





摘要:Apache DolphinScheduler 已经在DataOps领域提供了强大的分布式可视化工作流调度能力。2022年,我们为其新增了机器学习任务调度的能力,逐步开箱即用式地支持主流的MLops项目/服务商的功能。
Apache DolphinScheduler 目前已经支持的MLOps工具包括MLflow,DVC,Jupyter,OpenMLDB等任务组件,可以让用户低成本,更容易地编排机器学习系统。
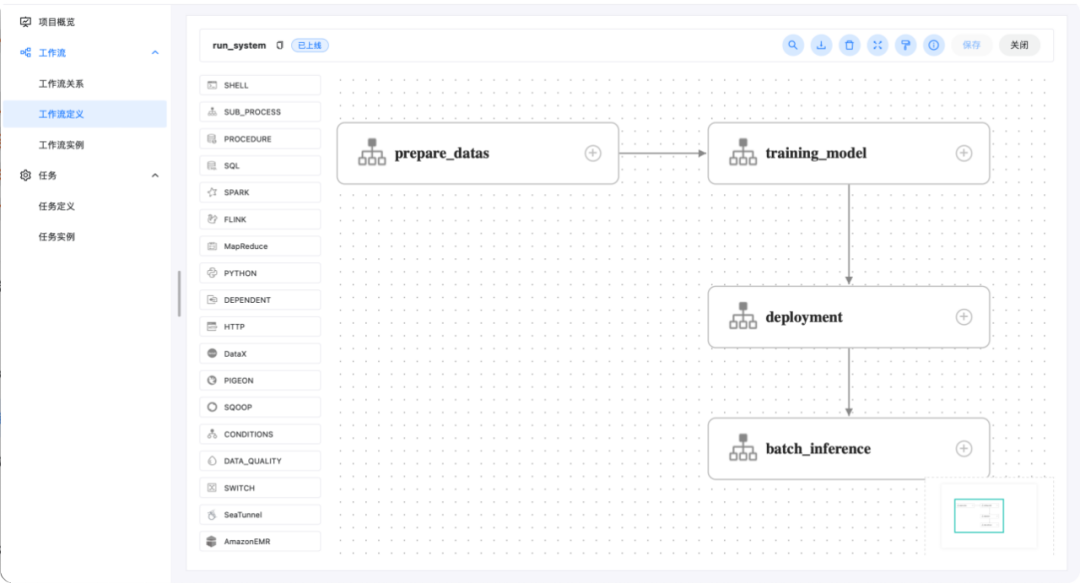
本文为大家介绍如何使用Apache DolphinScheduler来打造一个机器学习选股系统,每日自动更新选股模型,智能选股,在交易时间持续监控模型选股效果。
1
系统介绍概况
概况
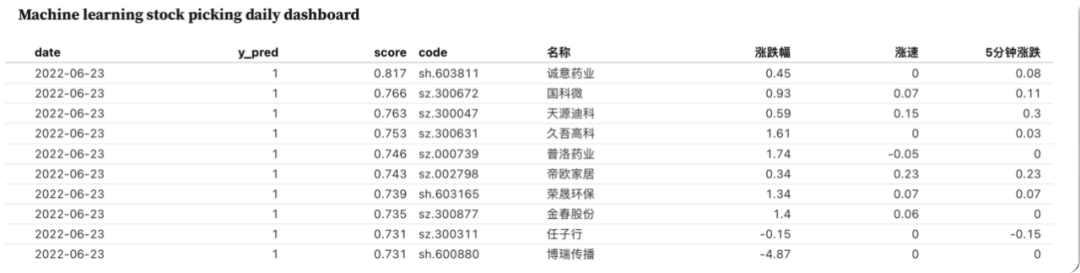
Machine learning stock picking daily dashboard
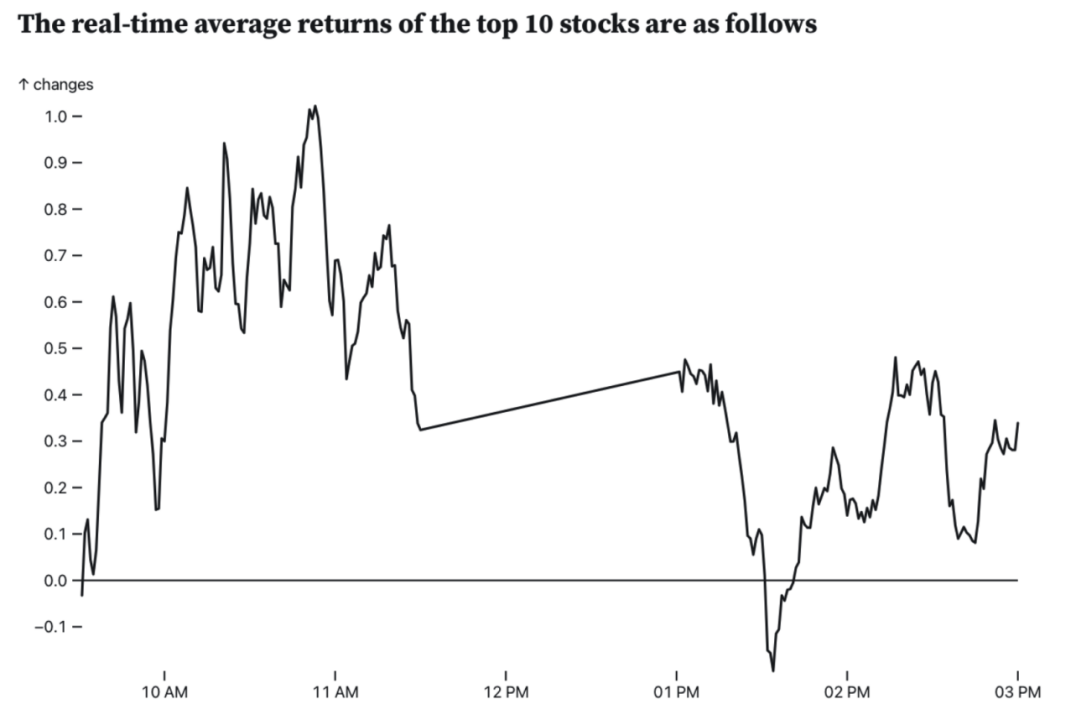
为2022-06-23晚上选出的股票,在2022年6月24的实时表现,包括涨跌幅,涨速等信息The real-time average returns of the top 10 stocks are as follows
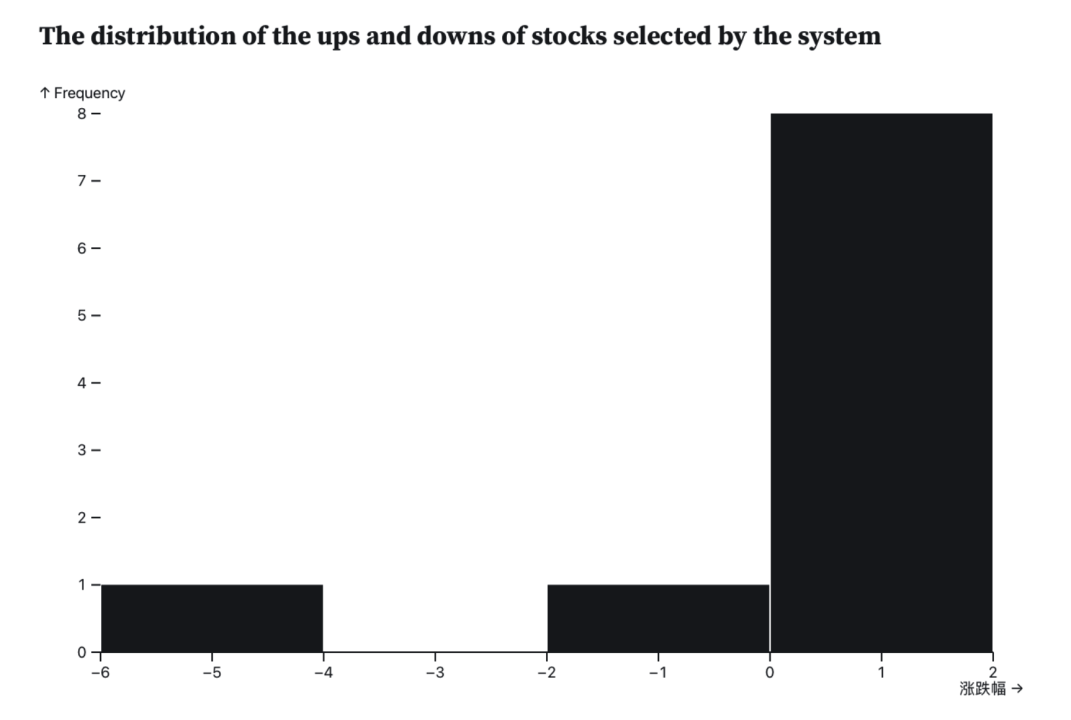
实时展示了选出的10个股票在日内平均的收益走势情况The distribution of the ups and downs of stocks selected by the system
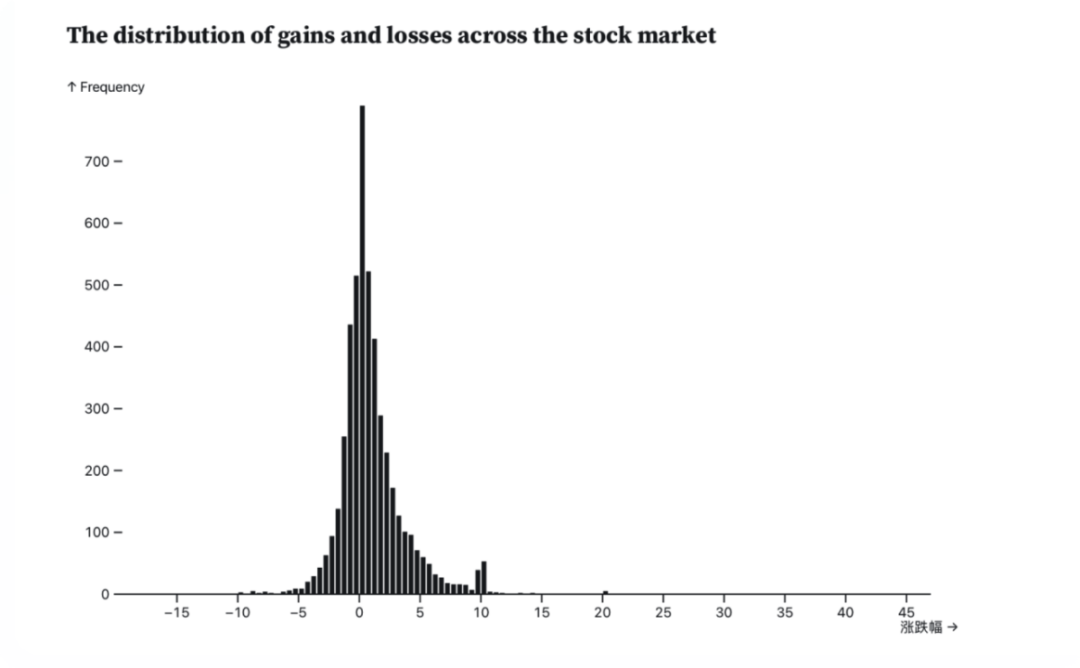
实时展示选出的10个股票的涨跌幅分布The distribution of gains and losses across the stock market
实时展示了整个市场的股票的涨跌幅分布


模块介绍
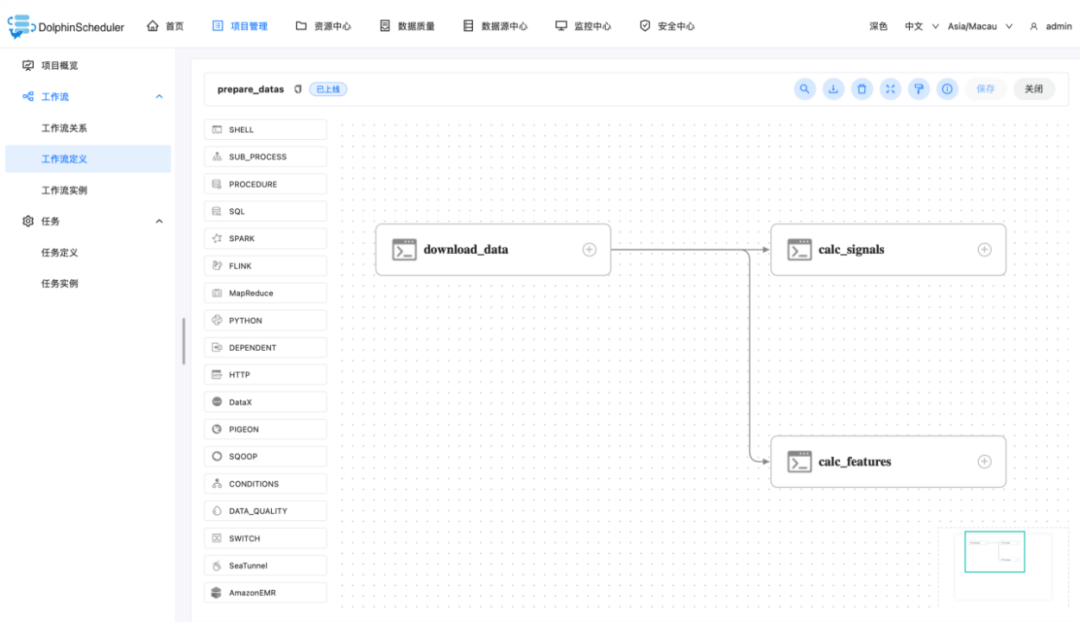
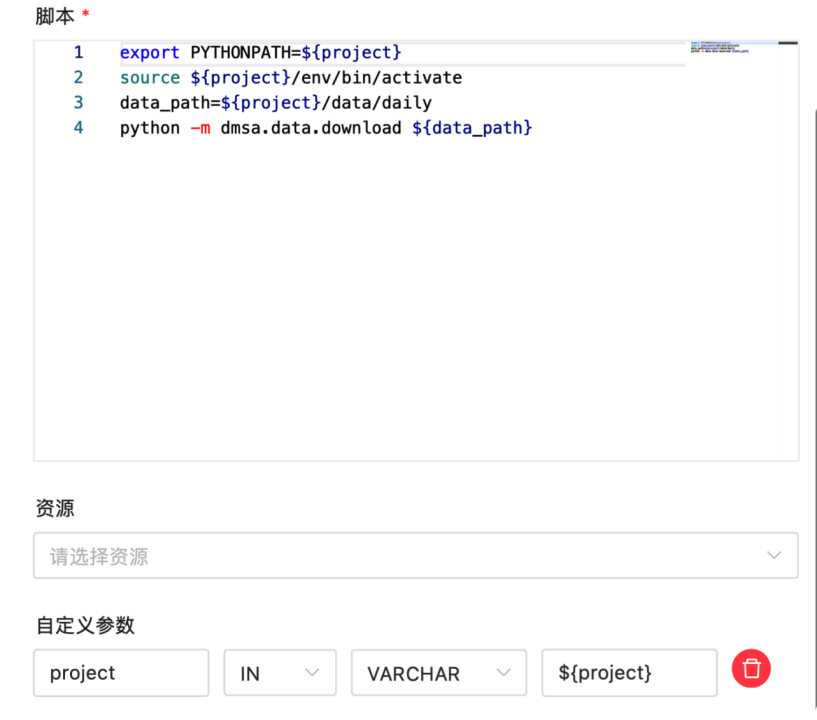
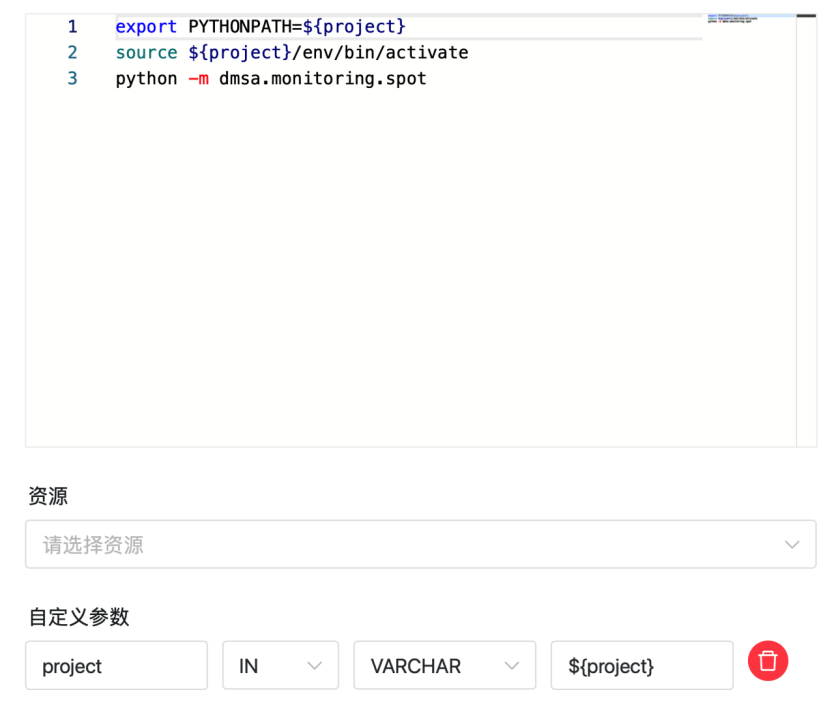
export PYTHONPATH=${project}
# 激活Python环境
source ${project}/env/bin/activate
data_path=${project}/data/daily
# 下载数据到指定路径
python -m dmsa.data.download ${data_path}
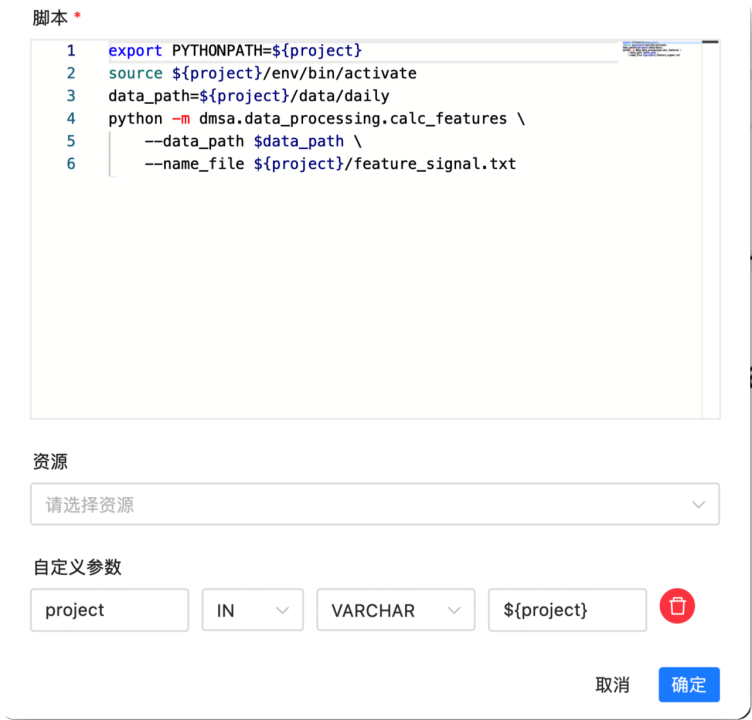
export PYTHONPATH=${project}
source ${project}/env/bin/activate
data_path=${project}/data/daily
python -m dmsa.data_processing.calc_signals \--data_path ${data_path} \--name_file ${project}/feature_signal.txt
export PYTHONPATH=${project}
source ${project}/env/bin/activate
data_path=${project}/data/daily
python -m dmsa.data_processing.calc_features \--data_path ${data_path} \--name_file ${project}/feature_signal.txt
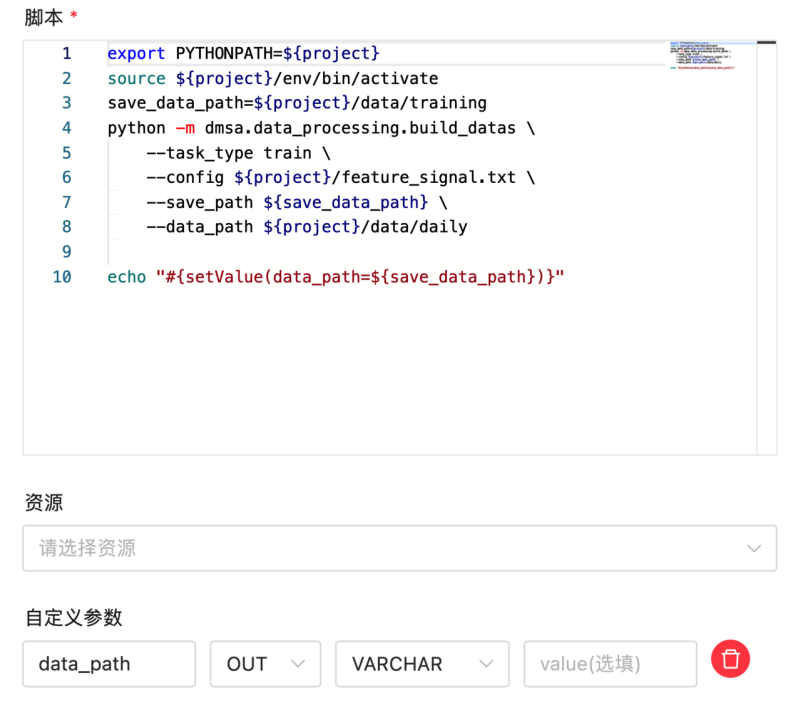
export PYTHONPATH=${project}source ${project}/env/bin/activatesave_data_path=${project}/data/training
# 生成数据集
python -m dmsa.data_processing.build_datas \--task_type train \--config ${project}/feature_signal.txt \--save_path ${save_data_path} \--data_path ${project}/data/daily
# 把生成的数据集所对应的路径 save_data_path 赋值到变量 data_path 中,并通过自定义参数设为OUT,传递给下游任务
echo "#{setValue(data_path=${save_data_path})}"
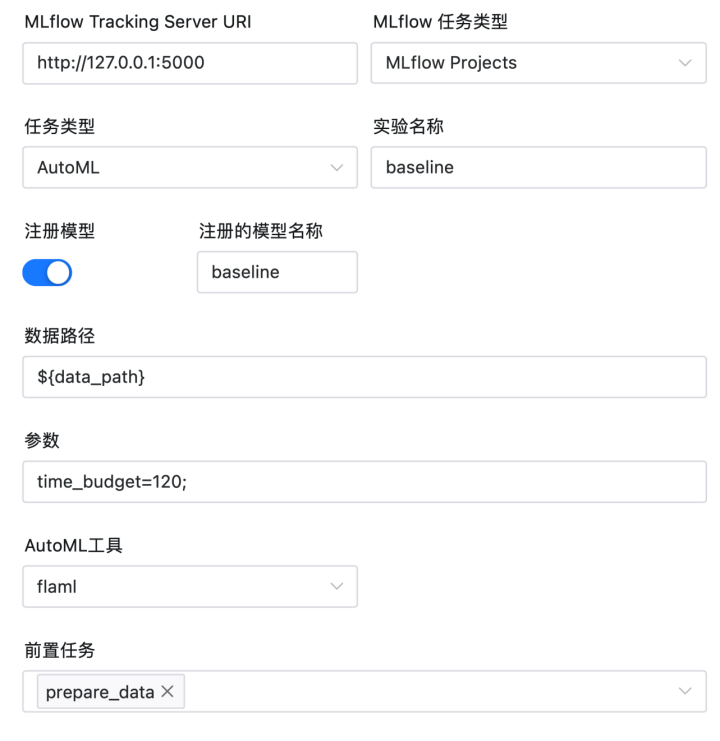
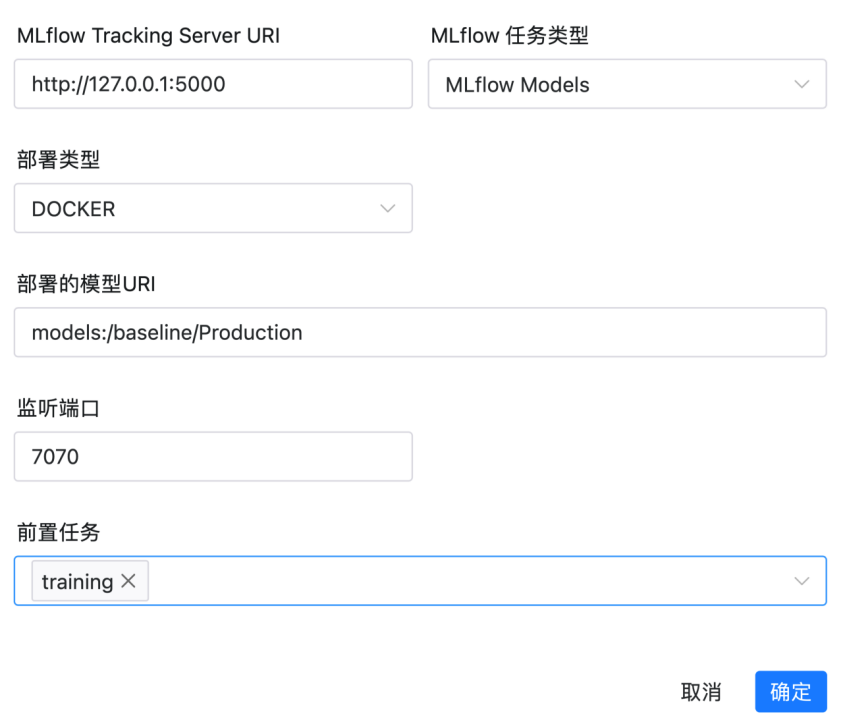
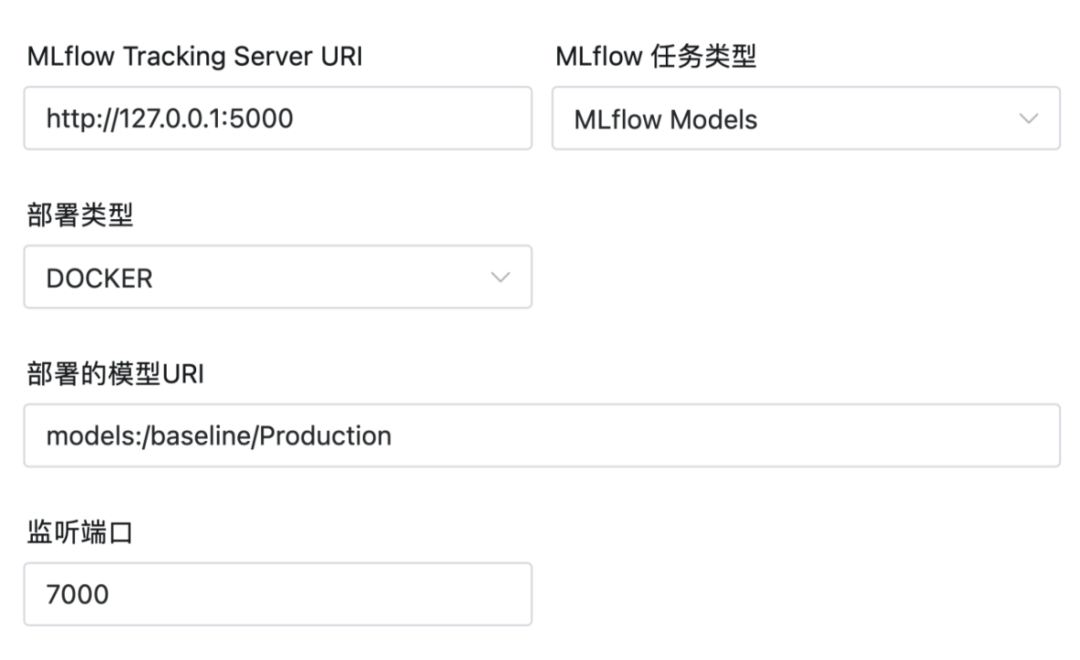
该任务类型为MLflow任务类型,由Apache DolphinScheduler内置提供,可以部署MLflow服务中心的模型。
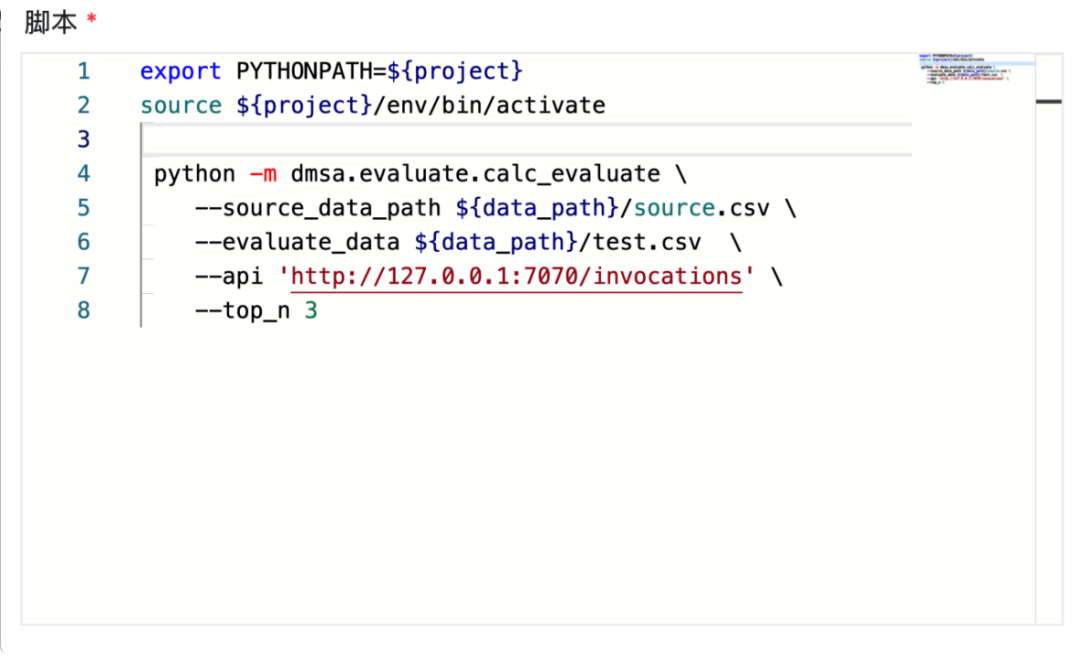
export PYTHONPATH=${project}source ${project}/env/bin/activate
# 表示每天选择分数最高的3个股票,测试效果
python -m dmsa.evaluate.calc_evaluate \--source_data_path ${data_path}/source.csv \--evaluate_data ${data_path}/test.csv \--api 'http://127.0.0.1:7070/invocations' \--top_n 3
# 因此可以简单通过一行命令关闭服务
docker rm -f ds-mlflow-baseline-Production
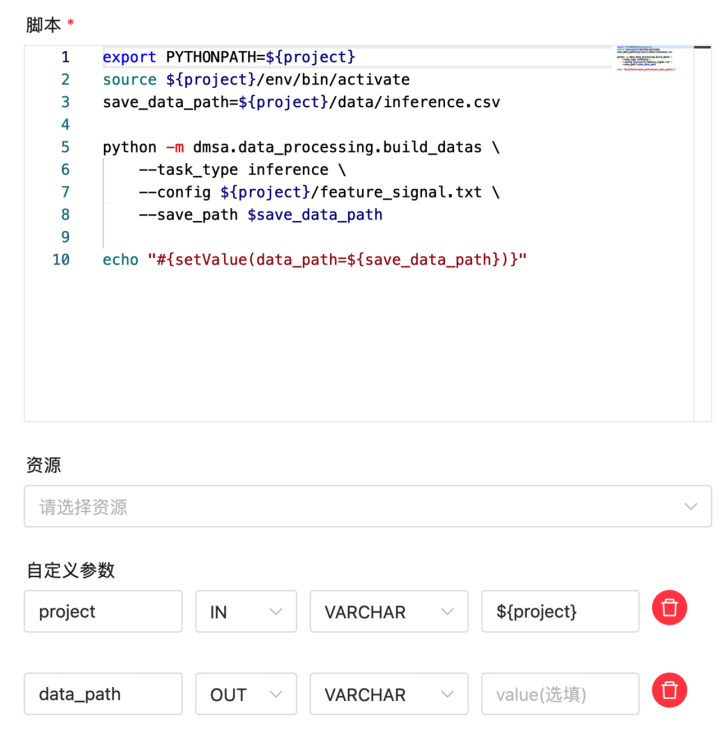
export PYTHONPATH=${project}source ${project}/env/bin/activatesave_data_path=${project}/data/inference.csv
# 用于生成需要推理的数据
python -m dmsa.data_processing.build_datas \--task_type inference \--config ${project}/feature_signal.txt \--save_path $save_data_pathecho "#{setValue(data_path=${save_data_path})}"
export PYTHONPATH=${project}source ${project}/env/bin/activate
python -m dmsa.evaluate.inference \--evaluate_data ${data_path} \--api 'http://127.0.0.1:7000/invocations' \--top_n 10
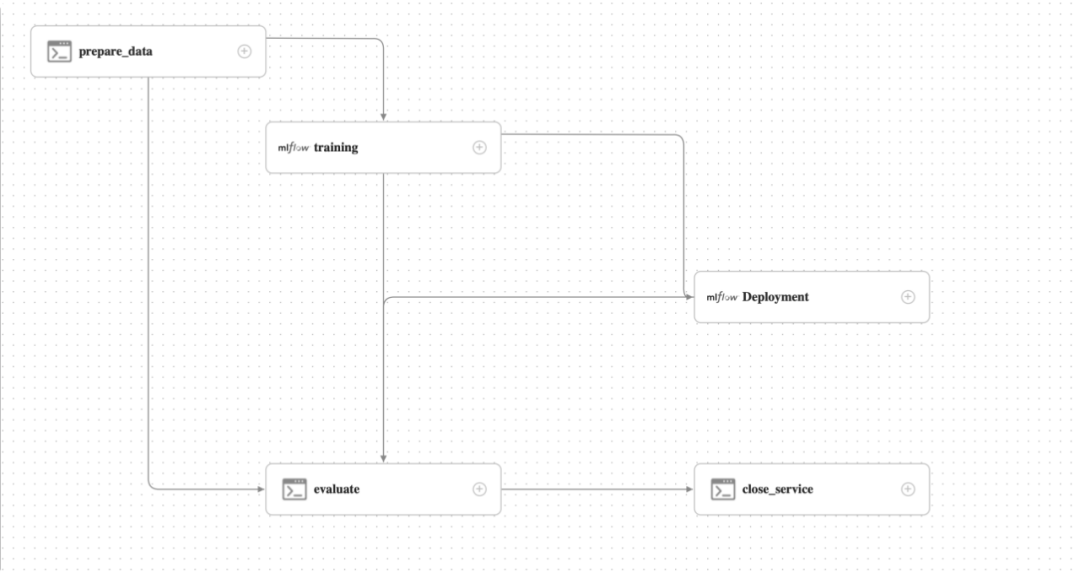
目前包含两个任务,通过 Apache DolphinScheduler 每隔10秒调度启动:
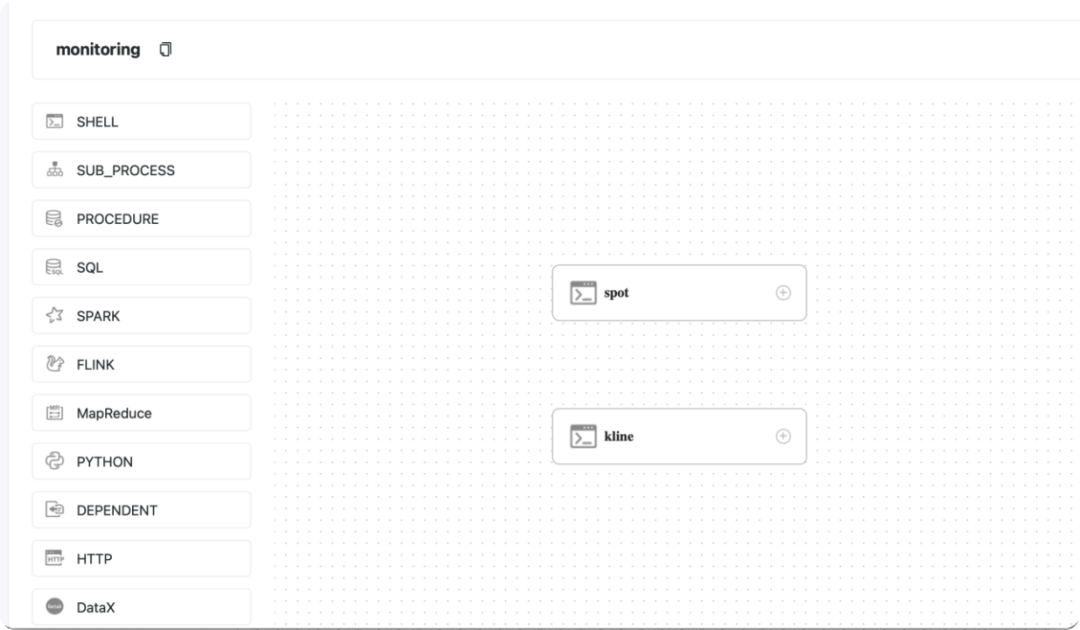
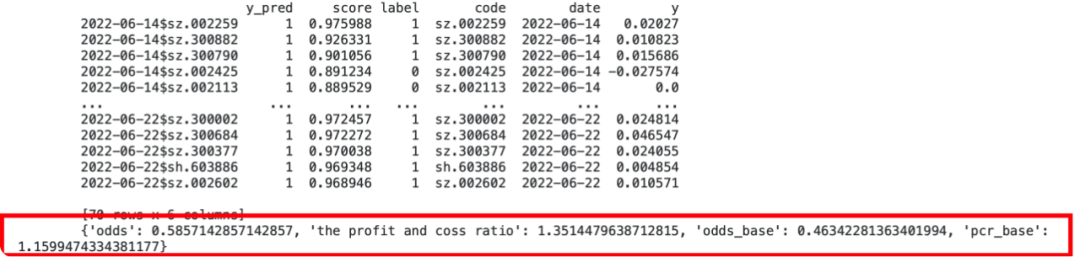
stockDatas = {let i = 0;while (true) {try {const data = await db.query("SELECT a.date, a.y_pred, a.score, b.* FROM candidate a LEFT JOIN spot b ON a.code = b.code WHERE a.y_pred=1;")yield Promises.delay(5000, data);} catch(e){console.log(e.name + ":" + e.message);}}}
stocks = Inputs.table(stockDatas)
Plot.plot({marks: [Plot.ruleY([0]),Plot.lineY(changesDatas, {x: "time", y: "changes"})]})
Plot.plot({marks: [Plot.rectY(stockDatas, Plot.binX({y: "count"}, {x: "涨跌幅"})),Plot.ruleY([0])],})
// 从数据库中读取数据spotDatas = db.query("SELECT * FROM spot;")复制// 画图Plot.plot({marks: [Plot.rectY(spotDatas, Plot.binX({y: "count"}, {x: "涨跌幅"})),Plot.ruleY([0])],x: {ticks: 20}})
2
总结
了解如何使用Apache DolphinScheduler构建一个选股系统。 了解Apache DolphinScheduler灵活简单编排MLOps场景下各个模块的方法。 了解Apache DolphinScheduler MLflow组件赋予用户的0成本使用机器学习能力。 了解Observable这个强大的可视化产品的能力,以及与Apache DolphinScheduler的结合使用。
参与贡献
随着国内开源的迅猛崛起,Apache DolphinScheduler 社区迎来蓬勃发展,为了做更好用、易用的调度,真诚欢迎热爱开源的伙伴加入到开源社区中来,为中国开源崛起献上一份自己的力量,让本土开源走向全球。

参与 DolphinScheduler 社区有非常多的参与贡献的方式,包括:

贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。
社区汇总了以下适合新手的问题列表:https://github.com/apache/dolphinscheduler/issues/5689
非新手问题列表:https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A%22volunteer+wanted%22
如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/docs/development/contribute.html
来吧,DolphinScheduler开源社区需要您的参与,为中国开源崛起添砖加瓦吧,哪怕只是小小的一块瓦,汇聚起来的力量也是巨大的。
参与开源可以近距离与各路高手切磋,迅速提升自己的技能,如果您想参与贡献,我们有个贡献者种子孵化群,可以添加社区小助手微信(Leonard-ds) ,手把手教会您( 贡献者不分水平高低,有问必答,关键是有一颗愿意贡献的心 )。
添加小助手微信时请说明想参与贡献。
来吧,开源社区非常期待您的参与。
更多精彩推荐
☞开源大数据 Studio 应用开发: Apache Dolphinscheduler + Notebook
☞当 Apache DolphinScheduler 遇上 MLOps,机器学习模型部署到生产环境更快、更安全
☞日均 6000+ 实例,TB 级数据流量,Apache DolphinScheduler 如何做联通医疗大数据平台的“顶梁柱”?
我知道你在看哟

