




在今年4月份, Continual的Jordan Volz在medium自己的博客上新发表了一篇文章《Who's Who in the Modern Data Stack Ecosystem(Spring 2022)》,陈述了他对现代数据技术栈在2022年第一季度发展的一些看法,并且列出了相关生态的主要公司和值得关注的公司。
这篇文章整体比较长,我这里不做全文翻译,仅仅做内容的提炼整理,方便大家阅读。
首先,现代数据技术栈继续进行快速的发展,这从过去一个季度中的融资事件中就能够发现端倪。Dbt, Airbyte, RudderStack, Hightouch, Census, Atlan和Hex都有了非常不错的融资。其中Dbt融资估值达到了46亿美金,而Airbyte仅仅两年时间就估值超过了15亿美金,可见现代数据技术栈生态系统中的投资热潮还在继续。
除了融资的火热,现代数据技术栈生态系统也愈发的繁荣,在这其中有三个值得关注的趋势。
01
现代数据技术栈的三个趋势
SQL虽然好,但是新的趋势是Beyond SQL的扩充
由于现代数据技术栈是以云端的数据仓库为核心进行构建的,而数据仓库又是天然的采用SQL语言作为操作的界面,因此SQL就变成了整个现代数据技术栈的核心技能。
但是SQL作为一种编程语言,毕竟是一种工程师工具。能够很好的掌握SQL并不是一个非常容易达到的目标,更何况在数据处理场景中还有很多操作SQL因为其语言的限制并不能非常容易的去实现。因此需要新的超越SQL的工具来解决不同类型的目标用户的需求。比如支持云端数据仓库/数据湖的可以无代码进行数据清洗、建模以及分析的工具,或者能够支持SQL, Python, 以及更多编程能力的工程师工具。这里透露一下,我们团队创业的产品就是超越SQL的工具,希望能解决更多的对SQL没有那么熟悉的数据人员使用数据的问题。
2. 实时数据处理的支持
目前的现代数据技术栈基本上围绕着几个云端的数据仓库来构建生态。无论是Snowflake, Redshift, Google BigQuery还是速度更快的Databricks,对实时场景的支持都还没有那么好。因此很多的新的产品都在实时数据处理上做功夫,比如Materialize流式数据上的SQL数据库 - Materialize, Confluent的KSQL,以及我一个老朋友在硅谷新创立的Timeplus等等。
3. 与遗留数据技术栈的竞争
现代数据技术栈是以云作为基础设施重新构建的使用数据的一整套生态系统,这个系统正在变得越来越茂盛。一个新的企业在做选择的时候可以非常容易的下决定采用现代数据技术栈,因为公有云带来的弹性、入门门槛低等等优点对于新兴企业是非常难以拒绝的诱惑。但是对于一个已经用传统的软件时代的产品搭建了自己数据系统的传统企业来讲,除非带来的好处显著的大于迁移的成本,否则企业采用现代数据技术栈的动力就不足。相信现代数据技术栈公司会通过技术的创新以及明显的投资回报来一步步的打动这些客户,最终完成新的技术栈对遗留系统的替换,当然这一切肯定不会是一帆风顺的。
02
2022现代数据技术栈春季版
下面就来总结一下2022数据技术栈春季版本的那些公司以及相关的进展,首先看看这幅生态图:
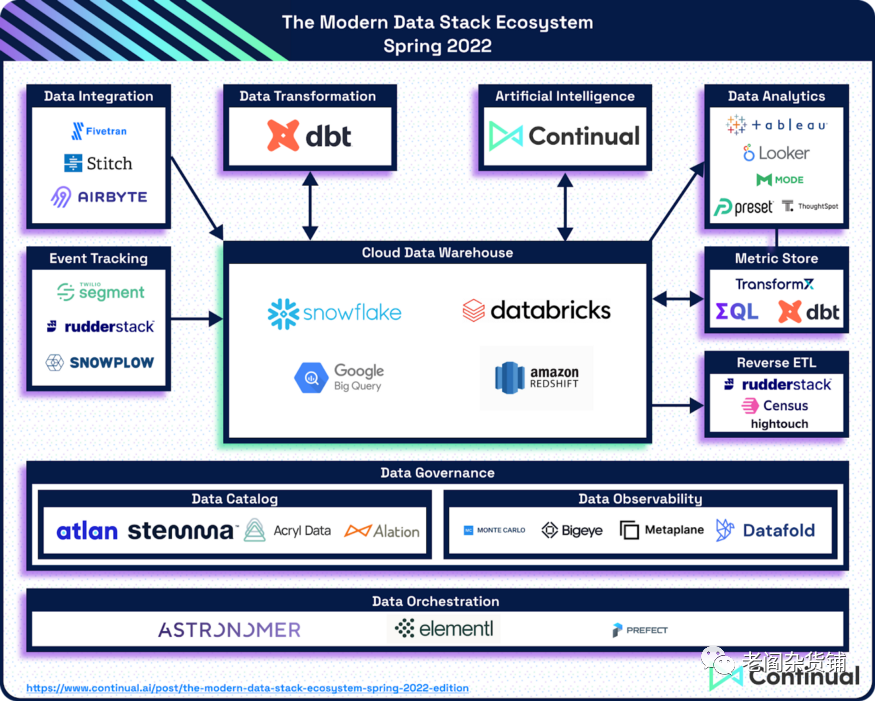
按照现代数据技术栈中不同的组成部分,来看看各个方向的主要公司和正在兴起的新兴公司。
云端数据仓库
云端数据仓库是现代数据技术栈中处于生态核心位置的技术领域。主流工具还是大家都比较熟悉的:Snowflake, BigQuery(Google), Redshift(AWS), Databricks。正在兴起的新星:Firebolt, Dremio
关于几个主流的云端数据仓库都不需要更多的介绍了,下面简单的介绍一下Firebolt和Dremio.
Firebolt - Firebolt是一家以色列云端数据仓库初创公司,算是一家明星初创企业。由前Sisence CTO创建。基于另外一个非常火爆的开源数据平台Clickhouse构建。主打的特点就是快速,最新的估值已经超过10亿美金。
Dremio -Dremio是一个成立于2015年的云上的湖仓一体的平台。通过开源的Sonar - 一个兼容各种数据仓库和数据湖的SQL引擎,来提供跨数据仓库的数据访问以及分析能力。我会专门写一篇介绍Dremio这个公司的文章。
数据集成和事件追踪
Jordan Volz把这两个领域放在一起来谈,主要的原因是这两种类型的公司都是帮助客户收集数据。在围绕着云端数据仓库的数据技术栈中处于最左边,也就是数据接入的这一部分。
数据集成主流工具:Fivetran, Airbyte, Stitch
数据集成值得关注的新星:Hevo Data
事件集成主流工具:Segment, RudderStack, Snowplow
在数据集成领域,我分别在我的公众号介绍过Fivetran(估值56亿美金的独角兽Fivetran - 重新定义数据流), Airbyte(不让Fivetran独美,Airbyte新晋独角兽)。至于Stitch,属于和Fivetran基本上同时起步的数据集成公司,可惜相对早期就被Talend收购。
至于Hevo Data,这是一家成立于2017年的数据集成公司,创立于旧金山。目前处于B轮融资阶段,总融资额达到了4300万美金。后边我会对这家公司做一定的调研,专门整理一篇文章。
关于事件集成的主流工具,Segment已经上市,属于CDP领域最知名的公司之一。RudderStack我曾经介绍过(给工程师的CDP - 开源CDP厂商RudderStack),而Snowplow则是一家开源的行为数据采集分析平台,做的事情类似于amplitude,采用了开源+公有云商业化的路径,本来也有计划专门写一篇Snowplow的调研文章。
由于数据集成是构建以云端数仓为核心的现代数据技术栈的第一个需要考虑的,因此这个市场的工具是最早也是竞争相对比较激烈的一个部分。目前的更多的竞争是价格以及性能的竞争。Airbyte通过开源去更好的支持长尾数据来源获得了不错的用户增长。而Fivetran则通过资金的力量并购了做实时数据接入的HVR来增强自己的能力。
而在事件集成领域,RudderStack通过开源来打开了这个领域的一个新的开口。主打开发者这个群体,让RudderStack能够与Segment进行错位的竞争。
数据建模和转化
在这个市场上目前只有一个主流选择就是dbt。关于dbt,我在去年写过一篇文章(海外数据转换工具独角兽 - dbt labs) 。而关于数据建模和转化这个场景的需求,我在这篇文章中聊一聊数据建模和数据转换 写过我自己的一些思考。当然,相信在不久的将来,我们团队做的QuickTable会是现代数据技术栈中一个用户值得使用的选择。
人工智能和机器学习
在现代数据技术栈中AI和机器学习领域,处于主流选择的是Continual。文章的作者Jordan Volz来自于Continual,因此他把Continual列在这里边也情有可原。尽管在云上人工智能和机器学习平台不少,不过Continual的确在里边处于一个相对独特的位置,就是非常好的与现代数据技术栈中的其他数据工具链能够兼容。
数据分析/BI以及指标存储(Metrics Store)
在这一个部分实际上包含了两大类产品。一类是BI类型的产品,一类是Metrics Store。两类产品实际上都处于数据使用的环节。
在BI领域,主流的产品包括Looker, Mode, Tableau, Thought Spot, Preset。值得关注的产品则包括Sigma, Lightdash,Superset,Glean。
而在Metrics Store这个领域里的主要工具包括dbt, Transform, Metriql。
由于BI是大家最为熟悉的数据工具领域,在这里我不会再过多的介绍相关的历史和技术。有兴趣的可以参看BI、数据仓库、数据湖、湖仓一体都是什么?
BI领域里主流公司包括被Google收购的Looker,属于我非常喜欢的一个产品。敏捷BI的代表Tableau已经广为人知,Preset是非常知名的开源数据可视化项目Superset的商业化版本,Thought Spot和Mode则都是在现代数据技术栈中非常知名的BI产品了。
Sigma则是利用表格作为交互的新型的BI平台,产品比较有特色,与Snowflake有非常好的关系。Lightdash是基于dbt做BI的新兴的一个开源BI工具。Glean则是我第一次知道的一个工具,从公司的网站看,是很好的集成了现代数据技术栈的工具链的一个交互式数据可视化平台。后边我会专门写一篇文章来介绍一下Lightdash和Glean.
具体到Metrics store,可能很多人并不是很熟悉这个词。Metrics store主要是存储一个企业的大家都关注点KPI指标在一个中心位置,从而使的企业的业务系统在需要指标时可以从这个中心位置获取,保证数据的准确和一致性。后边我同样会专门写一篇文章来介绍Metris store.
在Metrics store领域,最知名的应该是Transform,不过dbt在完成最新一轮融资后,也投入更多的力量来进入Metrics store这个领域。
Reverse ETL/数据操作化(Data Operationalization)
在反向ETL这个领域比较主流的工具是Census, Hightouch, Rudderstack。值得关注的公司是Hevo Data。关于反向ETL以及相关的公司,大家可以参看反向ETL(Reverse ETL)以及相关的公司 。这里我就不过多的再介绍相关的知识了。
数据编排
在数据编排这个领域的主流公司是Astronomer, Elementl, Prefect,值得关注的公司是Flyte。
数据编排主要是解决数据处理流程的编排和调度,而Astronomer就是大家都非常熟悉的Airflow的商业化版本。其余的Elementl, Prefect以及Flyte都是做类似事情的。国内的DolphinScheduler也在计划出海,希望在不久的将来,我们能在这个名单中看到DolphinScheduler的身影。以后我会专门写一篇文章来介绍数据编排以及相关的公司。
数据治理
数据目录领域的主流公司包括Atlan,Stemma, Alation, Acryl Data,值得关注的公司包括Secoda, Metaphor Data。数据可观测性的主流工具则包括Monte Carlo, BigEye, DataFold, Metaplane。
数据目录对于一个企业管理自己的数据资产非常的重要,传统软件时代都有不错的数据目录产品。不过到了公有云时代,新的数据目录产品也在涌现。在现代数据技术栈中的这些数据目录产品,Alation我在2016年调研过,其余的几个都比较新。看来有必要对这些新的产品做一些调研。
而对于数据可观测性,这些公司大部分我都介绍过,可以参看:数据可观测性和相关的公司 。
孵化期工具
Notebook
随着现代数据技术栈被越来越多的用户接受并采纳,不同类型的用户的涌入让对非SQL类型的工具的需求越来越强烈。而其中方便程序员写程序的Notebook的需求也就随之产生。相关的工具包括:Hex, Deepnote, Noteable, Hyperquery. 现在想起来,在TalkingData的时候,我们就判断在云上能够支持协作的notebook应该是个重要的科学家工具平台。而且还做过一个包装了notebook的支持一定协作的在线工具,现在想想当时真是判断了正确趋势,只可惜这趋势都是在大洋彼岸。
实时/流式
企业对数据的使用会越来越高,所以实时流式的需求就逐渐变成一个趋势。这里可以值得考虑的有Materialize(流式数据上的SQL数据库 - Materialize),Decodeable, Meroxa, Rockset。
用户参与平台(CEP)
因为用户的数据在逐渐的迁移到云端的数据仓库,因此有一个趋势是所有的SaaS软件系统可能会在云端以云端数据仓库为核心重新创造从而颠覆原来的SaaS系统。而客户参与平台因为对数据的重度依赖,因此也是最早被颠覆改造的垂直领域。值得关注的公司包括:MessageGears, Braze, Supergrain。
数据应用
数据处理之后的最终用途就是被应用,因此基于云端数据仓库构建的数据应用也是一个非常重要的领域。值得关注的公司包括:Streamlit, Columns.ai, Anvil。
03
总结
现代数据技术栈自从提出以来,获得了越来越多用户以及投资商的关注。这其中有已经建立了自己市场地位的Snowflake, Databricks,也有正在进入人们心智的Fivetran, dbt。但是有越来越多的新兴的企业正在通过自己的技术创新来帮助用户更好地使用数据。一个蓬勃的现代数据技术栈生态正在形成,正如dbt的CEO把现在比作现代数据技术栈的寒武纪二期。物种大爆发的寒武纪让我们地球有了如此丰富多彩的生命,而现代数据技术栈的寒武纪二期必然会产生更多有价值的公司,相信我们中国的团队所创造的产品也必然会在这里有自己独特的生命力。
