




希望大家度过了一个安康的端午节。在家居家办公两周之后,北京总算是阶段性地战胜了这一波疫情,可以继续回到办公室上班了。
前面的文章写过不同的现代数据技术栈相关的内容,很多情况下都是与数据技术有关。不过在任何领域,都需要不同的理论来支撑从而让技术的发展可以沿着一个相对正确的方向去演进。
在今天我就来介绍一个对于我们做数据的朋友来讲非常有指导意义的模型 - DIKW金字塔模型。

DIKW是什么?
首先,我们来了解一下DIKW是什么? 按照惯例,我们还是先看看维基百科如何来描述DIKW的:

The DIKW pyramid, also known variously as the DIKW hierarchy, wisdom hierarchy, knowledge hierarchy, information hierarchy, information pyramid, and the data pyramid, refers loosely to a class of models for representing purported structural and/or functional relationships between data, information, knowledge, and wisdom. The DIKW pyramid, also known variously as the DIKW hierarchy, wisdom hierarchy, knowledge hierarchy, information hierarchy, information pyramid, and the data pyramid, refers loosely to a class of models for representing purported structural and/or functional relationships between data, information, knowledge, and wisdom.

从上边的描述我们可以看到DIKW金字塔是描述如下的四个层级:
D - Data
I - Information
K - Knowledge
W - Wisdom
之间关系的一个模型。也就是数据、信息、知识和智慧之间的关系的模型。
如何去理解DIKW?
关于DIKW,我们首先可以看一下如下这张比较经典的图:
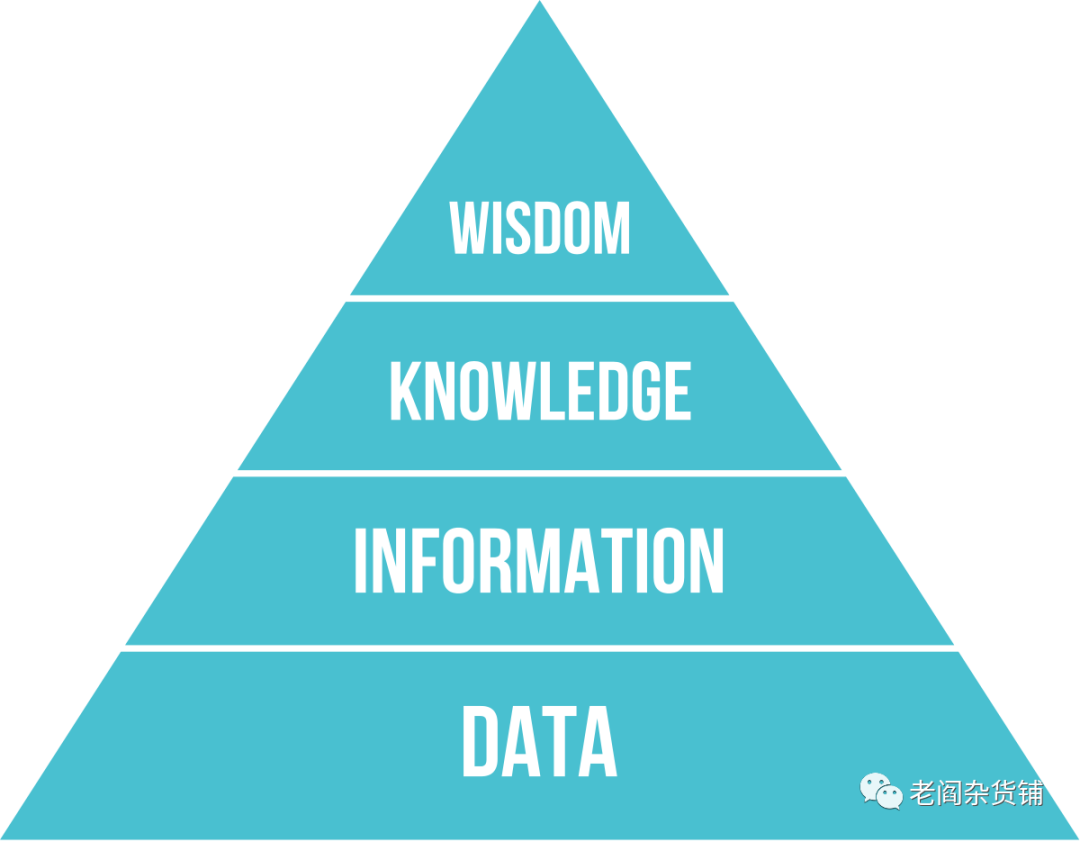
这是典型的DIKW的金字塔描述。最底层是数据层,往上是信息层,信息层的上边是知识,最上层是智慧。这张金字塔模型虽然把Data, Information, Knowledge和wisdom做了分层,但是并没有给出分层的逻辑。
我们可以再看如下的这一张图:
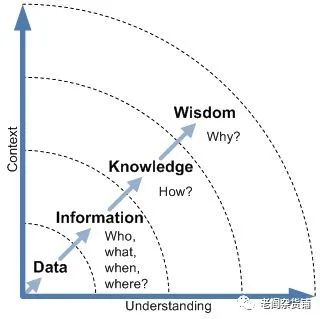
从这张图上,我们可以更好地理解数据,信息,知识和智慧之间的关系。
数据是最基础的事实的记录。
信息则是在把事实数据与上下文数据进行组织关联。包括数据相关的主题who, 相关的事件what,发生的时间when以及发生的位置信息等等。通过把数据与相关的上下文的进行组织,就变成了容易理解的信息。
有了这些信息之后,人就可以知道这些数据的真实含义,知道了事情是如何发生的,也就有了know how,所谓的知识。
基于这些总结的知识,我们就可以推演出why,也就是知道了因果关系,从而方便我们人类对未来进行预测和判断,所谓形成了智慧。
为了增强理解,我们可以再看一下如下的这张图:
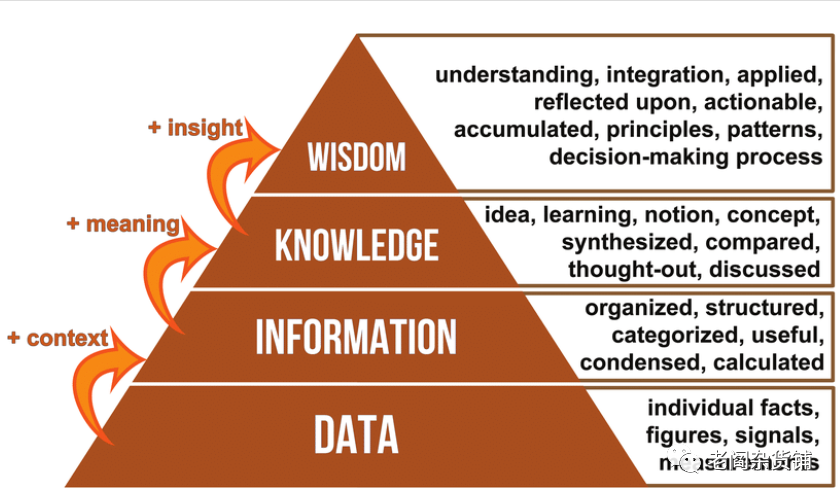
这张图更清楚地描述了数据、信息、知识和智慧之间的进阶关系。总的来讲,数据仅仅是基于对事实的记录,本身是没有价值的。在被组织起来之后,就形成了可以被理解的信息。通过对这些信息的理解,就可以转化为人类的知识。而这些知识是我们未来做判断的基础,通过知识才能形成人们的智慧。所以我们才说知识是智慧的源泉。
现代数据技术与DIKW的关系
我们前面介绍了DIKW这个金字塔模型,以及如何理解数据、信息、知识和智慧。接下来我们可以看看这个DIKW模型跟我们现在数据技术中从数据收集到最后被有效使用整个过程的关系。
首先我们来看看数据。在现代数据技术中,数据的产生来源越来越丰富。在企业中有来自于自己核心业务系统中的数据,比如来自于客户的订单数据、采购原材料的数据、企业ERP系统产生的数据。如果生产制造企业,可能还有库存数据、机器设备的各种数据、厂房环境相关的数据等等。越来越多的企业开始支持柔性制造甚至直接实现D2M,那么就会有用户在自己的网站上的浏览行为数据、下单的数据等等。企业如果要做广告,则会有来自于媒体的广告投放数据、第三方广告监测数据等等。企业采购了一些第三方的SaaS服务来支撑自己的日常运营,SaaS平台还会有运营相关的数据。
所有这些数据,本身都是企业在日常生产运营中记录下来的事实数据。由于来源多样,因此就有不同的数据格式,不同的表达方式。这些数据不通过加工处理,是不能够变成有价值的信息被使用的。
在现代数据技术中,为了方便对数据进行后续的处理,这些数据一般的会被数据集成工具(Data Integration)统一地汇集到数据湖(Data Lake)中。这个过程我们一般称之为EL过程。当然,有些数据本身存储在业务系统的数据库中,也可以采用Data Mesh或者Data Fabric方式被数据建模工具访问,避免数据的移动。数据集成过程如下图:
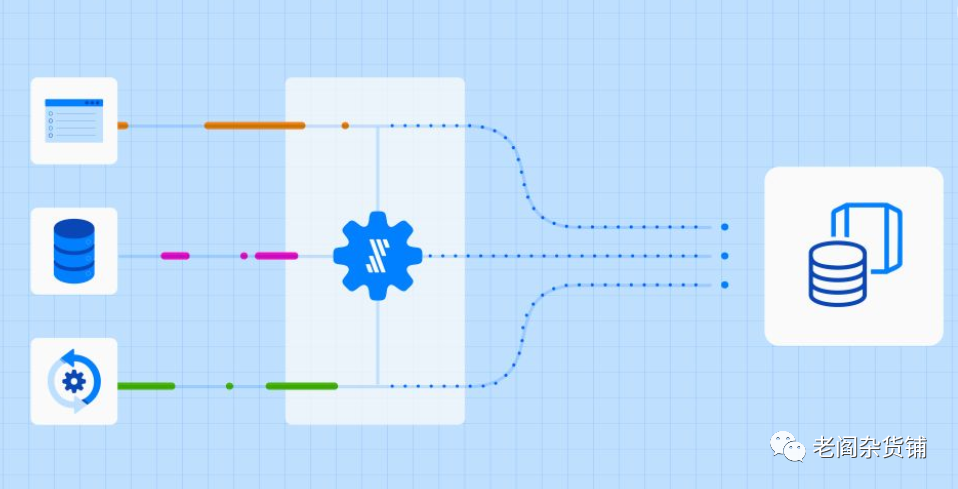
数据集成工具一个比较常见的选择就是图中的蓝色齿轮代表的Fivetran(估值56亿美金的独角兽Fivetran - 重新定义数据流)。
数据被集成到数据湖中之后,还仅仅是事实数据,想要变为有价值的信息,就需要进行数据的清洗、关联、增强、转换。我们把这个过程叫做数据建模过程。
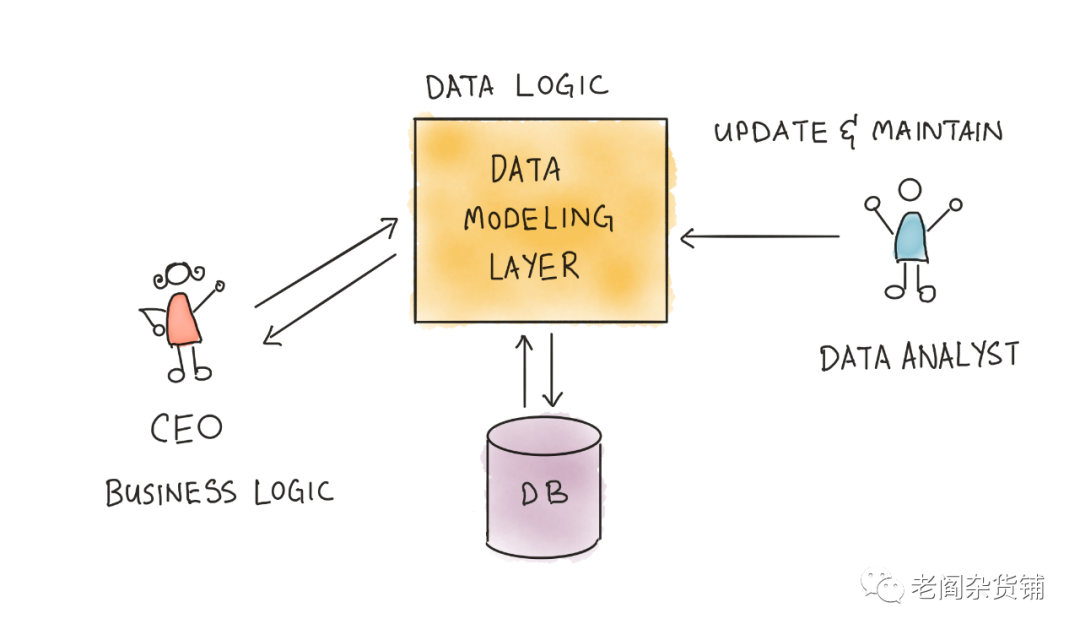
在现代数据技术中,因为数据处理的过程已经由ETL转变为ELT,因此数据建模就逐渐变成了一个高频的过程。企业的日常运营决策,都是从数据湖中获取最初的事实数据,然后根据业务的需求,把相关的场景中的数据相关联,清洗掉无关的数据,然后再做增强,最终形成需要的数据模型。
这里就有一个非常有意义的话题,就是数据质量。在上一家公司我带领数据团队支持公司的不同的业务的需求。有时候就经常收到关于数据质量的各种的不同的抱怨。我当时的一个观点是数据质量本身与数据本身没有关系,而是与根据业务需求进行的数据建模有关,与其说是数据质量,不如说模型质量。这里我可以举一个具体的例子。我们上一家公司主要的数据是来自于移动设备上应用采集的用户行为数据以及当时的行为发生的环境相关的数据,其中非常有价值的一种数据是位置数据。但是移动应用在当时的那个资本环境下,经常会存在有刷量的行为。所谓刷量就是有一个刷量工厂,用大量的手机来模拟用户注册、登录等等行为,从而使得应用的新增活跃等等数据会很高。刷量的时候,这些设备采集到的位置数据会有非常明显的聚集效应,也就是在一个不大的小地方,出现非常多的移动设备。
这些数据都是真实地被采集下来的,是事实数据。但是当时我们有一个数据应用是用位置数据去服务一些零售客户的选址。也就是基于地理位置进行移动设备量判断来判断人流量。在做这个业务的时候,一开始我们没有去对这些刷量的数据进行清洗,结果造成了与常理完全违背的数据分布,从表面看,也就是数据质量有了问题。当时有一个建议是在数据进入数据湖之前应该过滤掉这些数据,因为这个数据质量有问题。但是我们换一个场景,假定我们现在要做一个研究刷量行为的数据应用,这些数据则正好是最适合研究刷量行为的数据。如果在进入数据湖之前就过滤掉,则显然就丢失了非常有价值的数据。从这个例子我们就可以理解,数据只有在建模过程中,才能根据业务的需求去做清洗、加工增强,然后产生数据跟需求的环境匹配的价值。决定信息的价值的最关键的不是数据,而是把数据加工为信息的建模过程。
在现代数据技术栈中,支持的工具有面向分析工程师的SQL工具dbt海外数据转换工具独角兽 - dbt labs以及面向数据分析师和数据运营团队的无代码工具QuickTable。
在完成数据建模之后,为了达到人容易理解,就进入了从信息到知识的过程。我们目前最常见的就是各种形态的仪表盘和报表。仪表盘和报表一般是通过直观的图表来表达数据的趋势,从而能够让人能够根据图表就能了解发生了什么,并形成自己的判断。
不过,很多情况下,图表虽然直观,有时候还是需要一些文字进行描述。因此在建模过程中,包括图表的展示中,把建模的思考、图表的表达再形成文档并能够保留下来,无疑对于知识的传递和理解都是有帮助的。
另外,对于大型企业来讲,不同的部门可能都需要一些共同的基于数据形成的报表指标来方便自己进一步组织自己部门的指标,这些就是企业共识的知识。
在现代数据技术栈中,解决从信息到知识的产品一般是各种BI来解决的问题。另外,metric store相关的产品则解决共识存储的问题,相关文章可以参看:现代数据技术栈中的指标存储-Metrics Store
具体到智慧,则是由人根据知识,形成判断,进而进行决策,因此智慧在于人。
不过数据使用的链条并不仅仅是这一种方式。随着机器学习和人工智能技术的发展,还有一种是从数据到信息、信息、进而到知识和智慧的路径。这就是机器学习过程。在这条路径上,需要的是先有从原始的事实数据到决策结果的样例数据,所谓样本数据。数据科学家会从原始点事实数据中抽取特征,也就是有价值的信息,这个过程称之为特征工程。然后数据科学家开始进行模型的训练,通过不同的机器学习算法的选择,最终形成一个在已知的样本的数据上能够很好地验证效果的机器学习模型,这个模型可以认为是机器能理解的知识。这个时候,有了新的数据出来,机器就可以利用训练好的模型进行预测了,这时候机器就有了智慧,我们称之为人工智能。
虽然过去10年人工智能因为大数据的发展以及计算机计算能力的增强取得了非常大的进步,但是目前还仅仅是在有限的领域有比较好的应用价值。过去几年跟不同的朋友也有过讨论,人工智能目前比较适用的场景是需要非常高频次的决策、但是决策之后不会产生严重负向效应的场景。比如广告、金融风控、以及一些机器视觉应用的场景。但是如果错误决策能够造成严重的负向效应的,人工智能还有很长的路要走,因为人很难把决策风险高的决策交给机器。
总结一下
DIKW金字塔模型虽然不是为了数据技术所设计的,不过人们使用数据的目的与DIKW所表达的实际上是一致的。因此DIKW模型可以很好地来映射我们目前数据技术的发展的趋势。新的这个时代是数据爆炸的时代,也是计算能力大发展的时代,我们人类之所以进入数字化,就是希望能够更多的用数据来帮助自己决策,提高决策的效率和正确率。人类的智慧有了机器的辅助,希望能够更好地改善世界以及人类自身。
