




Databricks官网6月30日发布公告,将开源所有 Delta Lake。
以下为官网摘录内容:
2022年Data+AI峰会的主题是我们正在用Lakehouse构建现代数据栈。数据湖库的一个基本要求是需要为您的数据带来可靠性——一种开放、简单、生产就绪且与平台无关的数据,例如Delta Lake。我们很高兴宣布通过 Delta Lake 2.0,我们将开源所有 Delta Lake!
是什么让 Delta Lake 特别
Delta Lake 使组织能够构建数据湖库,从而直接在数据湖上实现数据仓库和机器学习。但三角洲湖并不止于此。今天,它是 7,000 多个组织使用的最全面的 Lakehouse 格式,每天处理 EB 级数据。除了能够以可靠和高性能的方式无缝摄取和消费流和批处理数据的核心功能之外,Delta Lake 最重要的功能之一是 Delta Sharing,它使不同的公司能够以安全的方式共享数据集。Delta Lake 还带有独立的读取器/写入器,允许任何 Python、Ruby 或 Rust 客户端直接将数据写入 Delta Lake,而无需任何大数据引擎,例如 Apache Spark™。最后,Delta Lake 已经随着时间的推移进行了优化,并且明显优于所有其他 Lakehouse 格式。Delta Lake 带有一组丰富的开源连接器,包括 Apache Flink、Presto 和 Trino。今天,我们很高兴地宣布我们对开源 Delta Lake 的承诺,即开源所有 Delta Lake,包括迄今为止仅在 Databricks 中可用的功能。我们希望这可以使数据湖库的使用和采用民主化。但在我们介绍之前,我们想告诉您三角洲的历史。我们希望这可以使数据湖库的使用和采用民主化。但在我们介绍之前,我们想告诉您三角洲的历史。我们希望这可以使数据湖库的使用和采用民主化。但在我们介绍之前,我们想告诉您三角洲的历史。
Delta Lake 的起源
这个项目的起源始于Dominique Brezinski在 2018 年 Spark 峰会上的一次随意交谈,Apple 的杰出工程师,以及我们自己的 Michael Armbrust(他最初创建了 Delta Lake、Spark SQL 和 Structured Streaming)。负责入侵监控和威胁响应工作的 Dominique 在如何解决由大量并发批处理和流式工作负载(每天 PB 级的日志和遥测数据)所产生的处理需求方面选择了 Michael 的大脑。他们无法将数据仓库用于此用例,因为 (i) 他们拥有的海量事件数据成本过高,(ii) 他们不支持对入侵检测至关重要的实时流式用例,以及 ( iii) 缺乏对高级机器学习的支持,这是检测零日攻击和其他可疑模式所必需的。
因此,他们两人聚在一起讨论数据仓库和人工智能统一的必要性,播下我们现在所知道的 Delta Lake 的种子。在接下来的几个月里,Michael 和他的团队与 Dominique 的团队密切合作,构建了这个旨在解决这个大规模数据问题的摄取架构——使他们的团队能够轻松可靠地处理低延迟流处理和交互式查询,而不会出现作业失败或可靠性问题底层云对象存储系统的问题,同时使 Apple 的数据科学家能够处理大量数据以检测异常模式。我们很快意识到这个问题并不是 Apple 独有的,因为我们的许多客户都遇到了同样的问题。快进,我们开始很快看到 Databricks 客户使用 Delta Lake 轻松地大规模构建可靠的数据湖。我们开始将这种构建可靠数据湖的方法称为数据湖屋模式,因为它提供了数据仓库的可靠性和性能以及海量数据湖的开放性、数据科学和实时能力。
Delta Lake 成为 Linux 基金会项目
随着越来越多的组织开始使用 Delta Lake 构建 Lakehouse,我们听说他们希望数据湖上的数据格式是开源的,从而完全避免供应商锁定。因此,在2019 年 Spark+AI 峰会上,与Linux 基金会一起,我们宣布开源 Delta Lake 格式,以便更大的数据从业者社区可以更好地利用他们现有的数据湖,而不会牺牲数据质量。自从开源 Delta Lake(使用宽松的 Apache 许可证 v2,与我们用于 Apache Spark 的许可证相同)以来,我们已经看到 Delta Lake 开发人员社区的大规模采用和增长,以及从业人员和公司进行的数据旅程的范式转变通过将他们的数据与机器学习和人工智能用例统一起来。这就是我们看到如此巨大的采用和成功的原因。
Delta Lake 社区成长
如今,Delta Lake 项目正在蓬勃发展,拥有来自 70 多个组织的 190 多名贡献者,其中近三分之二来自 Apple、IBM、微软、迪士尼、亚马逊和 eBay 等领先公司的 Databricks 外部贡献者,仅举几例很少。事实上,在过去三年中,我们看到贡献者的实力(由 Linux 基金会定义)增加了 633%。正是这种程度的支持是这个开源项目的核心和力量。
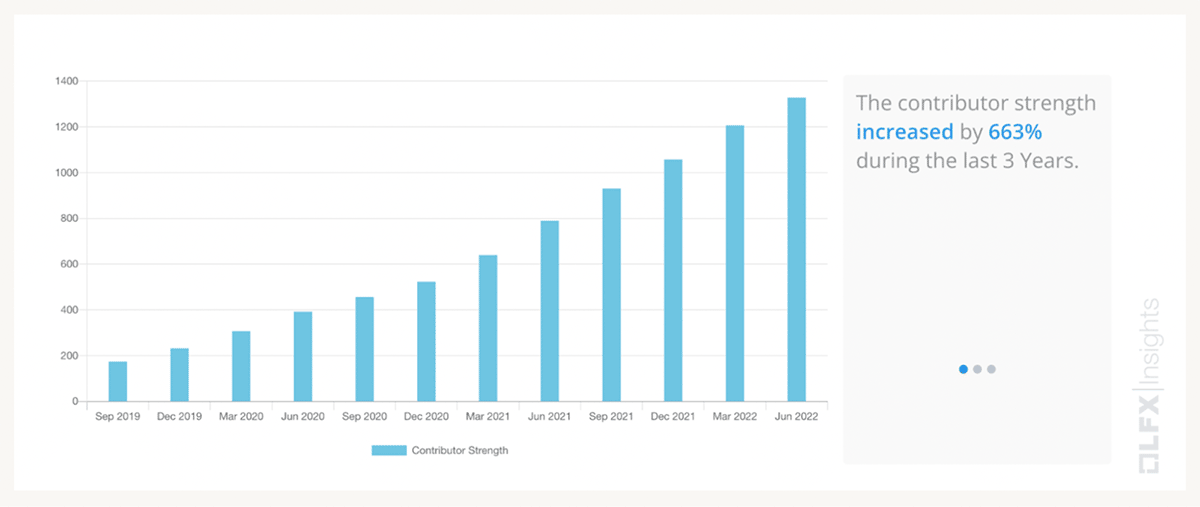
资料来源:Linux 基金会贡献者力量:过去三年分析的独特贡献者总数的增长。贡献者是通过任何代码活动(提交/PR/变更集)或帮助查找和解决错误与项目相关联的任何人。
Delta Lake:最快最先进的多引擎存储格式
Delta Lake 不仅为一家科技公司的特殊用例而构建,还为代表我们客户和社区广度的各种用例而构建,从金融、医疗保健、制造、运营到公共部门。Delta Lake 已在数以 EB 为单位的最大表中进行了数千次部署和实战测试。因此,Delta Lake 一次又一次地出现在现实世界的客户测试和第三方基准测试中,在性能和易用性方面远远领先于其他格式1 。
使用 Delta Sharing,任何人都可以轻松地轻松共享数据并读取从其他 Delta 表共享的数据。我们在 2021 年发布了 Delta Sharing,为数据社区提供了摆脱供应商锁定的选择。随着数据共享变得越来越流行,由于专有数据格式和读取数据所需的专有计算,你们中的大多数人对更多数据孤岛(现在甚至在组织外部)表示沮丧。Delta Sharing 引入了一种开放协议,用于安全实时交换大型数据集,首次实现跨产品的安全数据共享。数据用户现在可以通过 Pandas、Tableau、Presto、Trino 或其他数十个实现开放协议的系统直接连接到共享数据,而无需使用任何专有系统——包括 Databricks。
Delta Lake 还拥有最丰富的直接连接器生态系统,例如Flink、Presto和Trino,使您能够直接从最流行的引擎读取和写入 Delta Lake,而无需 Apache Spark。感谢来自Scribd和Back Market的 Delta Lake 贡献者,您还可以使用Delta Rust ——Rust 中的一个基础 Delta Lake 库,它使 Python、Rust 和 Ruby 开发人员能够在没有任何大数据框架的情况下读写 Delta。如今,Delta Lake 是世界上使用最广泛的存储层,每月下载量超过 700 万次;在短短一年内,每月下载量增长了 10 倍。
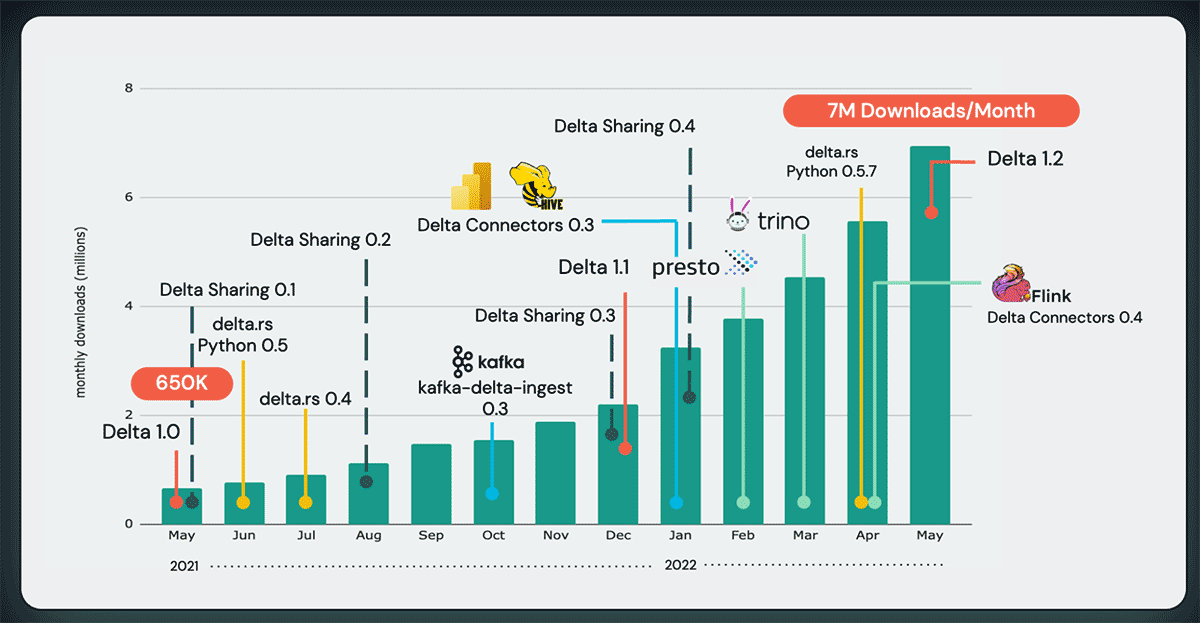
宣布 Delta 2.0:将一切都带入开源
Delta Lake 2.0 是 Delta Lake 的最新版本,它将进一步使我们的庞大社区能够从所有 Delta Lake 创新中受益,所有 Delta Lake API 都是开源的——特别是像ZOrder这样的 Delta Engine 带来的性能优化和功能,更改数据馈送、动态分区覆盖和删除的列。由于这些新功能,Delta Lake 继续为从流式处理到批处理的所有 Lakehouse 工作负载提供无与伦比的开箱即用的性价比——与其他存储层相比,速度提高了 4.3 倍。在过去的六个月中,我们花费了大量精力来提升所有这些性能并将它们贡献给 Delta Lake。因此,我们开源了 Delta Lake 的所有资源,并致力于确保 Delta Lake 的所有功能都将继续开源。
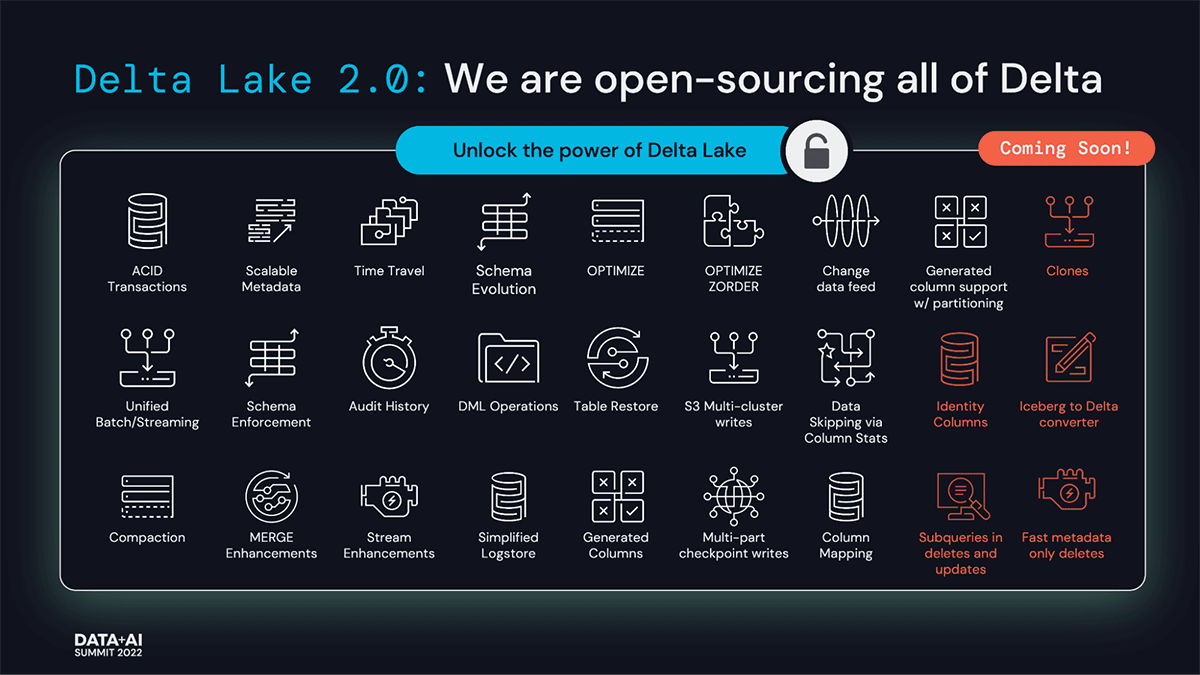
我们很高兴看到 Delta Lake 不断壮大。我们期待与您合作,在未来几年继续快速创新和采用 Delta Lake。
文章来源:https://databricks.com/blog/2022/06/30/open-sourcing-all-of-delta-lake.html
