




原文地址:How to benchmark MariaDB/MySQL using Java connector
原文作者:Diego Dupin
对 MariaDB 服务器进行基准测试有多种可能性,其中 sysbench 是常用的一种。由于 sysbench 只能使用 C 连接器,因此通常会忽略另一个连接器对基准测试结果可能产生的任何影响。
我在 MariaDB Corporation 担任 Java、Node.JS 和 R2DBC 的连接器开发人员。编写自己的基准肯定不是最好的解决方案。在某个时候,我决定对允许使用 MariaDB Connector/J 和 MariaDB Server的benchbase框架(以前称为 oltpbench)进行更改。
现在,大约三个月后,我的贡献得到了整合,我决定分享一下如何使用基准框架,以及如何运行微基准来测试或评估 Java 连接器。
基准框架
如前所述,我将使用benchbase框架,该框架允许轻松启动各种数据库的 Java“真实世界”基准测试。
我将使用 2 种不同类型的基准测试(来自 benchbase wiki 的描述):
TPC-C
TPC-C 包含五个不同类型和复杂性的并发事务的混合,要么在线执行,要么排队等待延迟执行。该数据库由九种类型的表组成,具有广泛的记录和人口规模。TPC-C 以每分钟事务数 (tpmC) 衡量。虽然基准描述了批发供应商的活动,但 TPC-C 并不限于任何特定业务部门的活动,而是代表必须管理、销售或分销产品或服务的任何行业。
Twitter
Twitter 工作负载的灵感来自流行的微博网站。为了提供一个现实的基准,我们从 2009 年 8 月获得了 Twitter 社交图谱的匿名快照,其中包含 5100 万用户和近 20 亿个“关注”关系 [14]。我们创建了一个合成工作负载生成器,它基于支持应用程序功能所需的查询/事务的近似值,因为我们通过使用网站观察它们,以及从 200,000 条推文的数据集中获得的信息。尽管我们并不声称这是 Twitter 系统的精确表示,但它仍然反映了它的重要特征,例如严重倾斜的多对多关系。
TPC-C 主要由写入组成,而 Twitter 有更多的读取命令。
安装
使用密码“password”和数据库“benchbase”(默认 benchbase 配置)安装 MariaDB Server 10.6,用户为“admin”。
根据您的服务器内存更改服务器配置以获得稳定的结果(这里是 64G 服务器的配置更改)
最大连接数=500
innodb_buffer_pool_size=50G
thread_handling=线程池
max_heap_table_size=6G
tmp_table_size=6G
innodb_log_file_size=50G
(然后重新启动服务器以使这些更改生效)
Benchbase 需要 Java 17 以及兼容 Java 17 的 maven (>= 3.8)。
克隆基准:
git 克隆 https://github.com/cmu-db/benchbase.git
cd 台架
将 ./pom.xml 中的 mysql/mariadb 驱动程序更新到最新的可用版本。在撰写这篇博文时,它是 MariaDB Connector/J 3.0.3:
<依赖>
<groupId>org.mariadb.jdbc</groupId>
<artifactId>mariadb-java-client</artifactId>
<版本>3.0.3</版本>
</依赖>
然后构建包:
mvn clean package -DskipTests
光盘目标
tar xvzf benchbase-2021-SNAPSHOT.tgz
cd benchbase-2021-SNAPSHOT/
运行基准测试
配置文件在“ config/mariadb/”中。每个配置文件指示连接信息和基准配置。
在 ’ ’ 中使用 mariadb 驱动程序的 TPCC 示例config/mariadb/sample_tpcc_config.xml:
...
<!-- 连接细节-->
<type>MARIADB</type>
<driver>org.mariadb.jdbc.Driver</driver>
<url>jdbc:mariadb://localhost:3306/benchbase?useServerPrepStmts</url>
<用户名>管理员</用户名>
<密码>密码</密码>
<isolation>TRANSACTION_SERIALIZABLE</isolation>
<batchsize>128</batchsize>
<!-- 比例因子是TPCC中的仓库数量-->
<比例因子>1</比例因子>
<!-- 工作量 -->
<终端>1</终端>
<作品>
<工作>
<时间>60</时间>
<rate>10000</rate>
<weights>45,43,4,4,4</weights>
</工作>
</作品>
...
对于此示例,目标将是查看最大吞吐量,将预热时间设置为 60 秒,运行时间为 600 秒。
这是配置文件中的相应更改:
<!-- 比例因子是TPCC中的仓库数量-->
<比例因子>128</比例因子>
<!-- 工作量 -->
<终端>128</终端>
<作品>
<工作>
<warmup>60</warmup>
<时间>600</时间>
<rate>无限制</rate>
<weights>45,43,4,4,4</weights>
</工作>
</作品>
运行:
java -jar benchbase.jar -b tpcc -c config/mariadb/sample_tpcc_config.xml --create=true --load=true --execute=true
基准测试结果将存储在“结果”文件夹中,列出每秒每种事务类型的吞吐量和不同的延迟值。
对于这个特定的最大吞吐量示例,感兴趣的文件是“ tpcc_
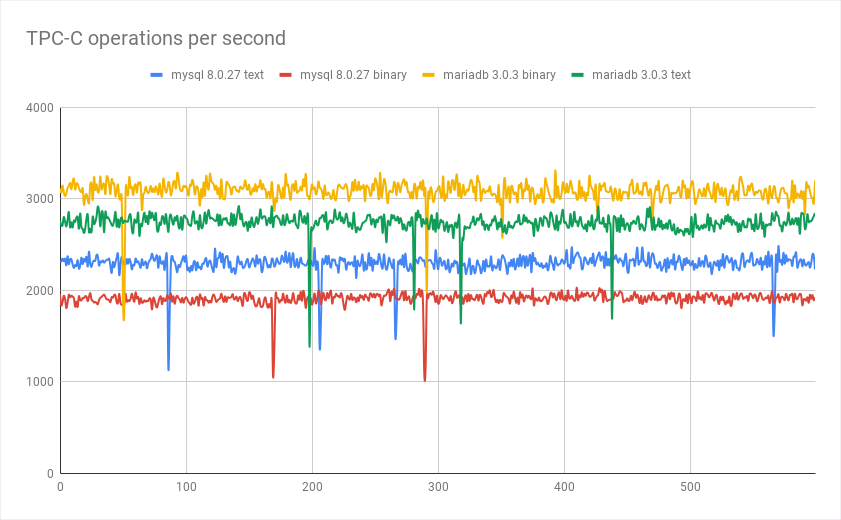
在使用连接字符串“ jdbc:mariadb://localhost:3306/benchbase”和“ jdbc:mariadb://localhost:3306/benchbase?useServerPrepStmts”运行基准测试时,您可以使用二进制协议与文本进行比较:
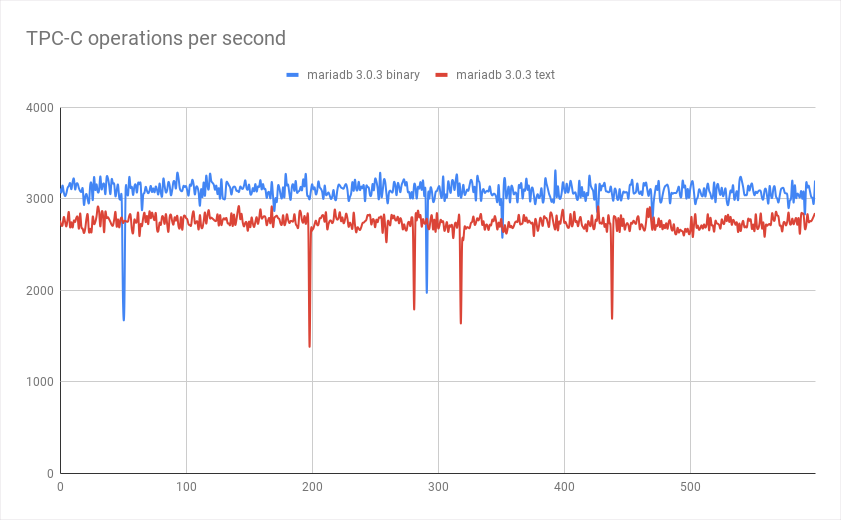
(Down pike 对应于发生死锁的时间)
config/mariadb/sample_twitter_config.xml要运行另一种类型的基准测试,请为 twitter编辑相应的基准测试配置文件“ ”,然后使用命令运行它
java -jar benchbase.jar -b twitter config/mariadb/sample_twitter_config.xml --create=true --load=true --execute=true
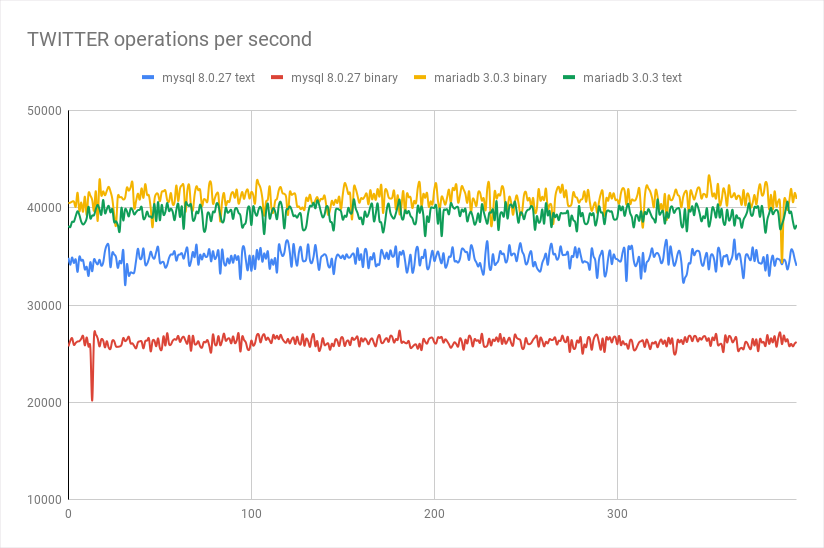
结果:
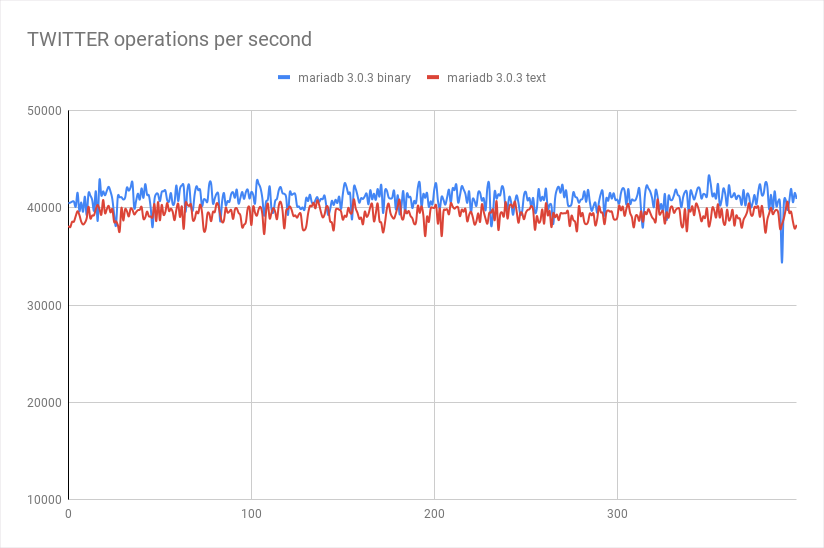
微基准测试
微基准测试不同,您正在测量一小段代码的性能。
OpenJDK JMH 是一个允许微基准测试的 Java 框架,负责处理 JVM 预热和代码优化路径等事情,使微基准测试尽可能简单。
首先需要 JMH 依赖项:
<依赖>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<版本>1.33</版本>
</依赖>
<依赖>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<版本>1.33</版本>
</依赖>
例如,为了测试返回具有不同行数的结果集的命令,我使用了mariadb 序列存储引擎,该引擎允许返回具有不同大小的结果集,使用诸如“select * from seq_1_to_x”之类的命令,X 的值不同
这是一个基准方法:
@基准
公共 int[] testSeq(MyState state) 抛出 SQLException {
int[] 值 = 新的 int[state.size];
诠释 i = 0;
尝试(PreparedStatement prep = state.connection.prepareStatement("select * from seq_1_to_" + state.size)) {
结果集 rs = prep.executeQuery();
而(rs.next()){
值[i++] = rs.getInt(1);
}
}
返回值;
}
假设您要测试“select * from seq_1_to_X”的多个 X 值,这里是完整的基准类内容:
@State(Scope.Benchmark)
@Warmup(迭代次数 = 10,timeUnit = TimeUnit.SECONDS,时间 = 1)
@Measurement(迭代次数 = 10,timeUnit = TimeUnit.SECONDS,时间 = 1)
@Fork(值 = 5)
@Threads(value = -1) // 检测 CPU 计数
@BenchmarkMode(模式。吞吐量)
@OutputTimeUnit(TimeUnit.SECONDS)
公共课 MyBench {
@State(Scope.Thread)
公共静态类 MyState {
私人连接连接;
@Param({"1", "10", "100", "1000", "10000"})
公共整数大小;
@参数({“假”,“真”})
公共字符串二进制;
@Setup(Level.Trial)
public void createConnections() 抛出异常 {
字符串连接String = String.format(
"jdbc:mariadb://localhost/db?user=root&useServerPrepStmts=%s",
二进制);
连接 = DriverManager.getConnection(connectionString);
}
@TearDown(Level.Trial)
公共无效 doTearDown() 抛出 SQLException {
连接.close();
}
}
@基准
公共 int[] testSeq(MyState state) 抛出 SQLException {
诠释 i = 0;
int[] 值 = 新的 int[state.size];
尝试(PreparedStatement prep = state.connection.prepareStatement("select * from seq_1_to_" + state.size)) {
结果集 rs = prep.executeQuery();
而(rs.next()){
值[i++] = rs.getInt(1);
}
}
返回值;
}
}
第一个注释是为 JMH 设置一些基准选项,例如预热时间和基准应该运行多长时间,要使用多少 VM 以及将线程数设置为可用内核数。
每个线程都在使用连接,首先禁用选项“useServerPrepStmts”,然后启用它。
将您的项目打包在一个胖 jar 中(包含所有依赖项)并运行它:
mvn 清洁包
java -Duser.country=US -Duser.language=en -jar target/benchmarks.jar
结果:
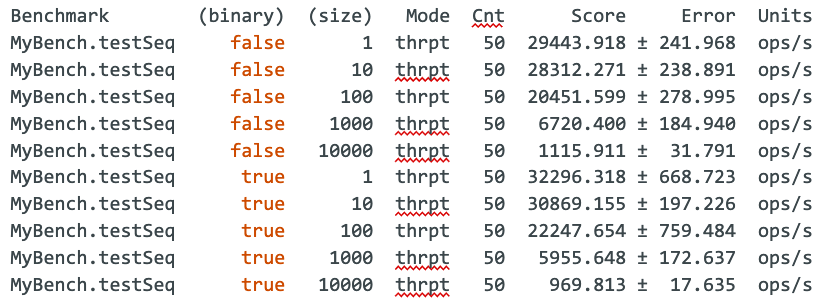
查询“ select * from seq_1_to_1”将返回一行包含一个值 (1)
查询“ select * from seq_1_to_10000”将返回 10000 行,其中包含一个从 1 到 10000 的值。
比较
所以我们已经看到,我们可以使用二进制与文本协议轻松地对连接器选项进行基准测试,例如我们的示例“useServerPrepStmts”。但是,如果我们想将基准测试结果与其他连接器进行比较,我们需要做什么?
mysql 的配置位于“ config/mysql”文件夹中。默认情况下,配置为“ jdbc:mysql://localhost:3306/benchbase”,因此当前使用 MySQL 连接器 8.0.27(2022 年 2 月 1 日)和相同的 MariaDB 数据库。
这里是一个使用 MySQL 连接器和以前的 MariaDB 服务器运行 TPCC 的示例(只需向 mysql 配置报告相同的 TPCC 配置):
java -jar benchbase.jar -b tpcc -c config/mysql/sample_tpcc_config.xml --create=true --load=true --execute=true
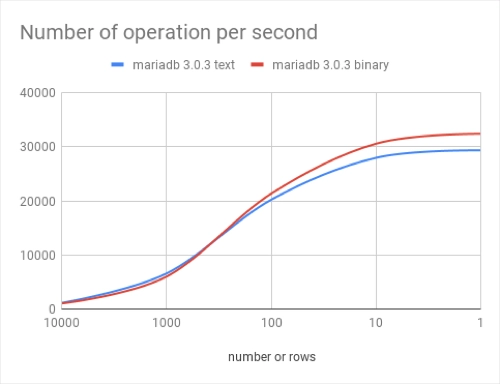
这使我们能够比较我们可以使用的驱动程序:
您想使用微基准比较连接器(使用相同的数据库服务器)吗?这就像使用前面的示例一样简单,只需添加一个 MySQL 驱动程序依赖项并添加所需的参数(添加 sslMode=DISABLED 以获得良好的比较,因为 mysql 默认启用 ssl)
@Param({"mysql", "mariadb"})
公共字符串驱动程序;
@Setup(Level.Trial)
public void createConnections() 抛出异常 {
String connectionString = String.format("jdbc:%s://localhost/db?user=root&sslMode=DISABLED&useServerPrepStmts=%s", driver);
连接 = DriverManager.getConnection(connectionString);
}
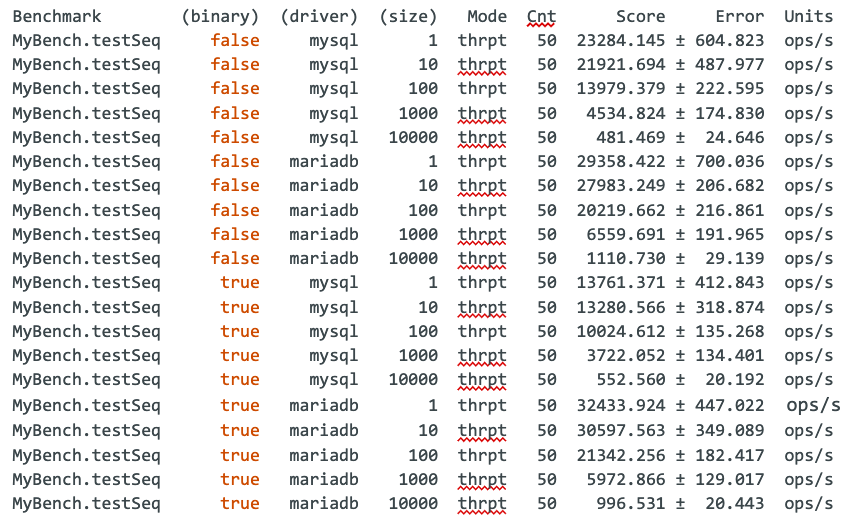
原始结果:
视觉表现:
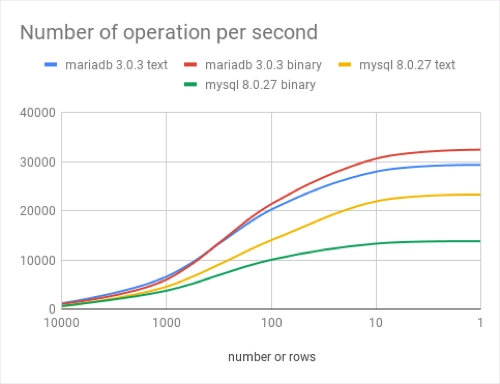
结论
这些数字表明,连接器可能会完全改变基准测试的结果,在同一数据库服务器上运行。因此验证服务器实现很重要,但只有测量完整的堆栈才能让您了解应用程序的执行情况。
