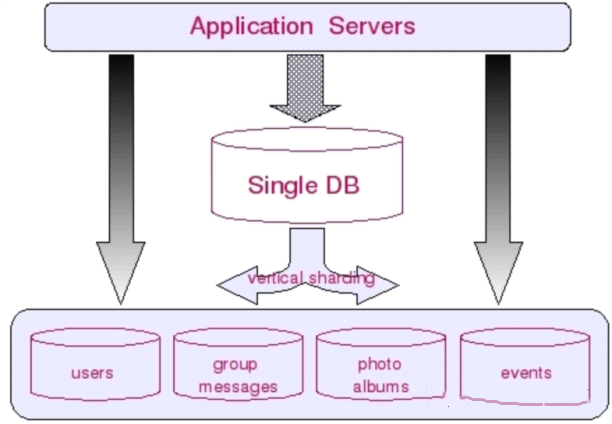
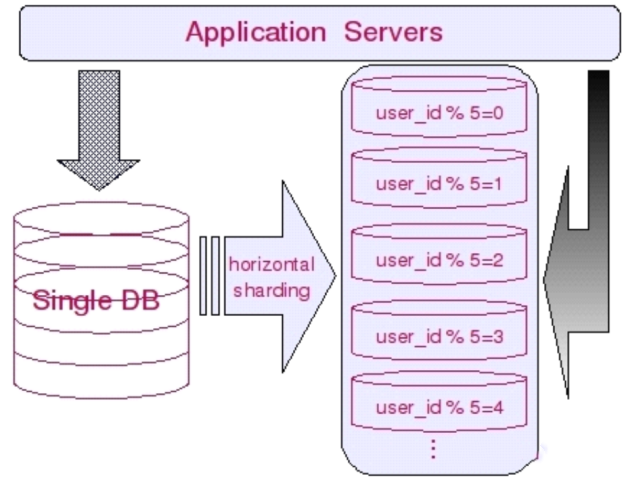
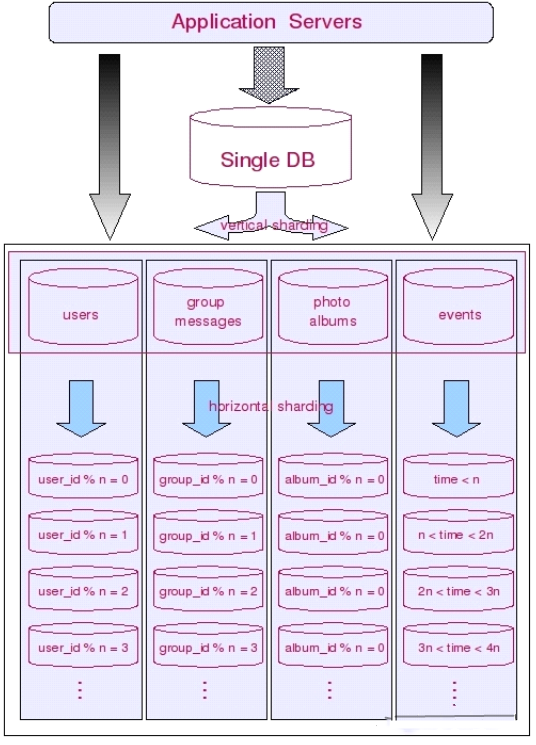
范围分区:分区规则根据 KEY 按照不同的范围映射到不同的分区中,每个范围都有一个上下限值;
分区给用户带来的价值:
2. SQl 优化
2.1 合理的编写 SQL 语句
2.2 针对场景的 SQL 优化建议
2.3 合理的创建索引
(1)定义主键的数据列一定要建立索引;
(2)定义有外键的数据列一定要建立索引;
(3)对于经常查询的数据列最好建立索引;
(4)对于需要在指定范围内的快速或频繁查询的数据列;
(5)经常用在 WHERE 子句中的数据列;
(6)经常出现在关键字 order by、group by、distinct 后面的字段,建立索引;如果建立的是复合索引,索引的字段顺序要和这些关键字后面的字段顺序一致,否则索引不会被使用;
(7)对于那些查询中很少涉及的列,重复值比较多的列不要建立索引;
(8)对于定义为 text 、 image 和 bit 的数据类型的列不要建立索引;
(9)对于经常存取的列避免建立索引;
(10)限制表上的索引数目。对一个存在大量更新操作的表,所建索引的数目一般不要超过3个,最多不要超过5个。索引虽说提高了访问速度,但太多索引会影响数据的更新操作;
(11)对复合索引,按照字段在查询条件中出现的频度建立索引。在复合索引中,记录首先按照第一个字段排序。对于在第一个字段上取值相同的记录,系统再按照第二个字段的取值排序,以此类推。因此只有复合索引的第一个字段出现在查询条件中,该索引才可能被使用,因此将应用频度高的字段,放置在复合索引的前面,会使系统最大可能地使用此索引,发挥索引的作用。
2.4 定位慢SQL并且优化
(1)查看慢日志,定位到具体的 SQL 语句。
(2)根据执行计划针对数据库 SQL 语句进行分析。
(3)根据结果对 SQL 语句进行修改或增加所需的索引。
(4)经过测试后达到效果后上线。
3.结合应用层优化
3.1 应用代码
3.2 合理使用连接池
4.操作系统层面优化
4.1 存储
生产环境通常使用固态磁盘,如目前使用广泛的 SATASSD 和 PCieSSD 。建议使用企业级 SSD ;或使用外部存储设备,例如 SAN(存储区域网络)和 NAS(网络接入存储)。
4.2 CPU
服务器在 BIOS 中如可设置 CPU 的性能模式,可能的模式有高性能模式、普通模式和节能模式,建议使用高性能模式。
4.3 内存
4.4 I/O调度算法
4.5 预读参数
4.6 Swap
4.7 透明大页
( TransparentHugePages,THP )
4.8 NUMA 架构
4.9 虚拟内存参数
(dirty_ratio/dirty_background_ratio)
4.10 文件系统( ext4/XFS )
4.11 网络
【附录A】
参数名称 | 建议值 | 参数说明 |
Work_mem | (available_ram*0.25)/max_connections 即: 1/4的RAM的值 | 内部排序和哈希操作可使用的工作内存大小。业务逻辑的SQL中含有order by,group by、distinct等关键字的操作将使用该内存,如涉及这些操作的表或中间结果较大,要酌情增加该值。 |
Shared_buffers | 服务器总内存的25% | 设置数据库服务器将使用的共享内存缓冲区大小。 |
maintenance_work_mem | 大于等于work_mem值 | 声明在维护性操作(比如 VACUUM,CREATE INDEX,ALTER TABLE ADD FOREIGN KEY 等)中使用的最大的内存数。在数据库数据载入后创建索引、主键、外键的过程中可以适当调大该值,提高速度。 |
full_page_writes | Off | 如果设置为on系统会在checkpoint后页面的第一次修改时将该页面的所有内容都写回磁盘,增加了IO量,这样做的原因是防止操作系统或主机崩溃造成的脏页面写入不完整,也就是一个脏页面只有一部分被写回磁盘造成数据丢失。如果操作系统和服务器足够稳定,可以将该项设置为off。 |
wal_buffers | 1024kB | 日志缓冲区的大小,是共享缓冲区的一个部分。如果单位时间事务的数据修改数据量较大,或者开启了commit_delay,应该酌情增加该值。 |
checkpoint_timeout | 1500min | checkpoint的时间间隔,根据系统写的负载设置,一般不要太频繁。可以和后台写线程配置相关参数配合使用。 |
autovacuum | Off | 是否开启自动清理线程(如开启需要同时设置参数stats_start_collector = on,stats_row_level = on,),整理数据文件碎片、更新统计信息,如果系统中有大量的增删改操作,建议打开自动清理线程,这样一方面可以增加数据文件的物理连续性,减少磁盘的随机IO,一方面可以随时更新数据库的统计信息,使优化器可以选择最优的查询计划得到最好的查询性能。如果系统中只有只读的事务,那么关闭自动清理线程。 |
stats_start_collector | Off | 是否开启统计线程,该线程会在事务提交后采集一些统计信息(不是优化器使用的统计信息),如果没有使用统计信息的需求,关闭它避免额外的开销。 |
stats_reset_on_server_start | Off | 设置是否在服务器启动时清空已收集的统计信息。默认关闭,也就是统计信息在服务器多次重启过程中累加。这是一系统级参数,只能在服务器启动时设置。 |
stats_command_string | Off | 设置是否统计每个会话执行的SQL命令。这个选项缺省是关闭的。请注意即使把它打开,这个信息也不是所有用户都可见的,只有数据库管理员和会话的所有者才能看到。这是一个会话级参数,只有数据库管理员可以改变这个设置。 |
stats_row_level | Off | 设置是否统计行级别的信息。缺省是关闭的。这是一会话级参数。 |
default_statistics_target | 默认值 | 统计信息直方图的bin的个数,如果表的列没有设置统计目标,则使用该参数指定的值作为统计目标。 |
random_page_cost | 7 | 随机的获取一页的成本。 |

