




在上一周,现代数据技术栈中的超级独角兽Databricks举办了Data+AI Summit。这个Summit包括线下和线上虚拟的部分,一共四天的时间。除了东道主Databricks,在这个峰会中我们还看到了来自Google, Microsoft,Apple,Netflix等巨头企业的分享。当然,dbt labs, Airbyte,Hightouth等现代数据技术栈企业也在大会上有自己的发言。另外,我们还看到了来自中国的字节跳动团队的分享。
几天热闹的大会对于广大数据技术圈的爱好者来讲是个技术的盛宴,我们可以了解在大洋彼岸的各个公司如何利用数据技术在各自的领域去发挥价值。但是对于Databricks来讲,最重要的就是宣布自己的数据湖仓存储Delta Lake 2.0开源并变为Linux基金会的一个项目。
那么Delta Lake到底是个什么样的技术?为什么Databricks对Delta Lake 2.0开源这事儿看得这么重要呢?
这里我先来介绍一下Databricks这家公司的历史,然后再展开进行Delta Lake相关的介绍。
Databricks是由名校伯克利的amplab孵化出来的一家大数据技术公司。在国内大数据圈赫赫有名的Spark就是成就Databricks这家公司的最早的产品。
Amplab是伯克利大学为了面向大规模数据分析和处理而成立的一个5年期的实验室。A代表Algorithms, M代表Machines, P代表People。实验室2011年成立,注明教授迈克尔乔丹(不是球星乔丹)作为实验室的联合负责人。但是实验室2008年就开始发表大数据相关的一些论文。在2009年,Matei在读博士期间就开始进行并行数据处理的研究,并把自己的研究命名为Spark。在2010年,Spark以BSD授权的方式进行了开源。在2012年,Matei作为第一作者发表了Spark相关的论文《Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing》,这篇论文获得了NSDI的最佳论文奖。伴随着这篇论文,Spark的核心思想也逐渐成熟。在2013年Spark捐献给了Apache基金会,并且在2014年变为了Apache的顶级项目。
大约在2013年前后,国内采用大数据的企业大部分都还是使用Hadoop的MR架构进行数据的计算和处理。但是Hadoop的MR面临的性能差,容错不好的问题也都被大家所诟病。而这个时候,Spark的出现让大家看到了新的可能。于是国内一些尝鲜者就开始尝试用Spark解决自己公司数据加工性能的问题。笔者当时在上家企业也正带领数据团队面临同样的问题,因此在2014年开始将Spark引入到我们公司的数据部门,并最终在生产中彻底替换了Hadoop的MR。
全球用户对Spark的大规模的采纳,也促进了Spark的飞速发展。Spark逐渐成为了Apache的明星项目。在2013年,amplab基于开源Spark成立了Databricks公司,开始探索Spark的商业化。伴随着Spark在大数据圈的火爆,Databricks公司的融资也非常的顺利,一路成长为到今天估值超过300亿美金的超级独角兽。
伴随着Spark被更多的企业采纳,Databricks也在持续地围绕数据进行新能力的构建。在2018年前后,全球人工智能和机器学习异常火热,Databricks顺势推出机器学习平台MLflow。
不过人工智能和机器学习虽然火热,但是真正的使用场景中,显然数据分析的需求更普遍和强烈。同样在大数据领域的Snowflake在数据仓库方面已经逐渐地变成了很多企业用户的选择。Databricks显然也不想错过这个场景,因此在2019年推出了面向数据湖仓的开源存储项目Delta Lake。
Delta Lake是什么?


那么Delta Lake是什么?Databricks为什么会开发Delta Lake呢?
首先,Delta Lake是一种存储结构的设计,是在对象存储上设计的支持类似于数据库表的ACID能力的高性能的存储设计。做过技术的同学都知道传统的数据库表最核心的是要保证数据库事务的一致性。而ACID则是数据库操作中事务一致性保证的几个特性,分别是:Atomicity-原子性,Consistency-一致性,Isolation-隔离性,Durability-持久性。在传统数据库设计中,一般会通过事务日志等等来设计实现。
但是对于大数据场景,很多企业都采用廉价的对象存储来存储自己来自于不同系统的数据,通常我们把这些存储来自于不同系统的大规模数据的对象存储叫做数据湖(Data Lake)。但是对象存储的数据访问一般是通过键值对来进行索引和访问的。 用对象存储来进行大规模数据保存价格低廉,方便整块的数据的存取。但是,对于数据的更新、删除等等操作,却非常对困难,很难保证很高的性能和一致性。这种对象存储结构,对于一般的日志类型的存储,因为都是追加方式,相对比较友好。但是如果企业把业务系统的数据库数据也要同步到对象存储,就存在很多问题。因为数据库的数据一般会存在删除、修改等等等需求,这些数据变化如何高效的在对象存储中体现并能快速被使用,就需要在对象存储上实现类似于传统数据库的ACID的能力。
Delta Lake就是针对这种场景进行设计实现的存储结构。下图是Delta Lake论文中传统的数据存储模型和使用Delta Lake的模型:
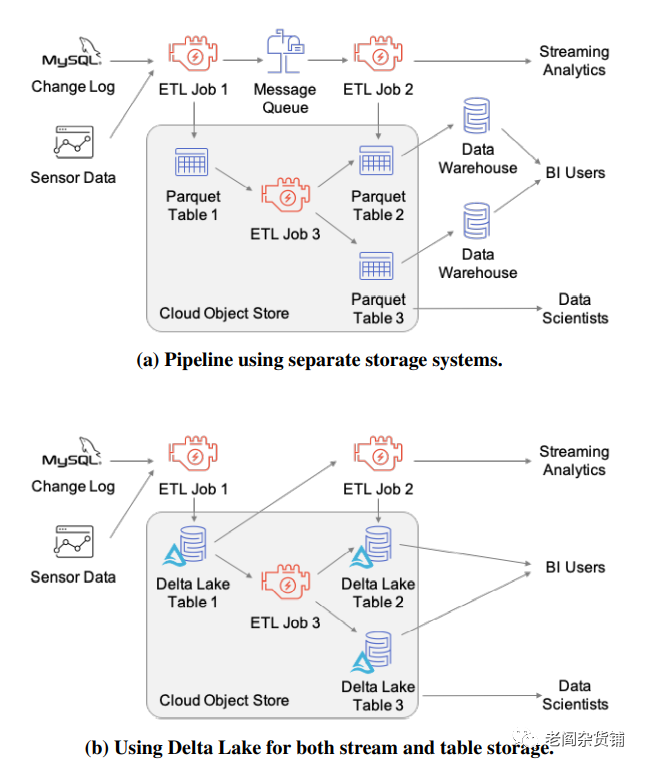
从技术上来讲, Delta Lake底层采用的是parquet存储结构,但是通过write-ahead log来存储数据的更新变化,另外增加了高性能的元数据的管理来保证数据更新和查询的性能。更多的技术细节,本文不过多地进行阐述,有兴趣的朋友可以去查阅论文《Delta Lake: High-Performance ACID Table Storage over Cloud Object Stores》
有了Delta Lake, Databricks提出了新的Lakehouse的概念,也就是现在比较火热的数据湖仓。关于数据湖仓,比较直观的可以参看下图:
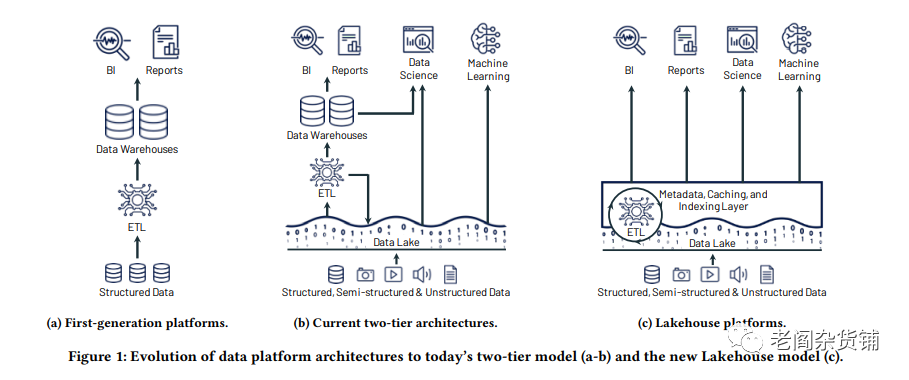
Lakehouse的核心理念是把数据湖和数据仓库合而为一,从数据湖清洗过的数据继续存放在数据湖的廉价存储中,从而能够不用两个分别的存储来存储原始数据和被处理过的数据。
Databricks为啥重点宣布Delta Lake 2.0开源?
Databricks在2019年开源了Delta Lake,但是很多用户却发现Delta Lake的开源版本实际上是Databricks的阉割版本。很多高级的特性在开源版本中并没有包含,想使用只能购买Datebricks运营的云版本。无疑这是一个很成功的商业策略,从Databricks每年的高速的收入增长就能可见一斑。
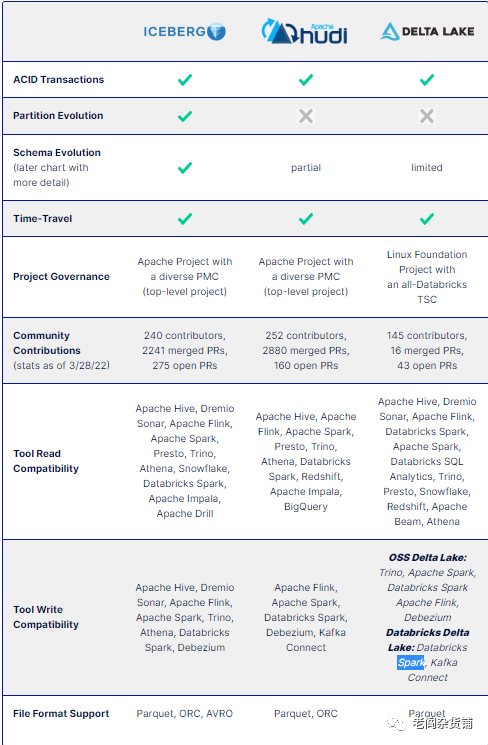
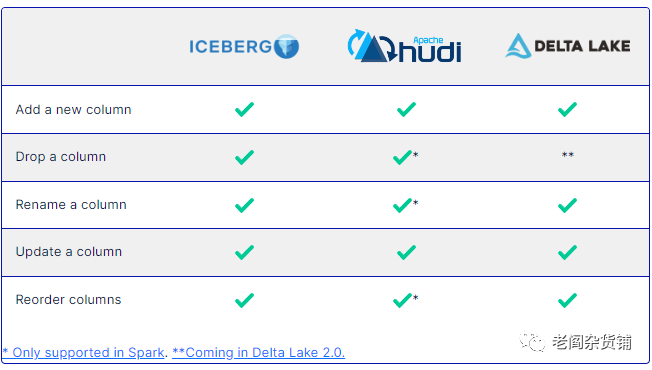
不过显然这个市场不乏竞争,随着数据湖仓的兴起,必然有其他的竞争对手参与。在开源数据湖仓的市场,除了Delta Lake,还有Iceberge和Hudi这两个Apache基金组织的两个顶级项目。而Snowflake, Dremio, Google Cloud, HPE等公司也批评Databricks开源的Delta Lake诚意不足,不是真正意义的开源。Dremio在自己的文章中对Iceberg, Hudi, Delta Lake的产品做了一个对比,如下图:
下图:
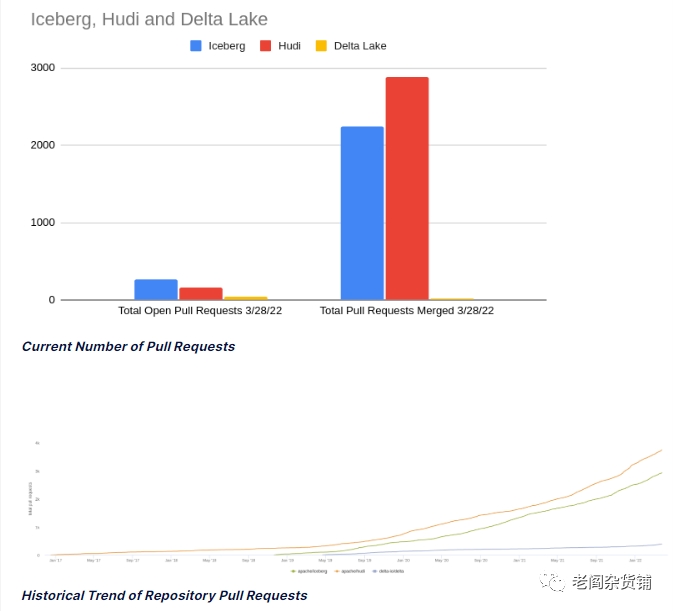
贡献者占比:
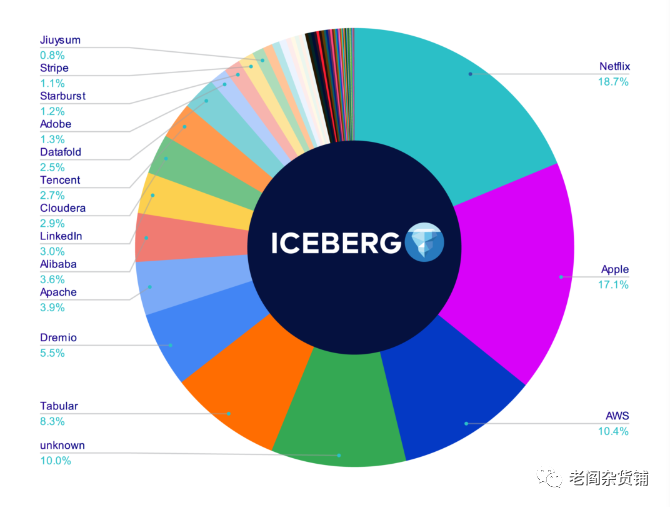
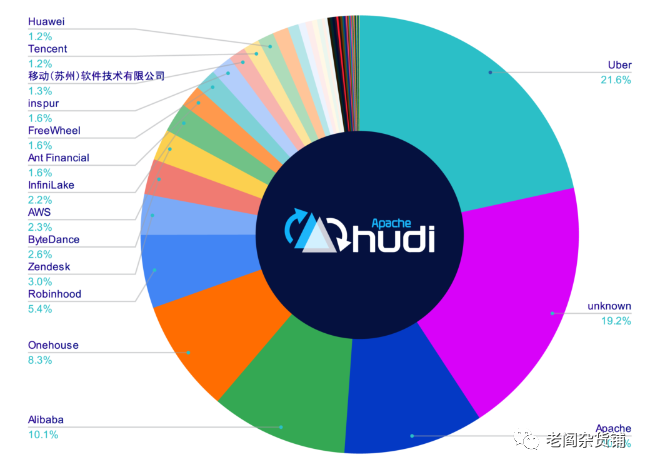
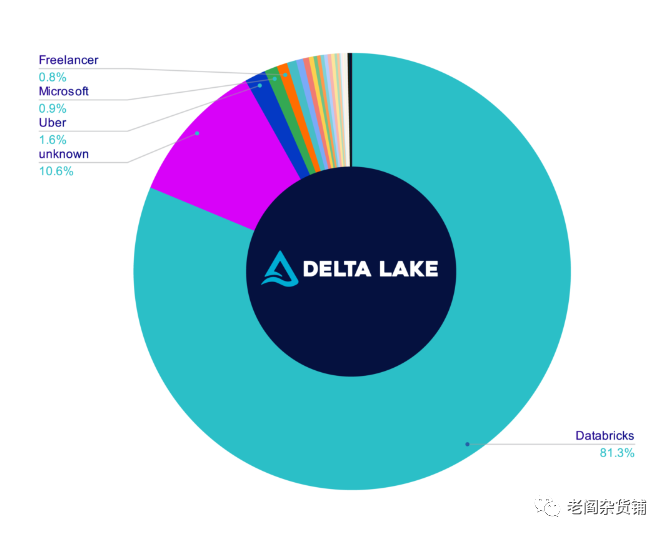
一番对比下来,总体的感觉就是Delta Lake开源产品能力不行,社区活跃度不够,开放度不够,基本上就是Databricks自己主导,开源的目的不纯。
有兴趣的大家可以去查看这篇文章:Comparison of Data Lake Table Formats (Iceberg, Hudi and Delta Lake) (dremio.com)(https://www.dremio.com/subsurface/comparison-of-data-lake-table-formats-iceberg-hudi-and-delta-lake/)
我相信也正是因为这个原因,Databricks才决定把自己藏在手里的Delta Lake的技术以Delta Lake 2.0的名义开源出来。

而以Databricks的技术实力,我相信完全开源的Delta lake 2.0无疑会给数据湖仓这个市场带来很大的技术进步。很多企业也会因为这些新公开的技术获益。Delta lake 2.0的社区也必将真正的更开放和活跃,反过来也会促进Databricks的商业化的能力。
这个世界是创新驱动的,在大数据领域,Databricks一直是一个创新的典范。相信更开放的Databricks,会有更多新的创新促进自己的成功。
