




本文首发于

由于最近Sunnyvale的restack,我们组从MP3搬到MP6。

周末去办公室收拾东西的时候,路过广场前面的Data Center大箱子,隔着玻璃瞧了一眼里面的结构。
传统的网络架构称为接入-汇聚-核心架构 access-agg-core network architecture

起码在我14年考CCIE的时候,这种方案在业内还相当普遍。但是上过计算机网络的都知道,这种方案优势和缺陷都很明显。
优势在于汇聚层之间通过桥接进行二层转发:1.不需要过多配置,可以依靠网桥自学习。2.(在当年)硬件转发也比查路由来的快 3.可以构建不同于IP的企业专用网络协议
然而一旦网络规模变大,问题也就来了。网桥自学习会有两个问题:广播风暴和泛洪。于是分别引入了STP生成树协议打破网络环路,又用VLAN把物理网络划分成小规模的逻辑网络来解决泛洪过多。但是STP阻止环路的同时又造成了网络带宽减半。引入了per-VLAN spanning tree之后,又限制住了VLAN的数量。
但是在云计算场景下,即使打了一层层的补丁 access-agg-core
还是无法支撑整个数据中心。一方面是弹性计算带来的接入终端大量增加,虚拟机和容器可能在任何时候加入网络 引起大规模拓扑变化。另一方面,随着单体服务向微服务转变,服务器间的通信流量远远超出客户端与服务器的通信流量。
Clos网络拓扑
准确说,现在云厂商使用的是Clos拓扑中的leaf-spine架构。leaf交换机作为ToR (top of rack)与服务器处于同一个机架,每个leaf交换机连接到所有spine交换机。spine交换机仅连接leaf交换机,不提供别的功能。
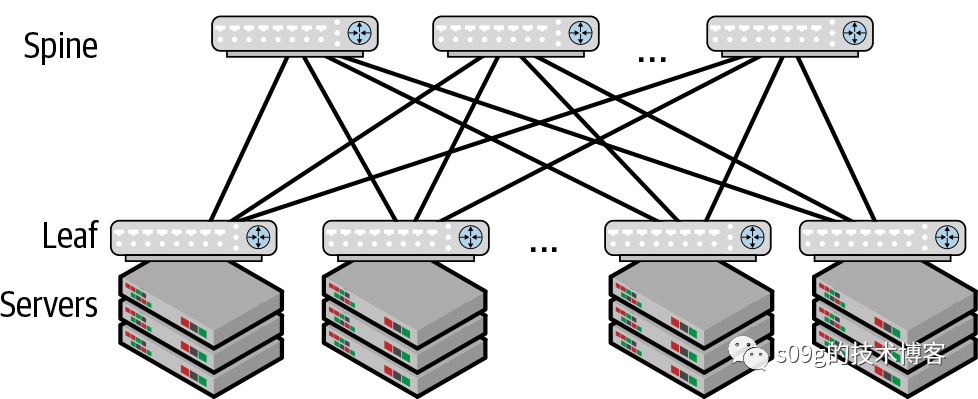
access-agg-core
有一个问题,每个园区的汇聚层只支持两台汇聚交换机。就这两台还需要用vPC虚拟端口通道(virtual-port-channel)
,消除阻塞,利用带宽。Clos拓扑直接放弃了STP控制交换机互联,而使用IP路由来作为主要的数据转发模式,桥接(2层转发)仅发生在同一个rack内部。
但是Clos拓扑也有一个问题,spine和leaf之间需要全联通。因此园区内能接入的终端设备受到交换机端口数量的限制。而且leaf交换机作为ToR,每个机架上的服务器数量也是有上限的。所以一个二层leaf-spine架构能接入的终端也就是几千而已。
多层Clos
二层Clos拓扑显然是不够的,大家基本上都会拓展Clos的层数。比较常见的方案有两种,先说个友商。
Facebook在2014年发表了一篇博客《Introducing data center fabric, the next-generation Facebook data center network》,其中介绍了他们将4个fabric交换机和48个ToR作为一个Server Pod
。Server Pod
算是他们的标准网络单元。
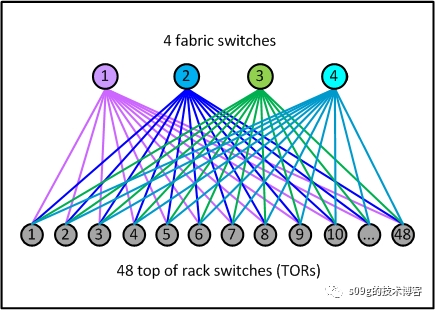
然后又在园区内创建了4个独立的spine plane。Server Pod中的每个fabric交换机和1个spine 交换机连接

但是很快他们还是遇到了扩展性的问题,事情就是从这里开始走偏了:Facebook开始改进交换机了。Facebook的第一代fabric交换机产品叫6-pack,因为它使用了6个Wedge。Wedge是Facebook自研的ToR,搭载了基于Linux自研的FBOSS网络操作系统。但是很快6-pack不够用了。于是Facebook拿了12个Wedge做了一个二层Clos结构(4个spine+8个leaf),然后放进一个机箱,取名Backpack。
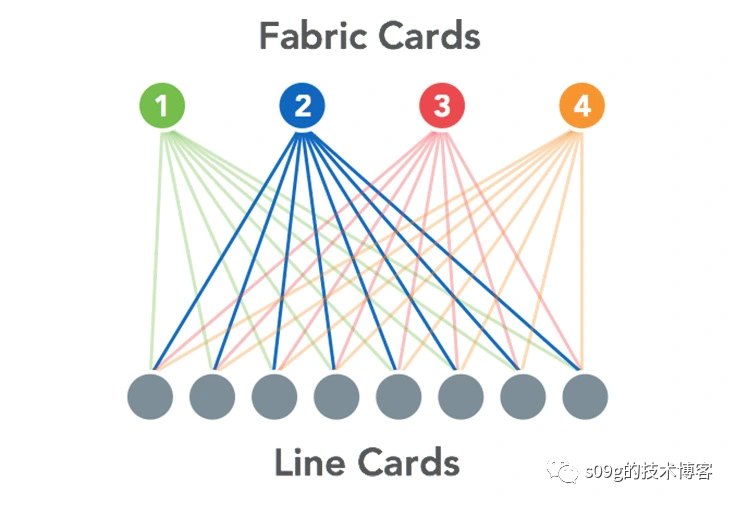
Backpack的定位和6-pack差不多,放在每个server pod里作为fabric switch,向北连接Spine Plane.
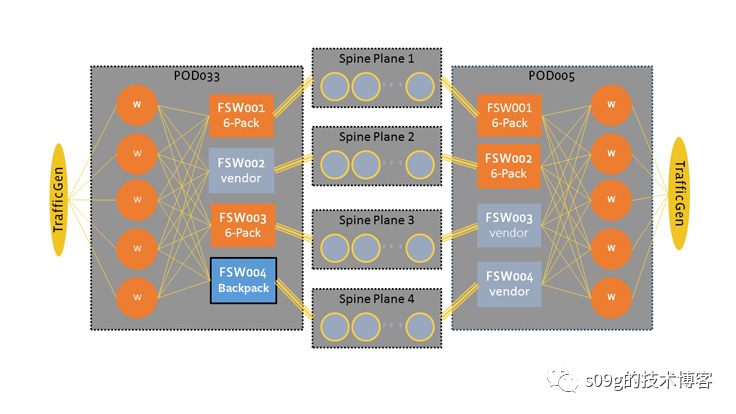
但是没过两年,网络瓶颈又到了,这次还是跨园区的。于是Facebook又拿了一堆Wedge(这里已经是二代Wedge了,叫做Wedge 100,目标是支持100G的链路,而第一代的算是Wedge 40),同样是二层互联,做了一个叫做Fabric Aggregator的东西。

这样一来,Facebook给大家表演了一个9层Clos,通过 Fabric Aggregator 从一栋建筑物中的机架到另一栋建筑物中的机架的路径最高可达 24 跳。这种把2层Clos构成虚拟机箱的做法确实有一些互联网公司在用。不过AWS、Azure、GCP 三大云厂商通通选择另一种方案:super spine
:将二层Clos作为一个Pod模型,向上再加一层spine交换机。
Super Spine
2015年,Google发表了一篇文章《Jupiter Rising: A Decade of Clos Topologies and Centralized Control in Google's Datacenter Network》介绍了05年-15年,谷歌10年间的五代Clos网络架构。
其中第五代的架构叫做Jupiter Network Fabrics
,可以视为一个三层Clos。leaf交换机还是作为ToR,向北连接到叫做 Middle Block
的spine交换机。Middle Block
和ToR组成一个集群(相当于Facebook的Server Pod
,内部是一个二层Clos),论文上叫做Aggregation Block Superblock
。MiddleBlock
向北还有一层super spine
,论文上叫做Spine Block
。

对比云厂商的Super spine方案和Facebook的虚拟机箱方案,个人感觉由于架构设计的不同,二者扩展的方向会受到限制。虚拟机箱方案需要一开始就对 spine层做好规划,比如Facebook一开始规划了4个spine plane,几轮扩展之后依然是4个spine plane,最多就是plane内的交换机数量有所增加。每次扩展都接入了更多的server pod,但结构上依然存在上限。
Super spine方案则相反super spine的数量可以一直增长,加入更多super spine交换机。但是每个新加入的super spine都要和原有的Pod全互联。从Pod的角度看,每加入一个super spine,Pod就要额外增加连接。为了解决这个问题,Google在spine 层(论文中的spineblock
)和Pod层(论文中的superblock
)之间加入了Apollo Fabric
。Apollo结构解除了spineblock和superblock的直连,但又能够动态地调整spineblock和superblock的连接关系,高效实现了全互联,并且一个额外的好处是能够动态地调整网络流量的分布。
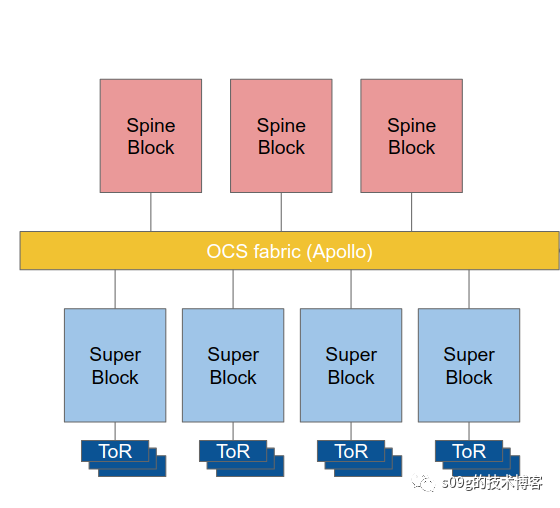
Apollo的本体是一组小镜子,并且接入了SDN,可以通过远程编程来控制。这种设备叫做Optical Circuit Switch (OCS) 光路交换机或者矩阵式光开关交换机。只需要简单地调整镜面的角度,就可以实现新加入的super spine交换机和原有superblock的连接关系。

2022年的ONS峰会上Arista和Intel的发言人都有专门的演讲介绍现在光学器件的进展。
后续
Jupiter 1.0发布之后,Google又陆陆续续升级了Jupiter 2.0, Jupiter X, One Jupiter。尝试了引入更多的光学器件,结构上也验证了一些spine-free方案。到如今也不知道是第几代了,Google很少发布这个方向的论文。但是参考同期Facebook的进度,看来应该是没有获得预期结果。
Facebook在2019年前后又一次达到了结构上的瓶颈。这次终于是做出了重大改动,放弃了原来的虚拟机箱方案。新的minipack方案是单层的ASIC设计,但是性能强的多。新的F16网络下跨建筑物最远只需要8条,内部的跳数也减少了一半。
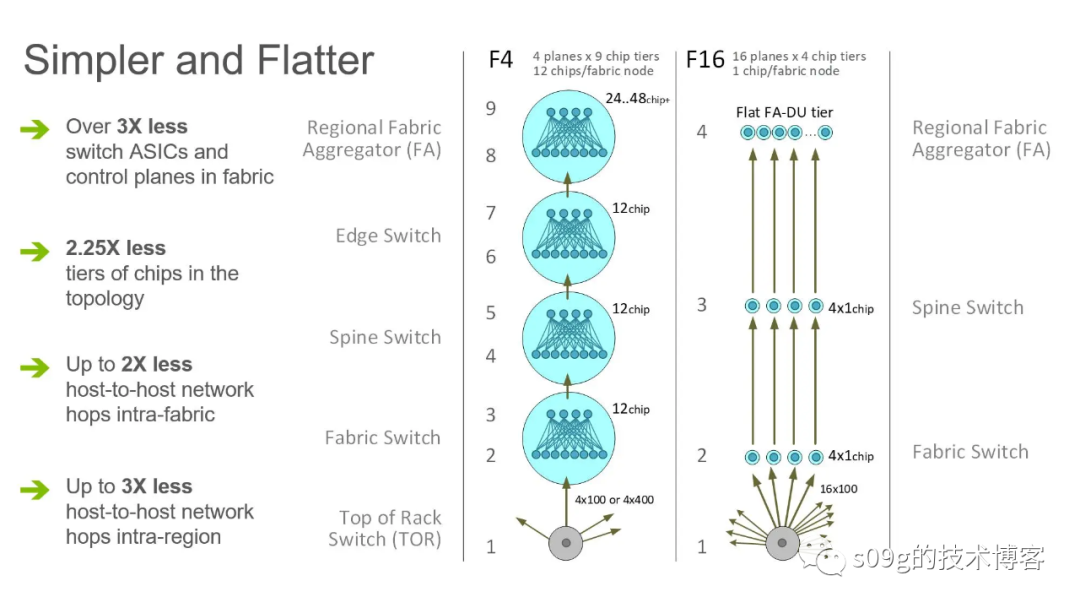
不过Facebook 同样发现非Clos拓扑结构的能耗很大,而光学器件在几年之内都不能满足链路规模的需求。
Acknowledge

本文写作时,加州刚刚进入6月,很多地方长了Foxtail。有一天晚上Yuki的后脚一直在抽搐,仔细检查发现趾缝处在流血。于是我们马上去了医院,傻狗喜提了一千三百刀的急诊手术。接下来的两周都绑着绷带,于是就有了这张穿着鞋子的照片。
