




原文地址:REPLACING NODES IN CASSANDRA
原文作者: Mario Tavares
Cassandra的众多优点之一是在集群中添加、删除甚至替换节点的操作非常简单。
替换 Cassandra 中的节点就像设置配置文件以匹配旧节点一样简单(特定于服务器的设置除外,例如 listen_address 和rpc_address) 并将以下行添加到 cassandra-env.sh:
JVM_OPTS= "$JVM_OPTS -Dcassandra.replace_address=<address_of_replaced_node>"
在新节点上启动 Cassandra 后,它会在开始替换之前执行几个步骤,此时它会继承被替换节点拥有的令牌范围,并从现有副本中为每个令牌范围流式传输数据。引导过程完成后,您必须删除我们附加到cassandra-env.sh文件的替换行,这就是它 - 节点替换。
同时添加 (使用auto_bootstrap)并且删除节点不会对数据一致性产生任何影响,替换节点会引入一些变量,使其在幕后对一致性的影响更加细微。
常见问题
在继续讨论一致性位之前,我将解决执行节点替换时要记住的一些事项以及如何解决常见的障碍。首先,替换节点的cassandra.yaml文件中有两个条件需要验证:
- 新节点不是种子。
- 你已经设置
auto_bootstrap: true- 这是默认值。
如果两者都不满足,您将在引导期间在system.log中遇到此错误:
Replacing a node without bootstrapping risks invalidating consistency guarantees as the expected data may not be present until repair is run.
(在没有引导的情况下替换节点可能会使一致性保证失效,因为在运行修复之前可能不存在预期的数据。)
替换种子节点
更换种子节点?没问题。在这种情况下,您应该提升同一数据中心中的另一个节点以在所有节点的cassandra.yaml上,但在替换完成之前不要重新启动集群中的节点——这将导致替换无法通过在宕机节点丢失。发生这种情况是因为gossip信息无法完全重新启动。
节点信息不在gossip中
如果您遇到替换失败的情况,并且您在替换节点system.log 中看到以下错误:
Cannot replace_address /127.0.0.1 because it doesn't exist in gossip
很可能节点已经重新启动,并且丢失了要替换的节点上的gossip信息。在这种情况下,最好的过程是通过在任何活动节点上运行来从集群中删除宕机的节点:
nodetool removenode < old_node_ID >
然后,引导替换节点,就像扩展集群一样——没有替换标志。在开始添加节点之前,请确保旧节点已从集群上的 gossip 中删除。您可以通过在每个活动节点上运行来检查它:
nodetool status | grep <old_node_ID>
通过此检查,我们要么不希望得到任何结果,要么希望看到状态为“down and leave”(DL)的节点。在集群中的所有节点上看到不一致的gossip信息并不少见——这是gossip协议分散性质的结果。如果大约两分钟之后没有达成共识,您可以在尚未将旧节点识别为退役或 DL 的节点上重新启动Cassandra 。在某些情况下,这可能不足以从环中删除节点。当这种情况发生时,我们可以资源到最后和最不优雅节点工具nodetool 从集群中删除节点的选项:
nodetool assassinate <old_node_IP_address>
但是,我不能轻易推荐此选项。建议在考虑nodetool assassinate节点工具前,让 gossip 在运行nodetool removenode后的 72 小时内就移除达成集群共识。如果您确实需要运行 ‘assassinate’,请进行修复以允许将数据流式传输到新副本。
节点仍被识别为自举
尝试替换节点时您可能会遇到的system.log中的另一个常见错误是:
Cannot replace address with a node that is already bootstrapped
如果您看到以上提示,以下是阻止替换的主要因素:
- 具有替换地址的节点已在集群中启动并运行。
- 替换节点在其数据目录和/或提交日志目录中有数据。
- 替换节点正在运行不同的Cassandra版本。
集群扩展的数据一致性
当您将节点添加到现有集群时,token分配将不可避免地在节点之间重新排列。更准确地说,这意味着新节点将负责的所有数据都将从集群中的其他现有副本传递。新节点完成引导后,旧副本仍将拥有数据,但不再为该数据的读取请求提供服务。从存储中删除这些数据是我们在扩展后对集群运行清理的原因。为了确保一致性,引导程序上的新节点将从将失去其所有权的确切副本中流式传输数据。
退役节点时也适用相同的原则。当您停用一个节点时,它会将其拥有的所有数据流式传输到未来的副本。当节点完成退役时,新副本不仅会接管节点的token范围,还会接管其数据,这意味着该过程不会丢失任何数据。
节点替换的一致性成本是多少?
与添加和删除节点不同,替换不能确保数据从我们要替换的节点流出。除非我们能以某种方式从宕机的节点恢复 sstable,否则无法直接继承数据,因为我们要替换的节点必须在被替换之前关闭。
在节点替换期间,Cassandra 为每个被继承的token范围选择一个副本,以将数据流式传输到替换节点。
该系统在一致性方面引入了两个缺点:
- 数据不会从失去所有权的节点流出。这意味着有可能丢失数据。这将发生在被替换的副本是任何给定行或列的唯一具有更新值的副本的任何情况下。
- 流是从每个分区的单个副本完成的。这并不理想,因为无法保证流式传输数据的副本将具有最新值。为了最大化一致性,从所有(复制因子 -1)现有副本流式传输每个分区或对继承令牌范围内的数据执行一致性检查是有意义的。
减轻这些缺点的最实用方法是利用反熵修复:
- 经常运行反熵修复以避免在需要更换节点时丢失数据。
- 替换节点完成引导后立即执行反熵修复,作为让所有副本拥有已替换令牌范围上的更新数据的方法。
即使我们遵循这两个准则,也有一段时间替换节点正在处理具有可能不一致数据的请求:
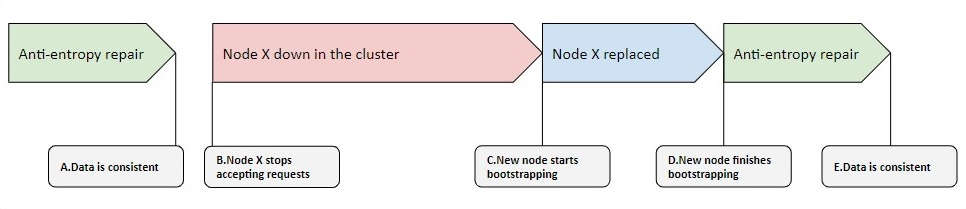
在 D 的更换完成和 E 的维修结束之间,有一段时间会出现数据不一致的仲裁回复的风险增加。遇到这些请求的风险与 A 和 B 之间的时间段长短有关。
值得庆幸的是,有几种方法可以解决这种可能性。
- 使用cassandra.yaml标志启动替换节点
start_native_transport:false这会导致节点无法为请求提供服务,除非您另有决定。使用这种方法,您可以将标志更改回 true 并在 E 处的反熵修复完成后重新启动节点。 - 遵循与步骤 1 相同的过程,但在引导期间跳过流式处理阶段,让修复处理流式传输一致的数据。这在通过节省一些流式传输开销来预测数据不一致的情况下是有意义的。
如前所述,您无法在没有的情况下替换节点auto_bootstrap: true这个标志定义了在引导过程中流是否参与。
但是有一个解决方法是将此标志添加到文件cassandra-env.sh:
JVM_OPTS="$JVM_OPTS -Dcassandra.allow_unsafe_replace=true”
这不是我们通常推荐的做法,因为它可能会使用户在节点替换期间面临不必要的风险,即:将可服务节点引导到没有数据的环,或者更糟糕的是——将节点替换为种子,这将导致token在没有先同步数据的情况下响铃(即使是维修也无法拯救我们)。
引入不安全的替换
以下矩阵解释了用标志allow_unsafe_replace与auto_bootstrap替换节点之间的交互
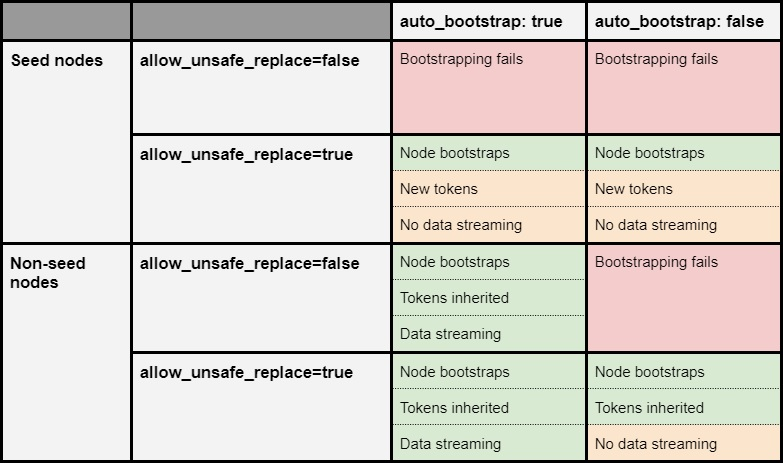
如您所见,标志allow_unsafe_replace 完全符合我们对其名称的期望。它允许您在通常由于 Cassandra 中的安全检查失败而无法替换的情况下替换节点。
但是,在另一种情况下,您可以使用此标志对我们有利:当替换节点具有来自替换节点的部分或全部数据时。当您在每个主机的多个磁盘上跨越数据并遇到磁盘故障时,这很常见。
在这种情况下,您可以更换节点并跳过自动引导过程。尽管如此,您必须按照此替换进行修复以恢复任何丢失的数据,并且该过程必须满足三个条件:
- 该节点不能是其自身列表中的种子节点。
- 清除替换主机上的系统密钥空间目录。
- 自被替换节点宕机以来的时间必须小于
gc_grace_seconds在任何表格中。默认情况下为 10 天。
您不希望节点成为种子,因为在引导时节点会重新生成令牌范围,从而有效地失去您尝试恢复的数据的所有权,同时也不会为它接管的令牌流式传输数据。
在这种情况下清除系统密钥空间是无害的,因为节点将在替换期间再次填充它。
最后,在Cassandra中,您永远不想在之后带回数据gc_grace_seconds已经过去,有恢复已删除数据的风险。这个过程通常被称为僵尸数据——这里有一篇文章可以更好地解释整个交易。
TLDR
节点替换不能像调试或停用集群中的节点那样确保一致性。
运行频繁的维修可以降低一致性成本。
有一些解决方法可以保证强一致性,但最终您总是会在节点替换时丢失数据,除非您可以从替换的主机物理检索它——通过恢复或在使用时持久化数据 allow_unsafe_replace 对你有利。
我希望你觉得这篇文章有帮助。
