




最近读了一篇Chad Sanderson的文章,讨论数据建模是否已死的文章。文章的标题是:The Death of Data Modeling
在这篇文章中,Chad讨论了在现代数据技术栈中,为什么传统的语义模型驱动的数据建模在现代数据技术栈中变得不再适应。以及在现代数据技术栈中,关于数据建模带来的挑战。
那么为什么在现代数据技术栈的环境中,传统的数据建模不再适应呢? 要想回答这个问题,我们首先来了解一下数据建模是什么?
在维基百科中,数据建模的定义如下:


Data modeling is a process used to define and analyze data requirements needed to support the business processes within the scope of corresponding information systems in organizations. Therefore, the process of data modeling involves professional data modelers working closely with business stakeholders, as well as potential users of the information system.


从这个定义中我们可以看到,数据建模是一个把业务需求转换为数据需求并且进行相关的数据操作的过程。整个过程需要数据专家、业务专家以及对应的工程团队的配合才能完成。
在数据建模过程中,最重要的部分是语义模型。语义模型实际上是一种概念模型,是面向真实业务的一种模型表达。基于语义模型进行建模,不需要理解具体的编程语言和技术。建模过程仅仅需要理解数据对象、对象的属性,以及对象之间的关系就可以了。比如下图:
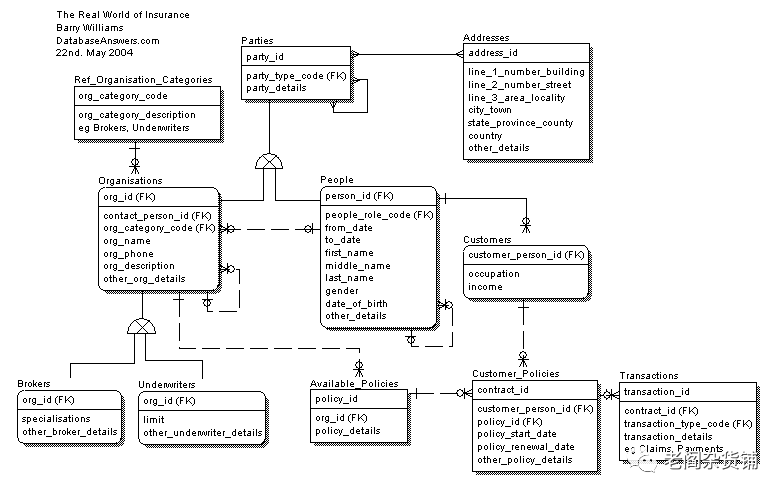
通过语义模型,任何人都可以理解业务和数据之间的关系以及想要达到的业务目标。
比如上面的图就是一个保险行业的语义模型。
在传统的数据建模过程中,语义模型会由数据架构师翻译为面向数据库或者数据仓库的物理模型,进而形成对应的ETL过程。
但是世界一直在进步和发展,随着数据产生的种类的增多,数据使用场景的增加,企业应用数据的方法也在发生变化。在现代数据技术栈中,数据使用已经从传统的ETL过程,已经变成了先从各个地方把不同种类的数据收集到一个居中的数据湖,然后再根据业务需要即时地进行数据建模和使用的过程。在这种场景下,数据逐渐从业务系统的副产品变为公司数据资产统一维护管理,然后再使用的过程。
通常情况下,在新的这种情况下,企业会有一个数据工程部门来统一接入和管理数据。而这个部门通常包含数据工程师和数据分析师。但是,使用数据的通常是业务部门,整个组织结构类似于:
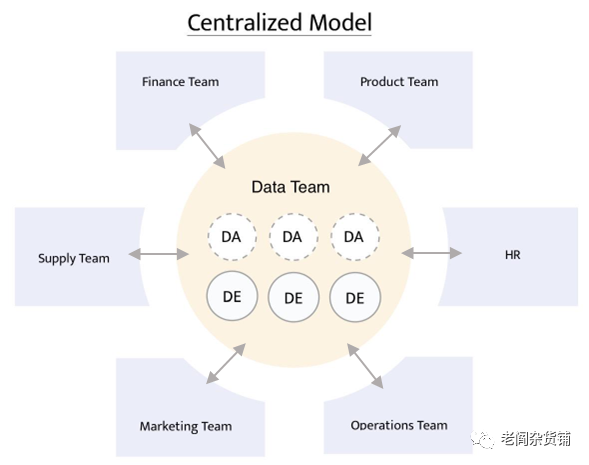
按照传统的数据建模方式,不同的部门会根据自己的业务需求给到居中的数据团队。通常,为了避免需求理解的偏差,需求会以文档的形式进行表述。数据团队根据需求文档,然后根据自己对数据的理解进行各种数据的处理,然后将加工好的数据结果给到业务团队。但是由于数据的产生和使用通常都不在数据团队中,因此结果往往达不到业务的要求。
而且由于数据团队面向不同的业务团队,数据需求在持续增加,于是数据团队往往不得不排期或者加班去解决各种需求问题。数据驱动就变成了一句口号,往往最终结果是数据团队和业务团队的相互指责。而企业花费巨大代价去收集和存储数据,结果数据湖变成了数据沼泽。

从这个角度看,传统的基于项目的瀑布式的数据建模在新形态下,的确已经不能适应企业的需求,所以从这个角度看,我们可以称之为数据建模已死。

数据建模重生

传统的数据建模已死,但是如果企业要发挥数据的巨大价值,我们需要在新的形态下的新的数据建模过程。我们可以称之为在现代数据技术栈上的现代数据建模,这是一种敏捷的数据建模过程。
首先,新的敏捷的建模过程中,组织的形式也在发生变化。新的组织形式会变为:
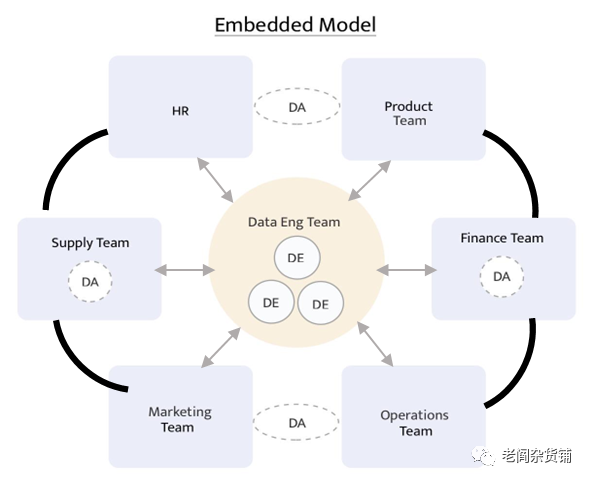
在这个新的组织结构中,分析师团队前置到业务团队中。居中的数据团队变为纯粹的工程师团队。这个工程师团队不再负责具体业务模型到物理数据加工的过程,而仅仅负责从不同的数据来源把数据接入到数据湖中,以及选择和准备好方便业务团队使用的工具。同时,对数据资产的安全性、运行的数据加工流程的运行状态以及计算资源进行管理。因此,数据工程团队的日常角色主要是做数据本身作为一种生产资料的日常维护和运营。数据如何在业务中产生价值则完全由不同的业务单元来负责。
而由于数据分析师前置到业务团队,因此分析师的核心职责就跟业务团队绑在一起。考核分析师主要看分析师是否能够理解业务,能够让数据更好地支撑业务团队日常的运营。数据分析师就从更偏技术转变为更偏业务运营,属于运营支撑的一部分。从公司人力资源角度来看,分析师这个角色的定位也更清晰。
但是为了支撑这种新型的敏捷的数据组织架构,传统的数据工具就不再适应新的这种形式。
传统的BI和敏捷BI都是为项目制的数据建模过程设计的。虽然敏捷BI相对传统BI实施周期短,但是还是要有比较长的实施周期。虽然业务团队最终可以访问已经建模好的数据。但是没有能力从数据湖的原始数据去通过语义模型进行数据的整理、建模然后使用。
传统的数据建模工具都是工程师工具,需要大量的SQL甚至python等等代码开发工作
现代数据技术栈的出现部分地解决了企业使用数据的问题,但是在数据建模过程中,问题仍然没有解决。其核心原因为:
现代数据技术栈从开始设计就是面向数据工程师团队的,目前工具的核心的交互界面是SQL。
现代数据技术中非常强调先把数据居中管理,因此企业的各种数据可以方便进行接入。为了降低成本,事实上接入的数据一般都会存储在廉价的对象存储,也就是数据湖中。但是对数据湖中的数据访问和使用比传统的数据库中访问数据对技术的要求更高。
海外有一些新的BI工具可以让业务人员直接访问数据仓库中已经被清洗好的数据。但是对于在数据湖中的比较脏乱差的数据的使用,还主要依赖工程师来解决。
因此,我们需要一个能够让业务团队或者面向业务的分析师团队能够直接操作数据湖上的各种数据,并且能够用自己理解的方式去建模和使用数据。而真正底层的技术复杂度,应该是工具来解决。
最近跟国内外的一些数据团队的沟通也证明了这一点。只有一个面向最终用户友好的面向脏乱差仍旧能够工作的数据建模工具,才能真正的释放数据资产的价值,让数据湖不会变为数据沼泽。这也正是驱动我们努力去创造产品的原动力。希望通过我们大家的不懈努力,能够让数据驱动真正变为企业的一种日常,而不是口号。传统的数据建模已死,新的数据建模会根据技术和产品的发展而重生。
