




GBASE南大通用作为国产数据库领军企业,也在跟随国家潮流,积极响应国家政策号召!
随着互联网和“大数据”时代的来领,传统银行如今面临来自其他领域的跨界挑战前所未有。如何转变思维,唤醒沉睡的数据,建立强大稳定的数据分析系统,开发创新数据应用,实现经营转型,是银行业“大数据”时代迫在眉睫的任务。同时,也是农业银行在转变经营思路的过程中,一直思考的问题。
中国农业银行数据仓库项目最初是基于Sybase IQ建设的,主要应用于统计报表。随着数据量的不断增大、接入的系统越来越多,Sybase
IQ由于性能的限制,已经很难在指定的时间窗口中完成数据统计分析工作,也无法继续接入其它的业务系统数据,无法满足银行内部数据分析和监管机构的监管数据要求。系统架构的障碍影响了农行从宝贵的数据资源中挖掘价值,寻找新的、更先进的产品构建核心数据仓库成为农行迫在眉睫的任务。
为了应对上述问题,农行着手构建新型大数据平台时提出了以“数据是基础,治理是保障,技术是支撑,分析是关键,应用是目标”的原则,核心目标是实现数据价值在业务应用中转变为生产力,构建数据价值利用的有效闭环,真正实现从数据支撑到数据运用的转变。在此过程中,需要对数据治理,提高数据质量,从而更好地满足数据挖掘需求,为数据价值在业务中的深入应用夯实基础。
为此,GBASE打造的农行数据仓库架构如下图所示,由数据来源、数据处理层、模型指标层、数据集市层、分析展示层及应用门户层组成。
系统架构图如下:
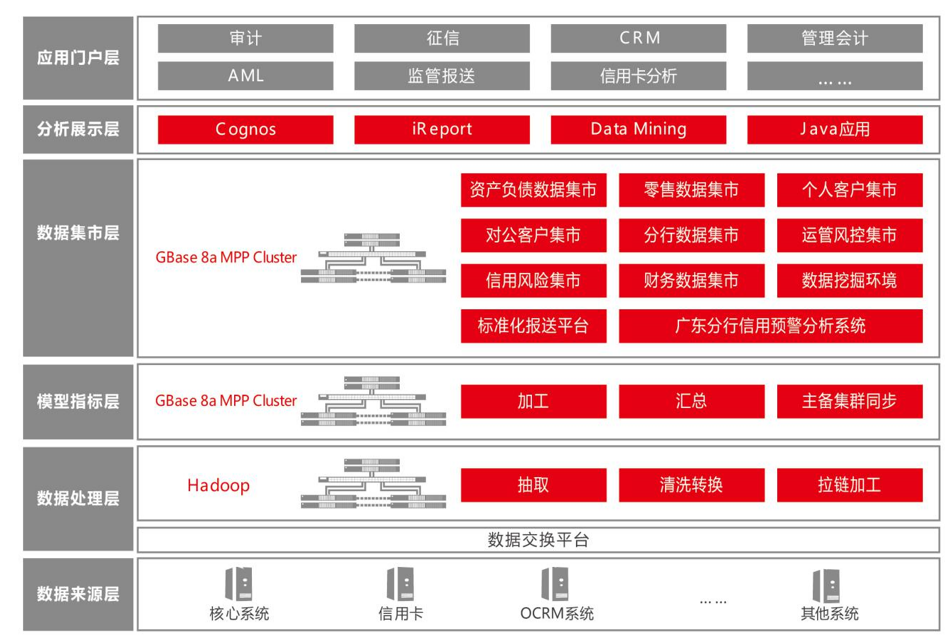
农行数据仓库架构图
数据来源层:最下层为数据来源层,数据来源层包括新一代核心银行系统、综合应用系统、客户管理系统、贷记卡、银行卡、电子银行、反洗钱征信和财务系统等源系统,分别按照一定时间窗口,进行全量/增量数据加载,要求满足需求。目前,数据来源层共计上万张表,最大表超过千亿行。
数据处理层:数据处理层由Hadoop构建,完成对数据的抽取、清晰转换以及拉链表的加工。数据加工完成之后,加载至模型指标层,即农行数据仓库主库。
模型指标层:模型指标层即农行数据仓库,采用GBase 8a MPP Cluster构建。数据仓库的双活系统分为主库和备库两个系统。主库对数据进行批量操作,生成原始数据。备库将主库加工后的数据按照时间机制定时将主库加工的数据以表增量的形式进行更新。备库对数据进行批量更新后后向上层数据集市和应用提供联机查询的服务。
在数据仓库内部,从功能上可以划分为ODS层,BDS层及GDS层三个逻辑层次。ODS(Operational Data Storage)层即为贴源层,用于存放从业务系统直接抽取出来的数据,这些数据从数据结构、数据之间的逻辑关系上都与业务系统基本保持一致。BDS(Base Data Storage)层全称为基础数据层,主要加工任务为在数据库按照对象的需求建模成功之后,对ODS层的数据进行加工和整理。GDS(General Data Storage)即公共数据层,主要目的是为了满足上层应用加工的需求,对BDS层中的数据按照主题或需求进一步进行加工整合,完成轻度数据汇总或宽表加工等任务。
数据集市层:通过使用GBase 8a
MPP Cluster构建了针对上层业务的资负集市、零售集市、个人客户集市、对公客户集市、分行数据集市、运营风控集市、信用风险集市、财务数据集市、广东分行信用预警分析系统以及分析数据集市等各个集市子系统。为了实现数据的高安全和高可用,采用双活集群组成数据仓库。数据仓库主库加工后的数据,通过DBLink方式,由主库传输到集市环境。
分析展示层:使用特定的计算分析引擎,建立数据模型等方法,完成对数据的挖掘和使用。
应用展示层:应用展示对数据进行最终的调取使用,以供服务和业务的展开。
