




译者简介
李伟&崔鹏&海能达DBA团队,任职于海能达通信股份有限公司哈尔滨平台中心,数据库开发高级工程师,致力于PostgreSQL数据库在专网通信领域、公共安全领域PostgreSQL数据库的管理与维护,致力于高并发高可用数据库架构设计和数据库性能的优化。
校对者简介
赵全明 任职于华为技术有限公司,数据库内核开发工程师,参与RDS for PostgreSQL管控及GaussDB多个版本的研发,致力于PostgreSQL在全行业的应用与推广。
提升备用服务器
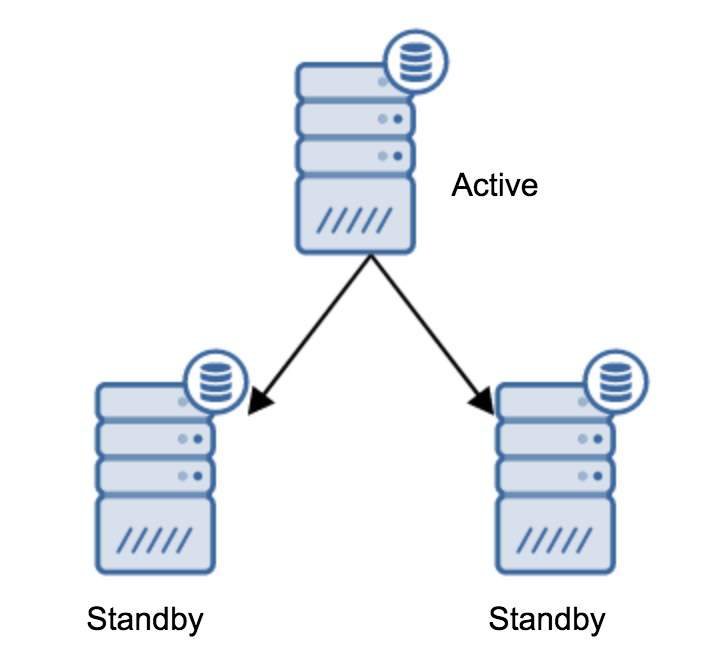
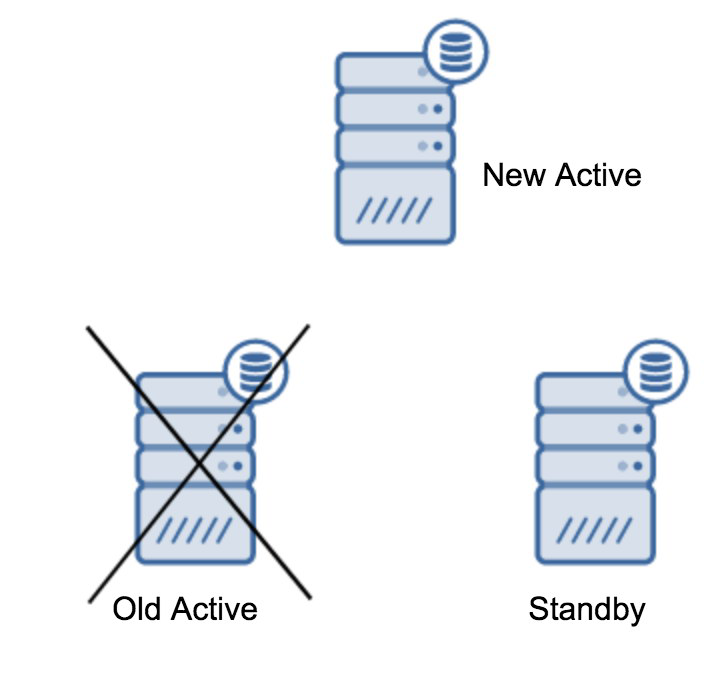
postgres@vagrant-ubuntu-trusty-64:~$ usr/lib/postgresql/10/bin/pg_ctl promote -D var/lib/postgresql/10/main/waiting for server to promote.... doneserver promoted
postgres=# select pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn();pg_last_wal_receive_lsn | pg_last_wal_replay_lsn-------------------------+------------------------1/AA2D2B08 | 1/AA2D2B08(1 row)
将备用服务器挂到新的主服务器上
postgres@vagrant-ubuntu-trusty-64:~$ usr/lib/postgresql/10/bin/pg_rewind --source-server="user=myuser dbname=postgres host=10.0.0.103" --target-pgdata=/var/lib/postgresql/10/main --dry-runservers diverged at WAL location 1/AA4F1160 on timeline 3rewinding from last common checkpoint at 1/AA4F10F0 on timeline 3Done!
standby_mode = 'on'primary_conninfo = 'application_name=pgsql_node_0 host=10.0.0.103 port=5432 user=replication_user password=replication_password'recovery_target_timeline = 'latest'trigger_file = '/tmp/failover.trigger'
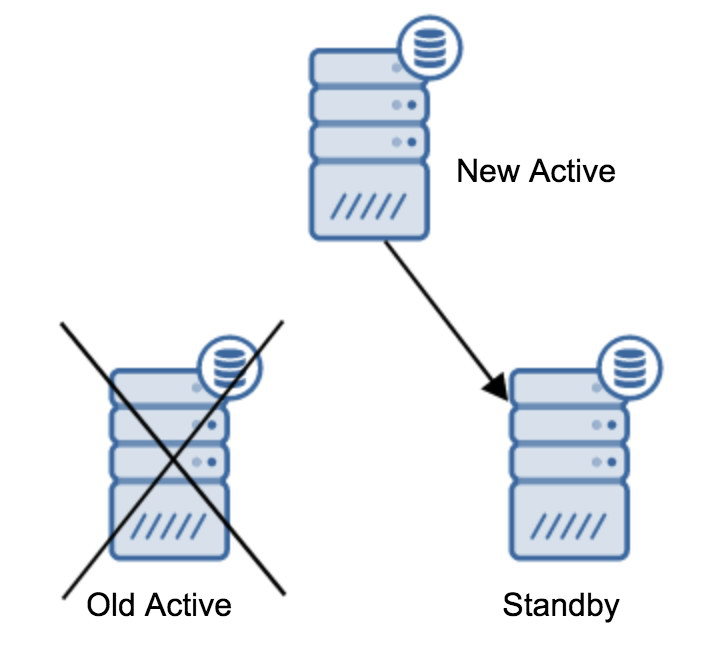
链式复制
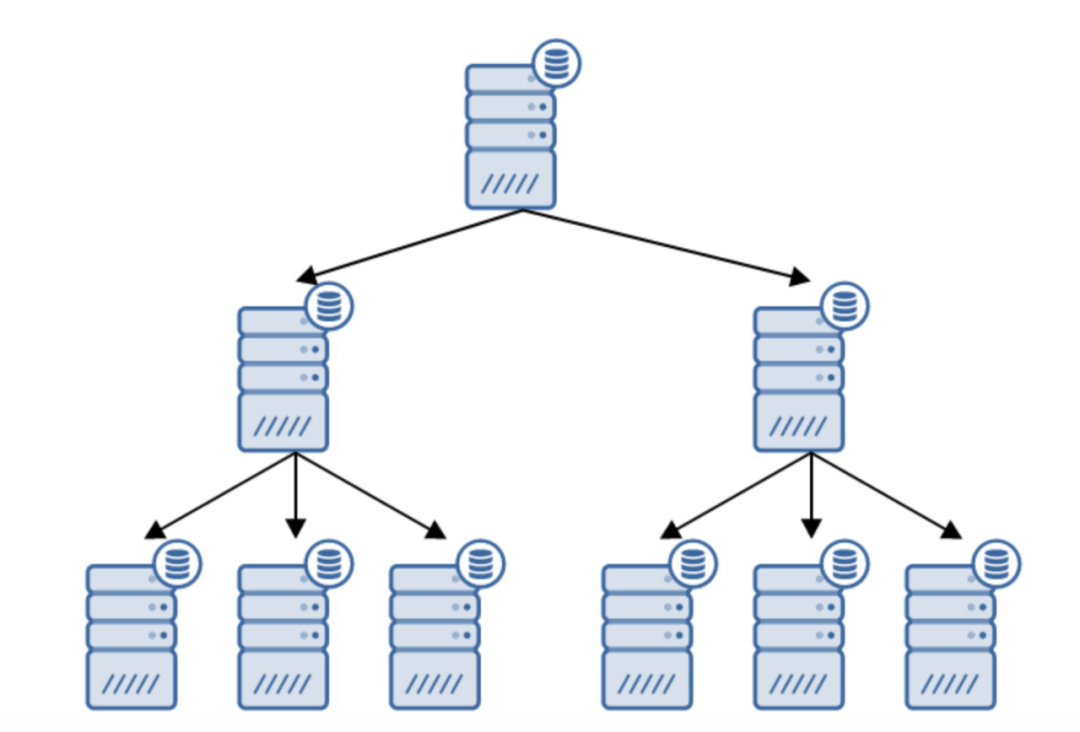
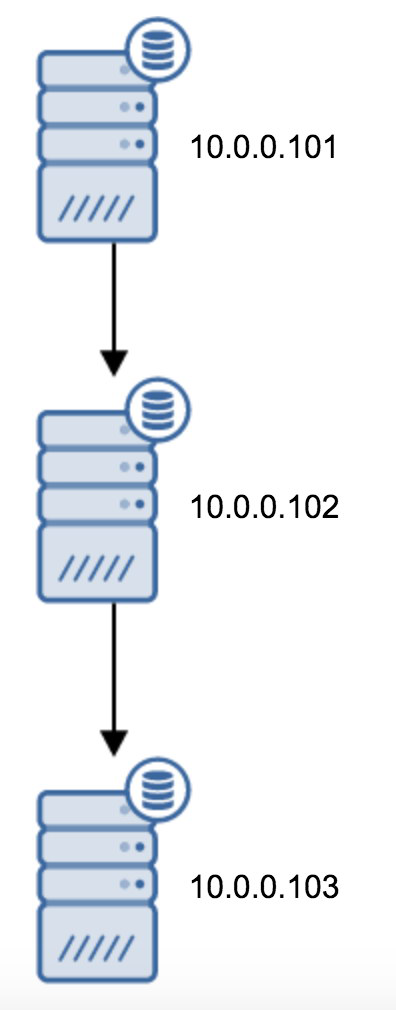
standby_mode = 'on'primary_conninfo = 'application_name=pgsql_node_0 host=10.0.0.102 port=5432 user=replication_user password=replication_password'recovery_target_timeline = 'latest'trigger_file = '/tmp/failover.trigger'

文章转载自PostgreSQL中文社区,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
