




Kettle常用控件介绍
输入控件
输出控件
更新:把数据库已经存在的记录与数据流里面的记录进行比对,如果不同就进行更新,这里需要注意的是,如果记录不存在,则会出现错误
插入/更新:插入更新就是把数据库已经存在的记录与数据流里面的记录进行比对,如果不同就进行更新,如果记录不存在,则会插入数据
转换控件
Concat fields:多个字段连接起来形成一个新的字段
值映射:把字段的一个值映射成其他的值,最常见就是字典转换
增加常量:在本身的数据流里面添加一列数据,该列的数据都是相同的值
增加序列:给数据流添加一个序列字段
字段选择:从数据流中选择字段、改变名称、修改数据类型
计算器:是一个函数集合来创建新的字段,还可以设置字段是否移除(临时字段)
剪切字符串:指定输入流字段裁剪的位置剪切出新的字段
字符串替换:指定搜索内容和替换内容,如果输入流的字段匹配上搜索内容就进行替换生成新字段
字符串操作:去除字符串两端的空格和大小写切换,并生成新的字段
排序记录:按照指定的字段的升序或降序对数据流排序
去除重复记录:去除数据流里面相同的数据行(使用前先对数据流进行排序)
唯一行(哈希值):删除数据流重复的行,和排序记录+去除重复记录效果一样的,但是实现的原理不同,唯一行(哈希值)执行的效率会高一些
拆分字段:把字段按照分隔符拆分成两个或多个字段,需要注意的是,拆分字段后,原字段就不存在于数据流中
列拆分为多行:把指定分隔符的字段进行拆分为多行
列转行:如果数据一列有相同的值,按照指定的字段,把多行数据转换为一行数据(使用前先对数据流进行排序)
转换成

行转列:把数据字段的字段名转换为一列,把数据行变为数据列(和列转行相反)
行扁平化:把同一组的多行数据合并成为一行(只有数据流的同类数据数据行记录一致的情况才可使用,使用前先对数据流进行排序)
 转换成
转换成
应用控件
替换NULL值:把null转换为其它的值(NULL值不好进行数据分析)
写日志:主要是在调试的时候使用,把日志信息打印到日志窗口
发送邮件:在执行成功、失败、其它某种情景给相关人员发送邮件(只支持企业邮箱)
流程控件
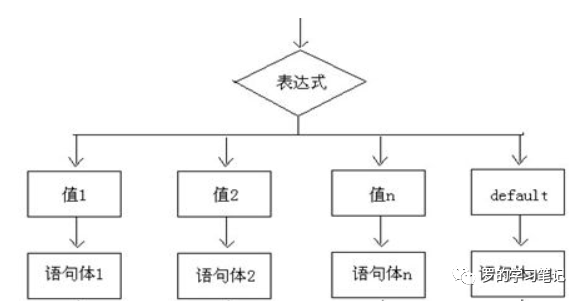
Switch/case:让数据流从一路到多路
过滤记录:让数据流从一路到两路
中止:是数据流的终点,如果有数据到这里将会报错,可以用来校验数据的时候使用
查询控件
HTTP client:使用GET的方式提交请求,获取返回的页面内容
数据库查询:相当于数据库里面的左连接
数据库连接:可以执行两个数据库的查询,和单参数的表输入
流查询:在查询前把数据都加载到内存中,并且只能进行等值查询
连接控件
合并记录:是用于将两个不同来源的数据合并,这两个来源的数据分别为旧数据和新数据,该步骤将旧数据和新数据按照指定的关键字匹配、比较、合并
--标志字段:设置标志字段的名称,标志字段用于保存比较的结果,比较结果有下列几种
“identical” – 旧数据和新数据一样
“changed” – 数据发生了变化
“new” – 新数据中有而旧数据中没有的记录
“deleted” –旧数据中有而新数据中没有的记录
合并后的数据将包括旧数据来源和新数据来源里的所有数据,对于变化的数据,使用新数据代替旧数据,同时在结果里用一个标示字段,来指定新旧数据的比较结果
旧数据和新数据需要事先按照关键字段排序
旧数据和新数据要有相同的字段名称
记录关联:对两个数据流进行笛卡尔积操作
记录集连接:等同数据库的左连接、右连接、内连接、外连接(使用前先对数据流进行排序)
统计控件

分组:按照某一个或某几个进行分组,同时可以将其余字段按照某种规则进行合并(使用前先对数据流进行排序)
映射控件

映射(子转换):用来配置子转换,对子转换进行调用的一个步骤
映射输入规范:输入字段,由调用的转换输入
映射输出规范:向调用的转换输出所有列,不做任何处理
脚本控件
javascript脚本:使用javascript代码编程来完成对数据流的操作,存在两种不同的模式:不兼容模式和兼容模式,不兼容模式是默认的,也是推荐的;兼容模式兼容老版本的kettle
java脚本:使用java代码编程来完成对数据流的操作,Main函数对应一个processRow()函数,processRow()函数是用来处理数据流的场所
执行SQL脚本:可以执行一个update语句,用来更新某个表中的数据
Kettle中的作业
作业的组成
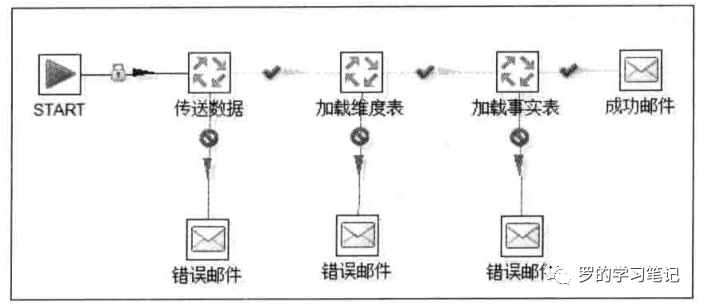
作业项:是作业的基本构成部分,如同转换的步骤,作业项也可以使用图标的方式图形化展示。如果你再仔细观察,还是会发现作业项有一些地方不同于步骤:在作业项之间可以传递一个结果对象(result object),这个结果对象里面包含了数据行,它们不是以数据流的方式来传递的。而是等待一个作业项执行完了,再传递给下一个作业项
因为作业顺序执行作业项,所以必须定义一个起点。有一个叫“开始”的作业项就定义了这个点,一个作业只能定一个开始作业项
作业跳:是作业项之间的连接线,它定义了作业的执行路径。作业里每个作业项的不同运行结果决定了做作业的不同执行路径
无条件执行:不论上一个作业项执行成功还是失败,下一个作业项都会执行。这是一种蓝色的连接线,上面有一个锁的图标
当运行结果为真时执行:当上一个作业项的执行结果为真时,执行下一个作业项。通常在需要无错误执行的情况下使用。这是一种绿色的连接线,上面有一个对钩号的图标
当运行结果为假时执行:当上一个作业项的执行结果为假或者没有成功执行时,执行下一个作业项。这是一种红色的连接线,上面有一个红色的停止图标
Kettle中的参数
全局参数:是通过当前用户下.kettle文件夹中的kettle.properties文件来定义,采用KeyValue对方式来定义,在定义后需要重启Kettle才会生效
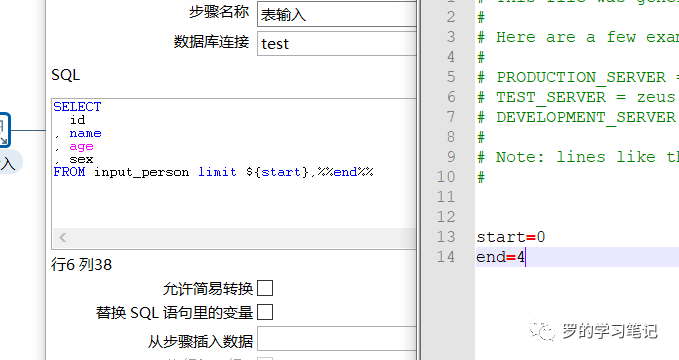
参数使用方法有两种:一种是%%变量名%%,一种是${变量名},在SQL中使用变量时需要把“是否替换变量”勾选上,否则无法使变量生效
局部参数:
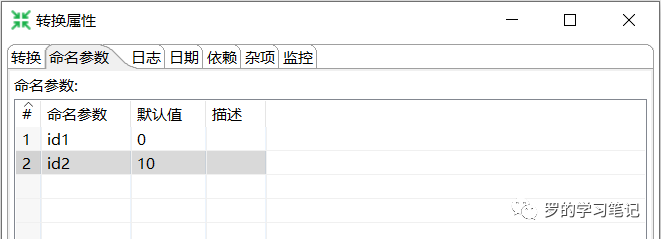
转换命名参数:在转换内部定义的变量,作用范围是在转换内部(在转换的空白处右键,选择转换设置就可以看见)
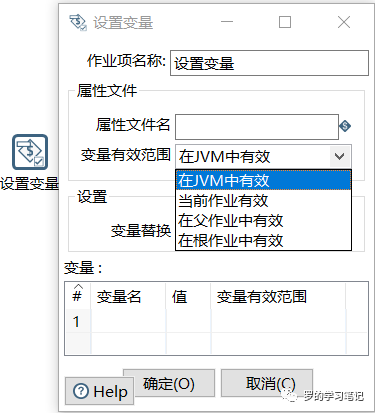
转换内设置变量和获取变量:在转换里面有一个作业分类,里面有设置变量和获取变量的步骤,需要注意的是,“设置变量”在当前转换当中是不能马上使用,需要在作业中的下一步骤中使用

作业内设置变量:变量可以在转换里面设置,也可以在作业里面设置
Kettle的介绍就到这里,希望可以坚持下去,分享一些更有内涵的技术
