




概述
2021年07月13日凌晨,某数据库负载同之前相比较高,通过分析主要是由于大量并发insert操作导致undo相关异常等待事件。
问题现象
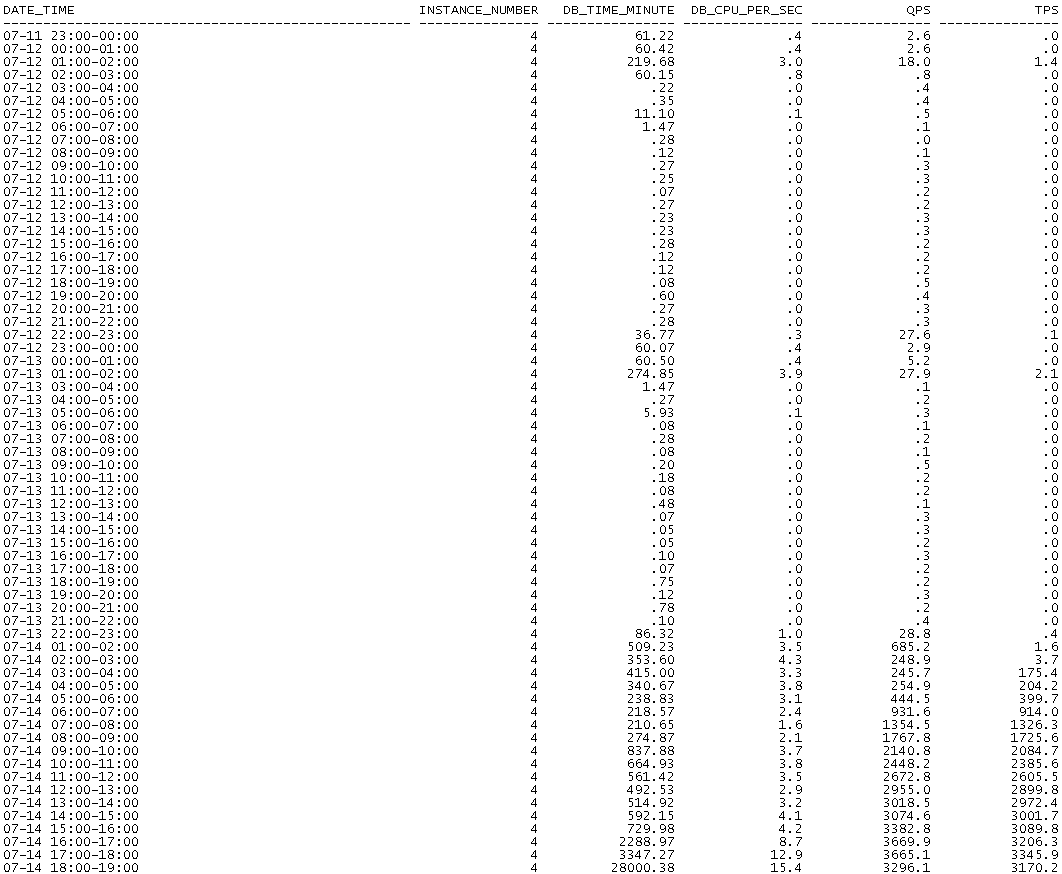
2021年07月14日凌晨开始某库db_time较以往有大幅升高:
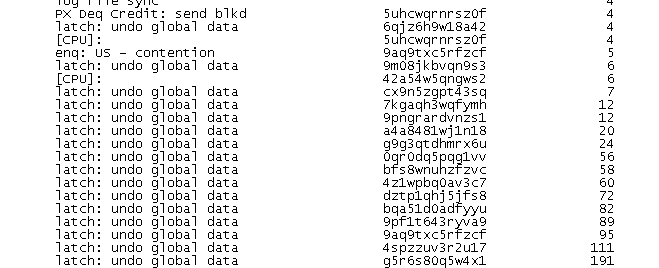
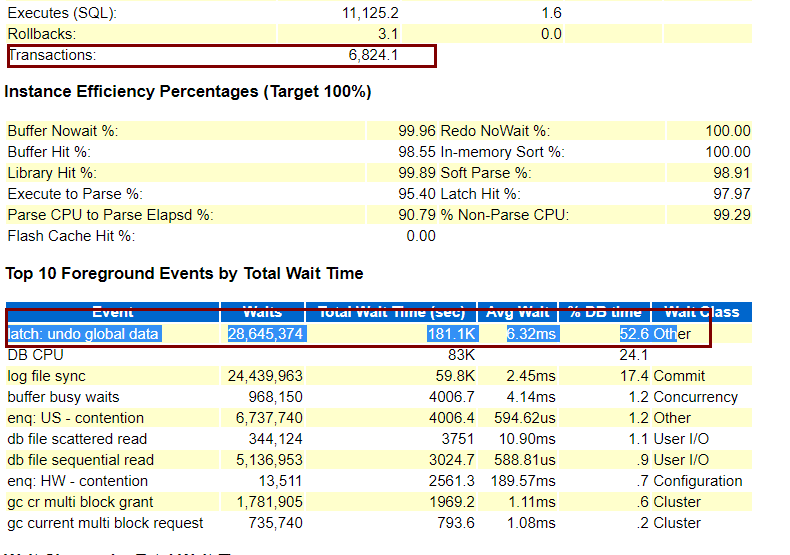
登录数据库核查后发现大量undo相关等待事件:
通过查看awr发现大量insert语句执行:

问题根源
数据库负载升高主要是由于14号凌晨insert SQL相关业务量升高导致。
问题分析
负载趋势分析
通过核查tps和qps情况发现,14号凌晨开始数据库db_time、db_cpu、tps 、qps均大幅升高。所以负载升高主要还是由于数据库繁忙导致。(tps、qps越高数据库相对越繁忙)
13号和16号Awr top sql对比:
13号awr top sql
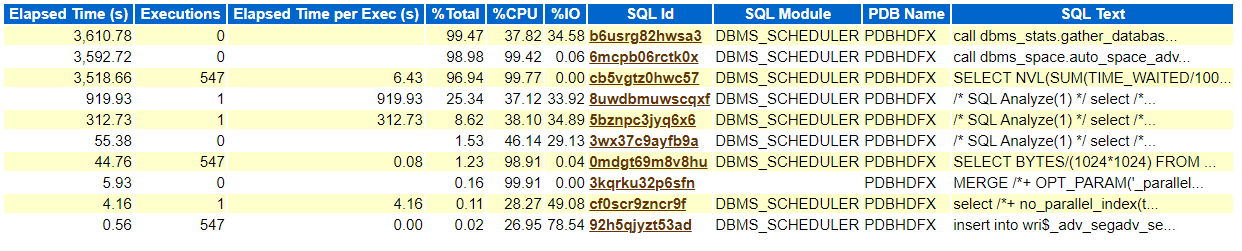
16号awr top sql:

Undo表空间大小以及相关参数
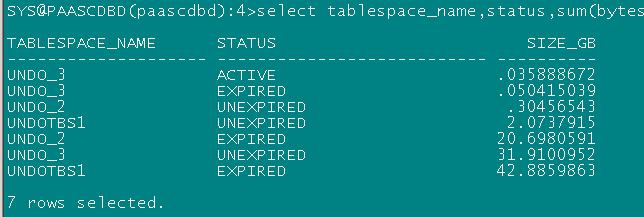
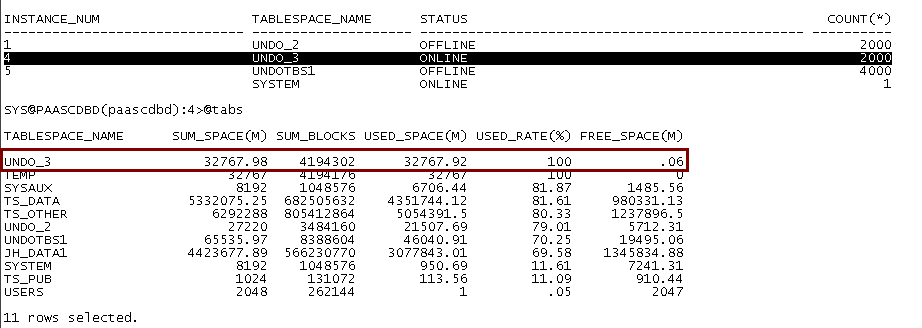
通过核查发现数据库4节点undo表空间(undo_3)大小为32G:
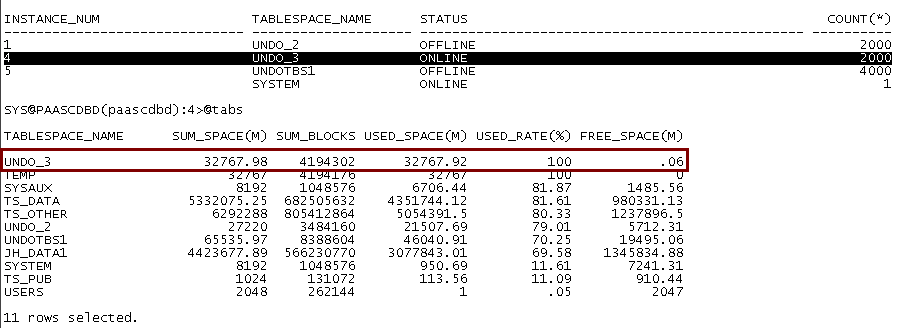
Undo_retention参数当前为10800属于正常范围,由于_undo_autotune 为false 数据库将优先保证10800秒内的一致性查询。


通过核查undo_3过期的undo空间有0.5G,未过期的undo表空间有31.9G, 由于过期的undo比率较小,而且参数_undo_autotune 为false数据库优先保证未过期的undo不被覆盖,导致数据库不得不花费了较长事件寻找过期的undo和将部分已过期的undo设置为过期状态的时间较长。
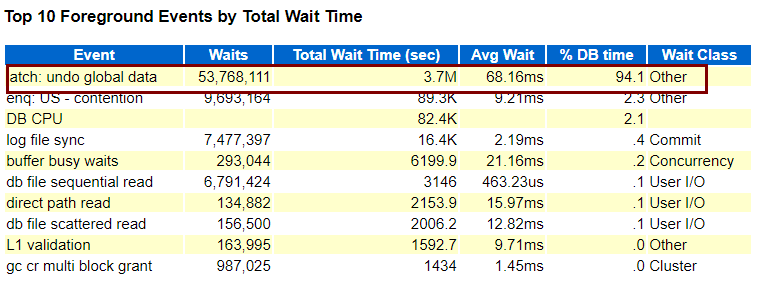
数据库等待事件
数据库主要等待事件为: latch: undo global data 该等待事件主要是会话努力寻找新undo段,并且不得不窃取未过期的undo段,而且由于业务时段内insert sql频繁执行并且未过期的undo块越来越少加剧了undo争用。
问题处置
19号下午18点对undo_3添加了30G undo表空间后,latch: undo global data 等待事件消除
问题处置后数据库运行情况观察
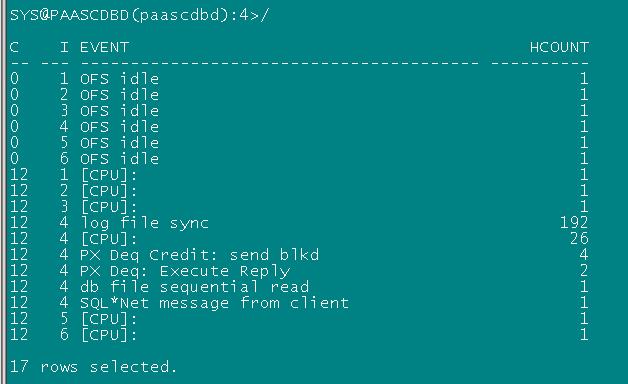
20日凌晨0点-1点由于数据库效率较之前提高,事务量也大幅提升,仍存在一定量的latch: undo global data等待,
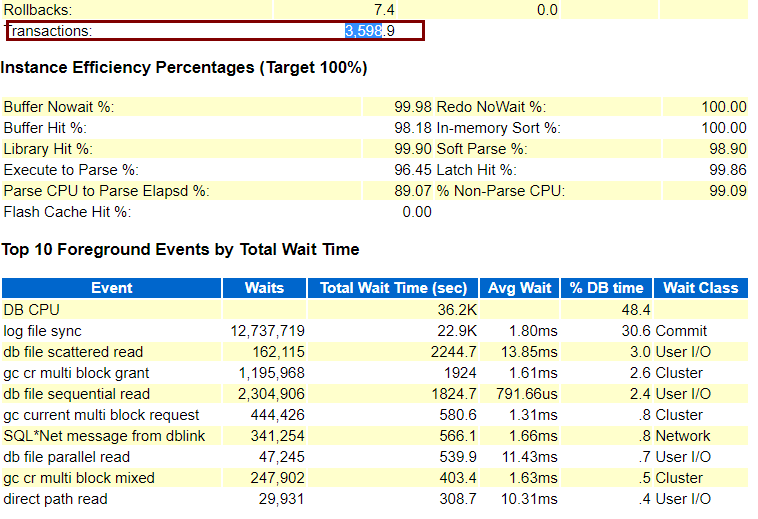
20日8点到9点随着事务量下降数据库latch: undo global data等待事件已经消失,但是存在部分log file sync等待:
20日凌晨0点-1点awr事务量和等待事件情况:
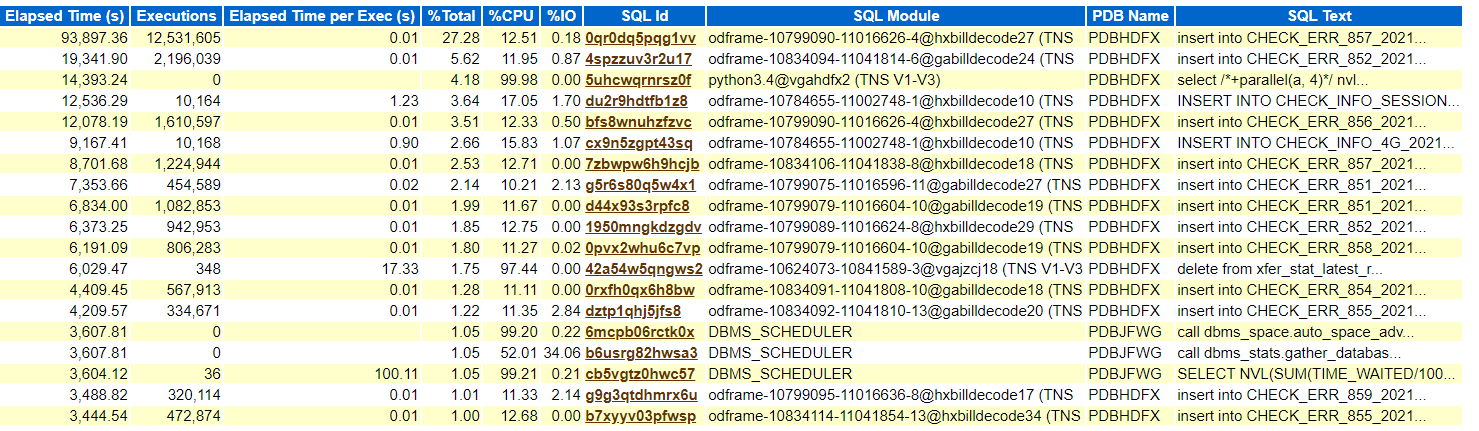
20日凌晨0点-1点TOP SQL:
20日凌晨8点-9点awr事务量和等待事件情况:
20日凌晨8点-9点TOP SQL:

解决方案及建议
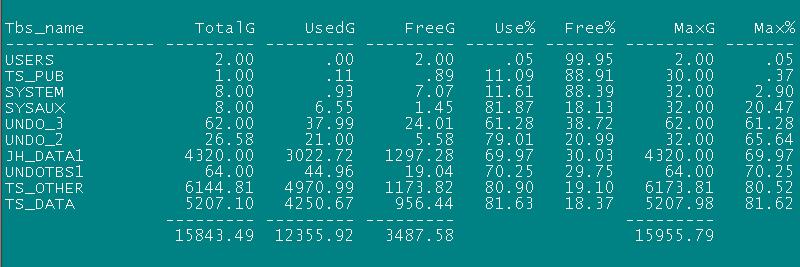
建议1:调大4节点undo表空间,从之前的32G调整到62G(已经实施)。
建议2:由于insert操作频繁,建议应用使用批量插入、批量提交的方式;
建议3:由于备节点(1节点)undo表空间undo_2 仅有27G 建议也进行扩大到60g左右
建议4:
- 通过设置 _UNDO_AUTOTUNE 实例参数来启用撤消自动调整
官方参考文档:Doc ID 1451536.1
