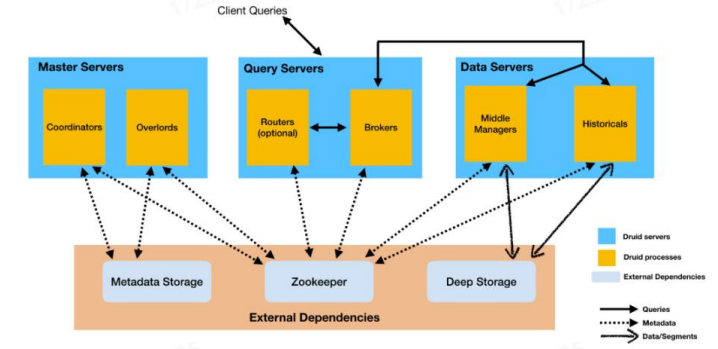
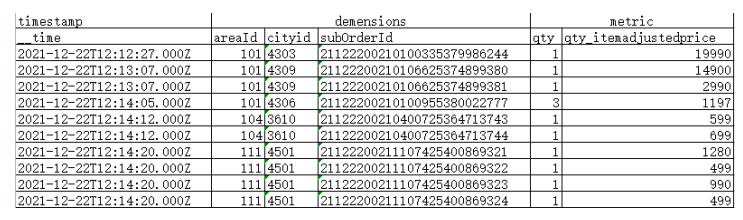
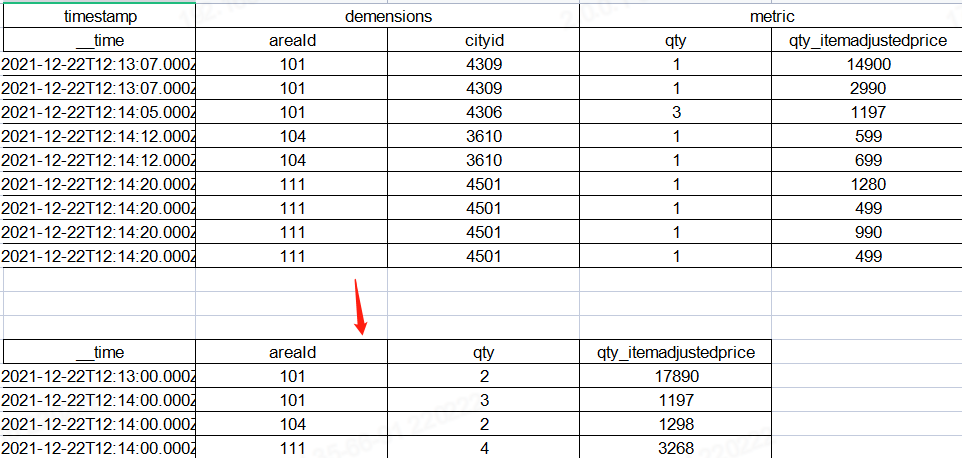
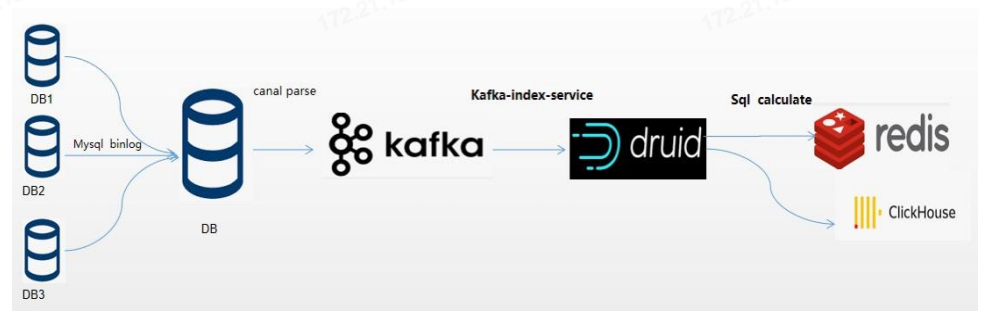
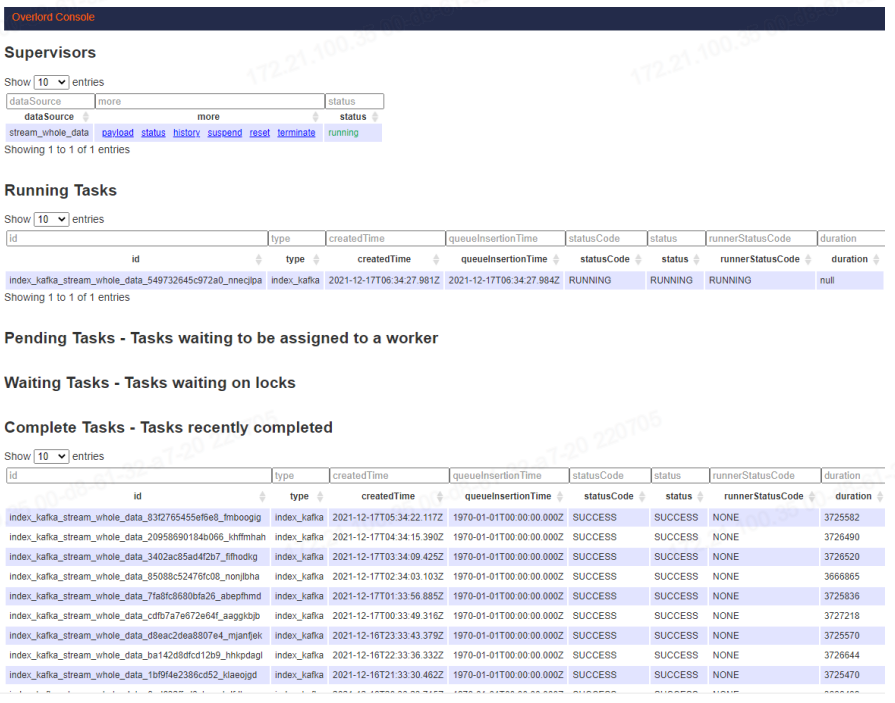
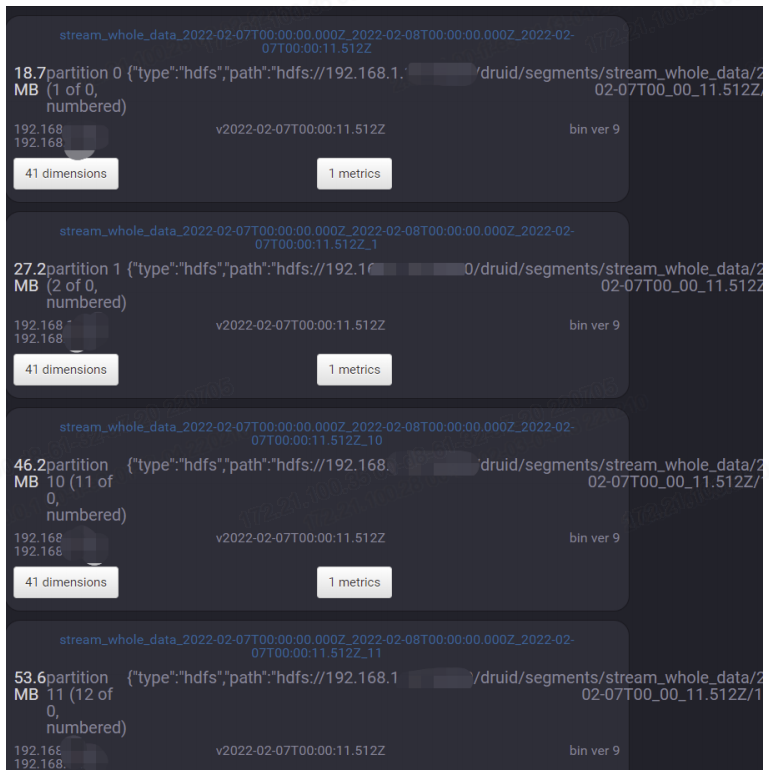
Druid在架构设计上借鉴了LSM-tree及读写分离的思想,并且基于DataSource与Segment数据文件结构与组织方式,通过数据的预聚合,优化存储结构和内存使用,即提供了实时和离线批量数据摄入的能力,又能够在大规模数据集上实现高效实时数据消费与探索,在时序数据应用场景中满足了OLAP的核心功能。但Druid是一套比较复杂的分布式系统,为实现其完整的集群功能,不仅需要要熟悉Broker,Historical,MiddleManager,Coordinator等集群节点进程功能,优化各节点机器配置及对应的JVM与线程池配置,还要面对其外部依赖DeepStorage(HDFS),ZooKeeper,MetadataStorage,可能出现直接或间接影响Druid有效运行的各种问题,因而整套系统有较高的运维成本。这些都是我们在做技术选型时需要考虑的因素。 参考文献:[1]https://druid.apache.org/docs/latest/design/architecture.html[2]http://static.druid.io/docs/druid.pdf[3]F.Chang,J.Dean,S.Ghemawat,W.C.Hsieh,D.A.Wallach,M.Burrows,T.Chandra,A.Fikes,andR.E.Gruber.Bigtable:A distributed storage system for structured data.ACM Transactions on Computer Systems (TOCS),26(2):4,2008.