




MRR,全称「Multi-Range Read Optimization」。
简单说:MRR 通过把「随机磁盘读」,转化为「顺序磁盘读」,从而提高了索引查询的性能。
至于:
为什么要把随机读转化为顺序读?
怎么转化的?
为什么顺序读就能提升读取性能?
执行一个范围查询:
mysql > explain select * from stu where age between 10 and 20;+----+-------------+-------+-------+------+---------+------+------+-----------------------+| id | select_type | table | type | key | key_len | ref | rows | Extra |+----+-------------+-------+-------+----------------+------+------+-----------------------+| 1 | SIMPLE | stu | range | age | 5 | NULL | 960 | Using index condition |+----+-------------+-------+-------+----------------+------+------+-----------------------+
-----------------------------------当这个 sql 被执行时,MySQL 会按照下图的方式,去磁盘读取数据(假设数据不在数据缓冲池里):
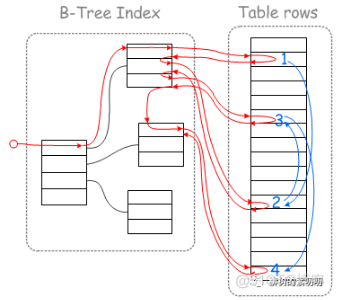
图中红色线就是整个的查询过程,蓝色线则是磁盘的运动路线。
这张图是按照 Myisam 的索引结构画的,不过对于 Innodb 也同样适用。
对于 Myisam,左边就是字段 age 的二级索引,右边是存储完整行数据的地方。
先到左边的二级索引找,找到第一条符合条件的记录(实际上每个节点是一个页,一个页可以有很多条记录,这里我们假设每个页只有一条),接着到右边去读取这条数据的完整记录。
读取完后,回到左边,继续找下一条符合条件的记录,找到后,再到右边读取,这时发现这条数据跟上一条数据,在物理存储位置上,离的贼远!
咋办,没办法,只能让磁盘和磁头一起做机械运动,去给你读取这条数据。
第三条、第四条,都是一样,每次读取数据,磁盘和磁头都得跑好远一段路。
磁盘的简化结构可以看成这样: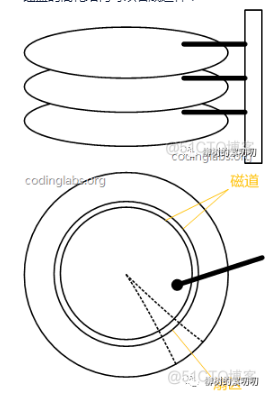
可以想象一下,为了执行你这条 sql 语句,磁盘要不停的旋转,磁头要不停的移动,这些机械运动,都是很费时的。
10,000 RPM(Revolutions Per Minute,即转每分) 的机械硬盘,每秒大概可以执行 167 次磁盘读取,所以在极端情况下,MySQL 每秒只能给你返回 167 条数据,这还不算上 CPU 排队时间。
对于 Innodb,也是一样的。 Innodb 是聚簇索引(cluster index),所以只需要把右边也换成一颗叶子节点带有完整数据的 B+ tree 就可以了。
顺序读:一场狂风暴雨般的革命
到这里你知道了磁盘随机访问是多么奢侈的事了,所以,很明显,要把随机访问转化成顺序访问:
mysql > set optimizer_switch='mrr=on';Query OK, 0 rows affected (0.06 sec)mysql > explain select * from stu where age between 10 and 20;+----+-------------+-------+-------+------+---------+------+------+----------------+| id | select_type | table | type | key | key_len | ref | rows | Extra |+----+-------------+-------+-------+------+---------+---.........
-----------------------------------
