




Table of Contents
一. 分类
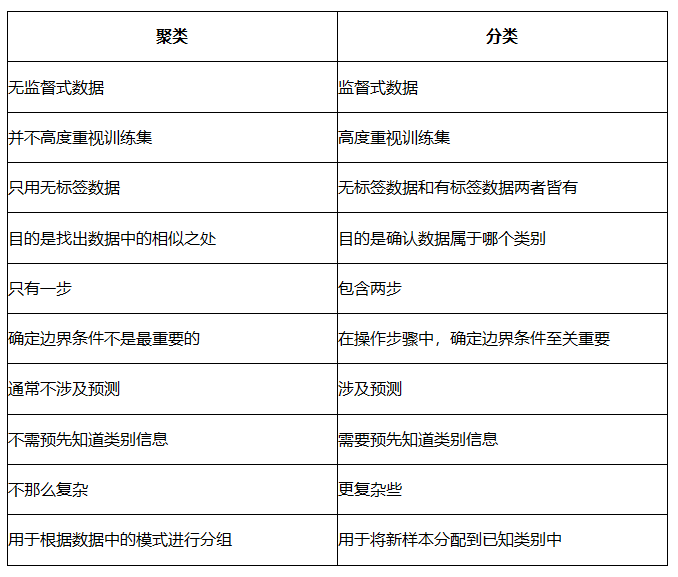
1.1 分类的意义
- 传统意义下的分类: 生物物种
- 预测: 天气预报
- 决策: yes or no
1.2 分类与聚类的差别
图片来源:
https://www.zhihu.com/question/42044303/answer/470589507
1.3 分类和聚类常用的算法
分类算法:
- K近邻(KNN)
- 逻辑回归
- 支持向量机
- 朴素贝叶斯
- 决策树
- 随机森林
聚类算法 :
- K均值(K-means)
- FCM(模糊C均值聚类)
- 均值漂移聚类
- DBSCAN
- DPEAK
- Mediods
- Canopy
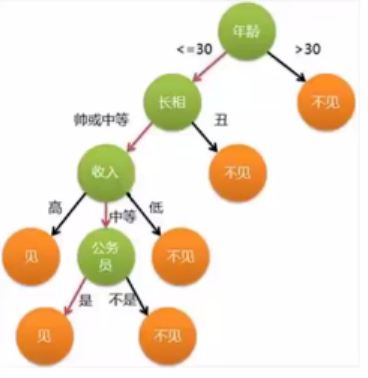
1.4 线性判别法的例子
以天气预报为例。
代码:
G=c(1,1,1,1,1,1,1,1,1,1,2,2,2,2,2,2,2,2,2,2)
x1=c(-1.9,-6.9,5.2,5.0,7.3,6.8,0.9,-12.5,1.5,3.8,0.2,-0.1,0,2.7,2.1,-4.6,-1.7,-2.6,2.6,-2.8)
x2=c(3.2,0.4,2.0,2.5,0.0,12.7,-5.4,-2.5,1.3,6.8,6.2,7.5,14.6,8.3,0.8,4.3,10.9,13.1,12.8,10.0)
a=data.frame(G,x1,x2)
plot(x1,x2)
text(x1,x2,G,adj=-0.5)
测试记录:
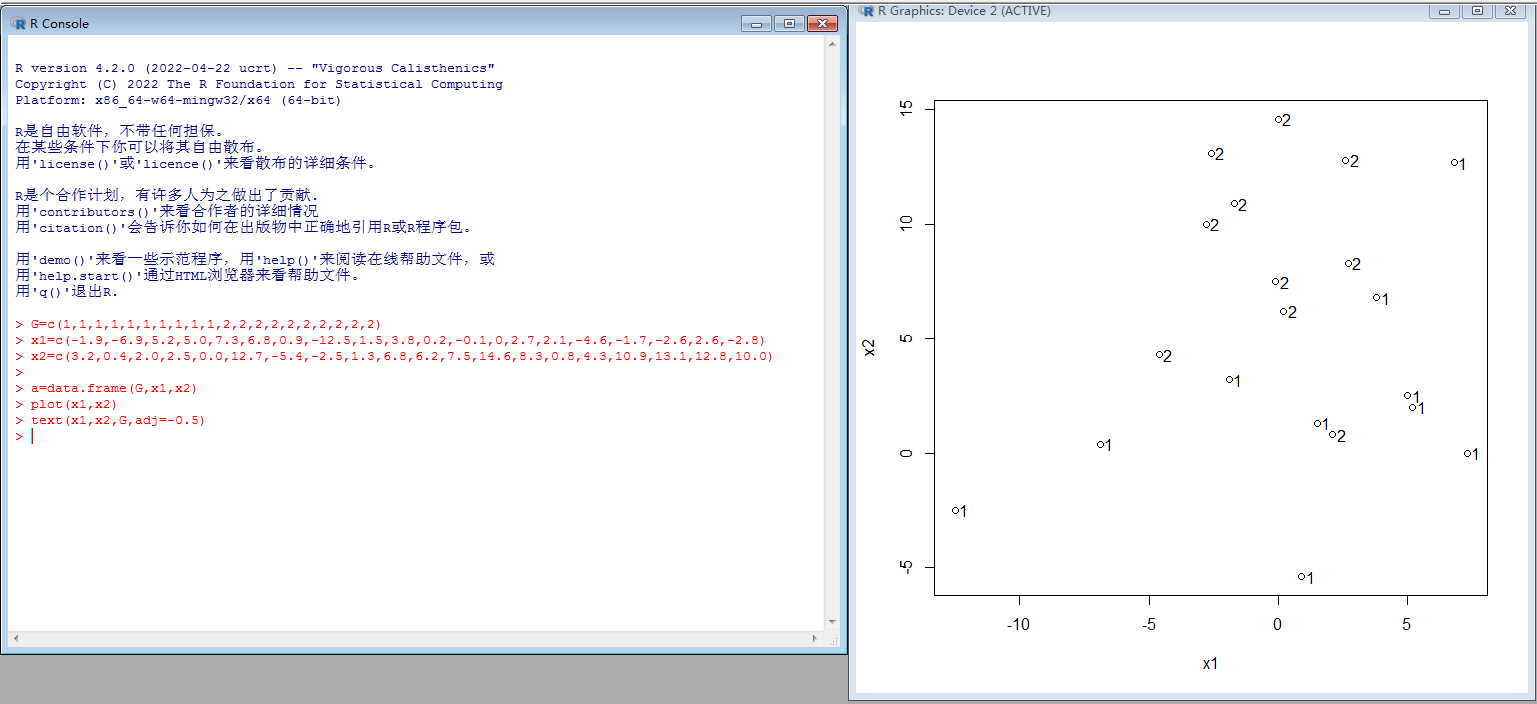
用一条直线来划分训练集(这条直线一定存在吗?)
然后根据待测点在直线的哪一边决定它的分类
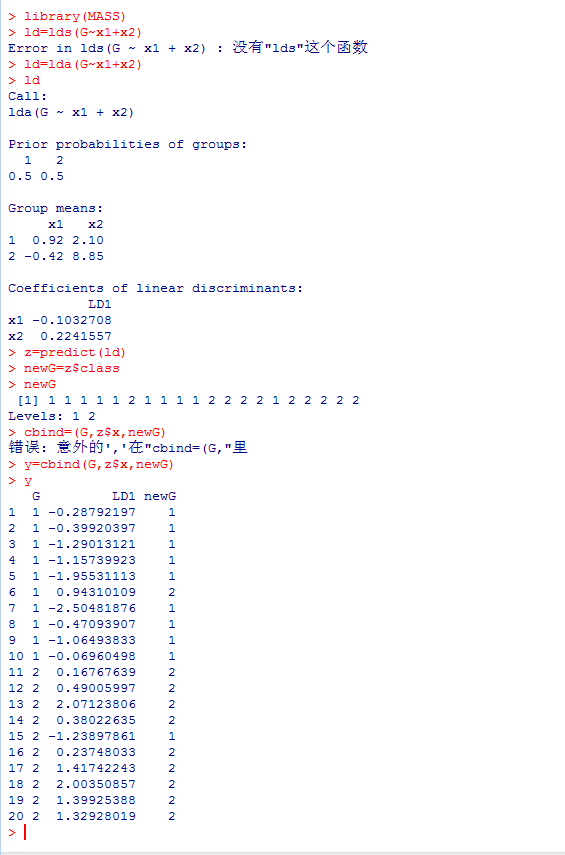
代码:
library(MASS)
ld=lda(G~x1+x2)
ld
z=predict(ld)
newG=z$class
newG
y=cbind(G,z$x,newG)
y
二. 文本挖掘典型场景
2.1 网页自动分类

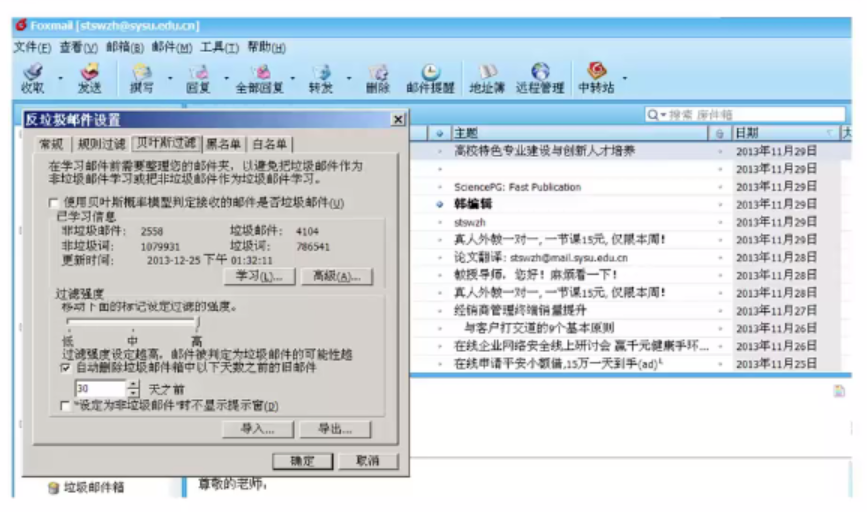
2.2 垃圾邮件判断
朴素贝叶斯分类器,使用的最频繁
先分词,然后判定垃圾邮件
朴素贝叶斯分类 变量彼此之间没有联系,互不影响
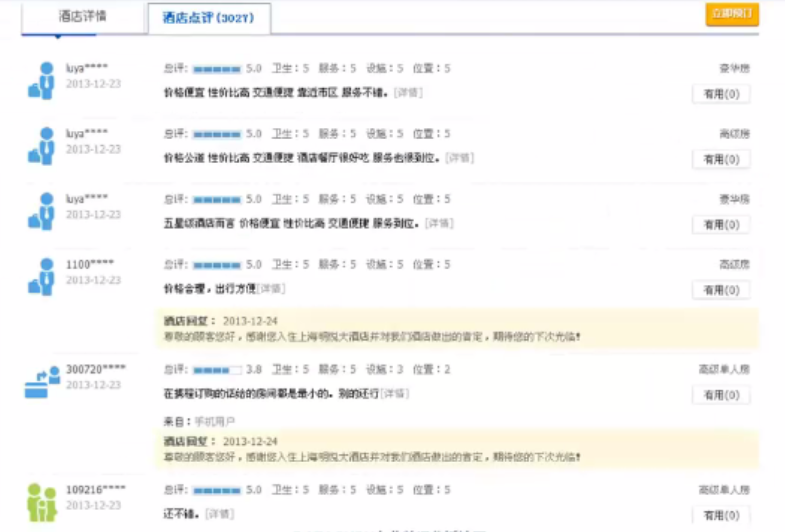
2.3 评论自动分析
2.4 通过用户访问内容判别用户喜好
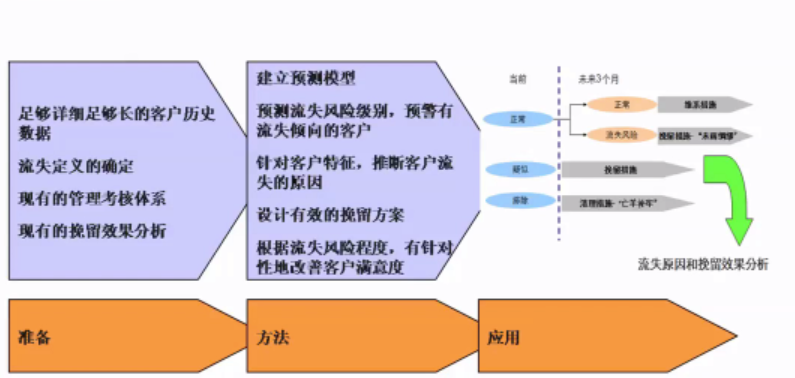
用户流失预警:
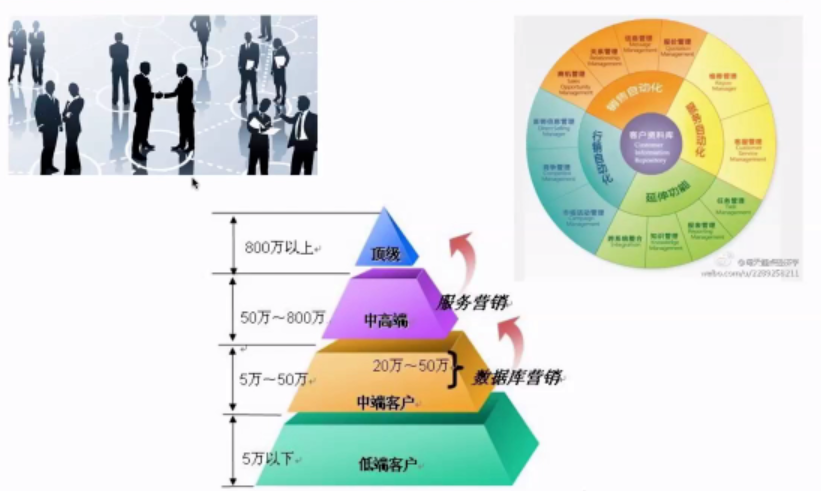
用户标签系统:
三. 贝叶斯信念网络
贝叶斯信念网络 区别于 朴素贝叶斯,各个变量之间存在某种关联关系,这种情况其实更贴合实际应用场景。

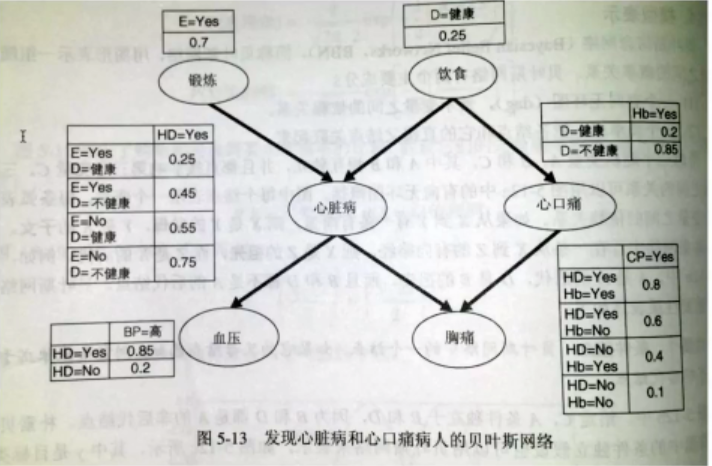

贝叶斯推理:


「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
