




01 前言
近年来,随着互联网技术的发展,数据早已成为各行业的生命源泉,数据管理的重要性不言而喻。日前,在「巨杉最具价值专家」技术交流会中,北京傲飞商智软件有限公司CEO初建军老师( jianjunchu@apache.org)对Apache Hop基于web的可视化流式批处理平台主题进行了详细的讲解。
02 什么是Apache Hop
Apache Hop是Hop Orchestration Platform的缩写。它完全用Java编写,旨在提供广泛的数据编排工具,包括可视化开发环境,服务器,元数据分析,审计服务等。作为一个平台,Hop还希望成为一个可重复使用的库,以便可以被其他软件轻松地重复使用。
Hop起源于Kettle, Kettle 作为一款国外开源的 ETL 工具,抽取数据高效稳定,在执行ETL工具、ETL数据抽取转换等批任务时,使用频率较高。近几年,国内包括电信、金融、银行在内的各行业都使用 Kettle 作为数据处理工具。但是由于各种因素,Kettle近几年的发展还是较为缓慢,为了改变现况,从今年2月份开始,Kettle 社区在Kettle 8.2的基础上建立了一个分支,Hop就是从这个分支建立的新项目,2020年9月份,Hop正式加入Apache,成为Apache的孵化项目。
03 Hop与Kettle的区别
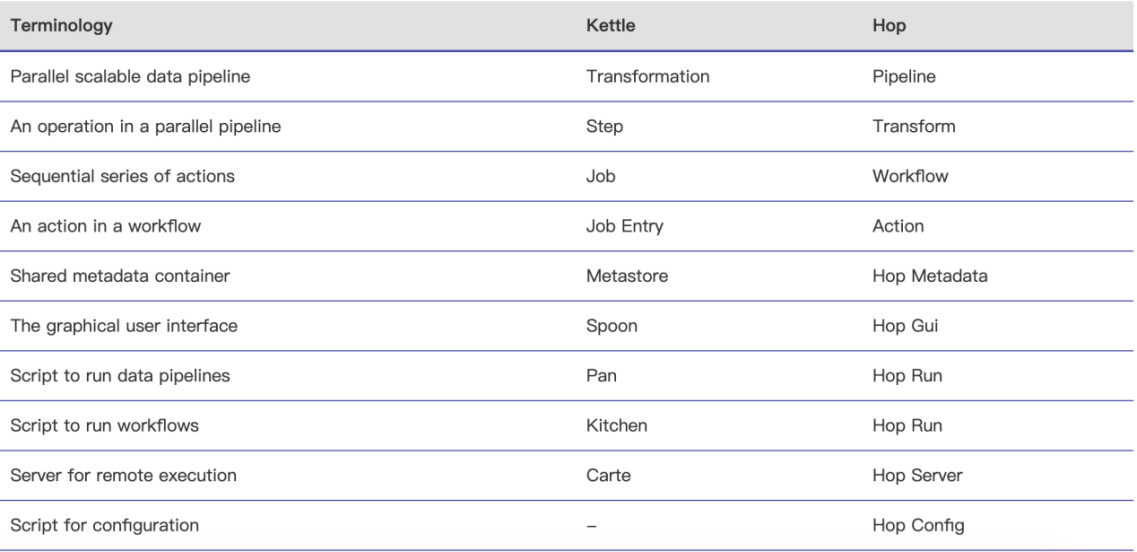
由于Hop源于Kettle,所以Hop的概念与Kettle十分相似。Kettle中的转换、步骤、作业、作业项等在Hop里面都有相对应的名称,如下表所示,转换在Hop中对应的是pipeline,pipeline起源于Apache的beam,Hop和beam结合较为紧密,甚至可以理解为Hop就是beam的一个界面工具。下表为Hop 和 Kettle 的命名区别:
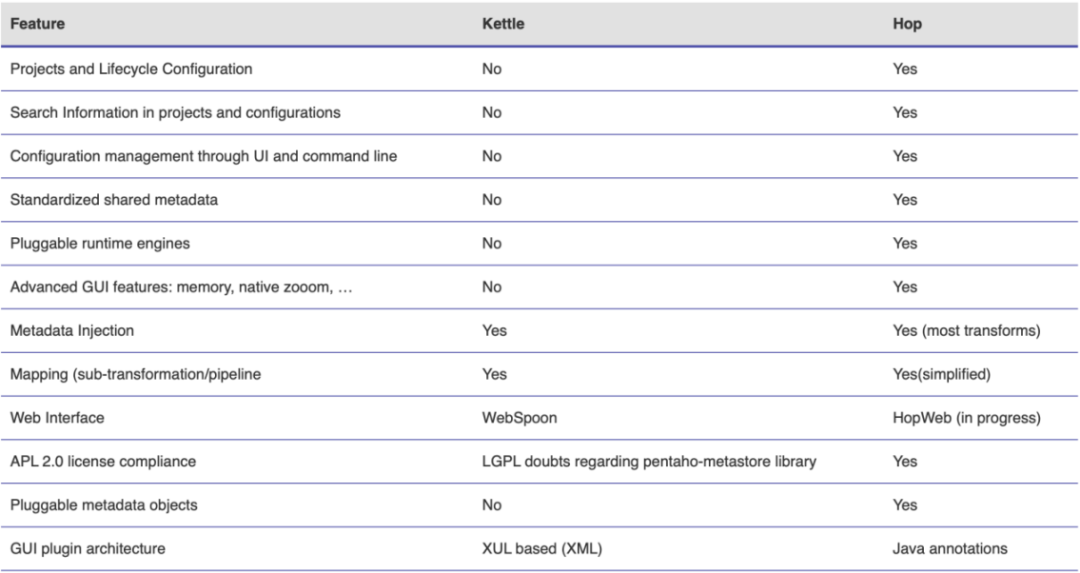
Hop 和 Kettle 的功能区别如下表,在功能上,因为Kettle对项目配置的管理还有待加强,它只能设计和执行作业、转换工作,却不能组织作业、转换并按照项目进行划分。另外 Kettle对于生命周期的管理也有待提升,它缺失了ETL作业从开发环境到测试环境再到生产环境中不同配置文件的搭配。而Hop则在这些方面更加系统化、工程化,在Hop中,可以通过创建工程,从而在工程里可以设计作业、转换以及配置对应的周期和环境。除此之外,Hop也增加了对ETL元数据的管理,Hop可以抽取出每一个转换或者步骤的元数据,从而实现设计和执行引擎的分离。其中的原理是Hop使用Apach Beam提供的统一开发模型,利用Beam将Hop 设计的pipelines发布到Kettle本地引擎或发布到 Spark、Flink等流处理引擎上执行。
另外Hop 提供了WebSpoon 设计端,可以在Web 上设计ETL 流程。
04 Hop的发展现况与目标
目前,Hop项目已开发到0.3版本,基本上已属于可执行状态,只是距离实际运用还有一些距离,插件的开发、代码测试、文档等工作还在不断优化中。
Hop项目的近期目标是开发更多的插件、转移SWT项目至WebSpoon、进行测试、变量和参数的管理等。Hop增加对 Git的支持,过去Kettle 的作业和转换皆存储在数据库资源库或文件资源库中,而Hop则不再打算使用这个方式,转而用git版本控制系统来管理转换和作业文件,便于作业的版本管理。
Hop 项目的地址如下,欢迎关注Hop 项目的发展,并提出您的意见。
https://github.com/apache/incubator-hop
