




ETL是什么?
ETL(Extract-Transform-Load的缩写,即数据抽取、转换、装载的过程),对于企业或行业应用来说,我们经常会遇到各种数据的处理、转换、迁移,所以了解并掌握一种ETL工具的使用必不可少,这里我要介绍的ETL工具是Kettle。
ETL工具—kettle
Kettle的结构
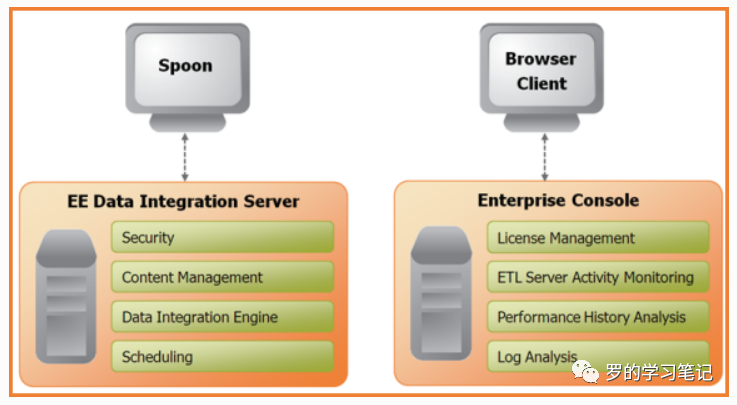
Spoon:Spoon是构建ETL Jobs和Transformations的工具。Spoon以拖拽的方式图形化设计,能够通过spoon调用专用的数据集成引擎或者集群。
Data Integration Server:是一个专用的ETL Server,主要功能有
功能 描述 执行 通过Pentaho Data Integration引擎执行ETL的作业或转换 安全性 管理用户、角色或集成的安全性 内容管理 提供一个集中的资源库(包含所有内容和特征的历史版本),用来管理ETL的作业和转换 时序安排 在Spoon设计者环境中提供管理Data Integration Server上的活动的时序和监控的服务 Enterprise Console:提供了一个小型的客户端,用于管理Pentaho Data
Integration企业版的部署,包括企业版本的证书管理、监控和控制远程Pentaho Data Integration服务器上的活动、分析已登记的作业和转换的动态绩效。
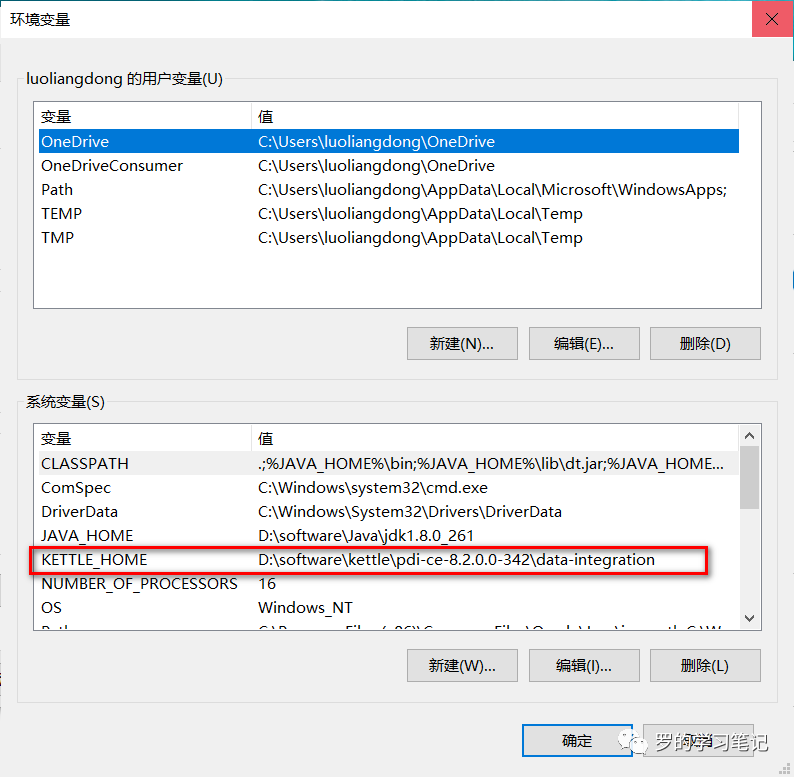
Kettle的安装
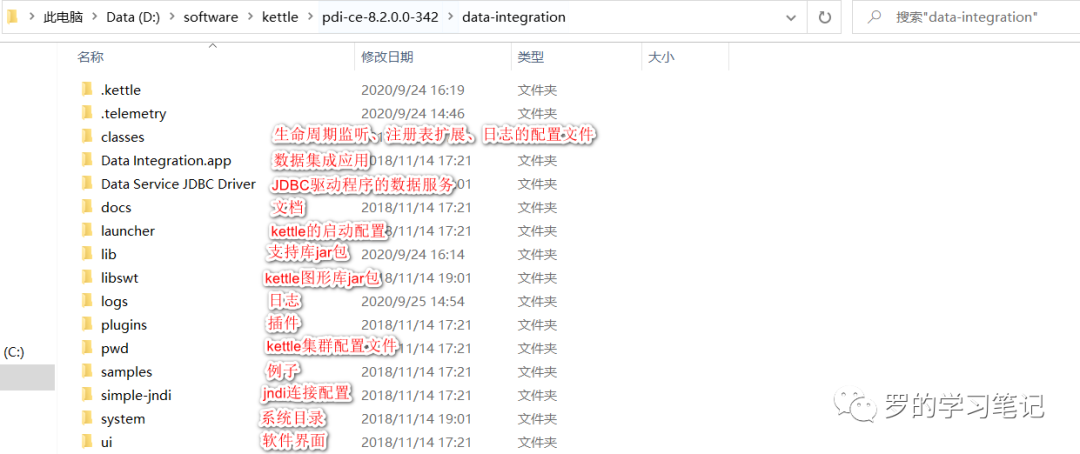
Kettle的目录结构
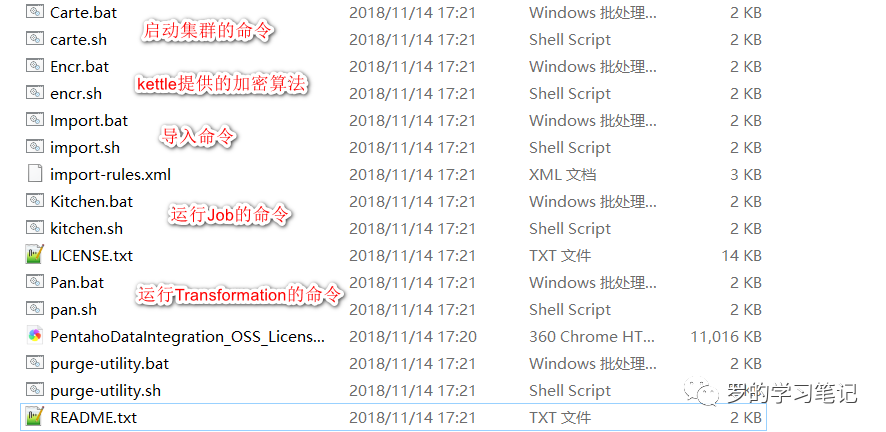
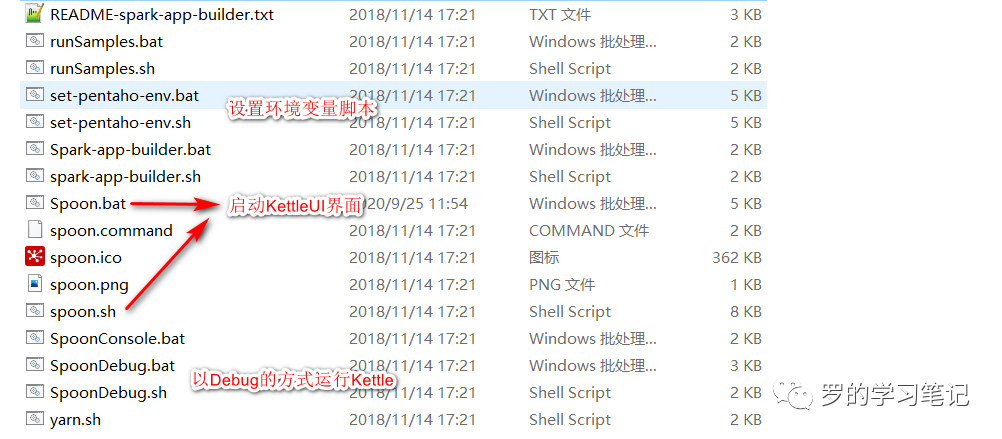
Kettle界面
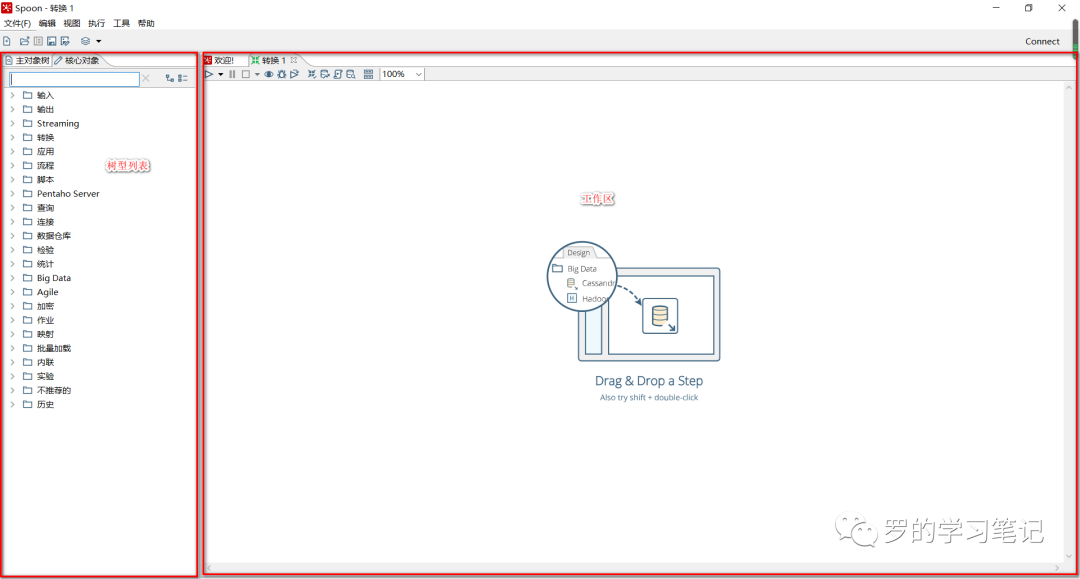
Kettle小试

转换控件
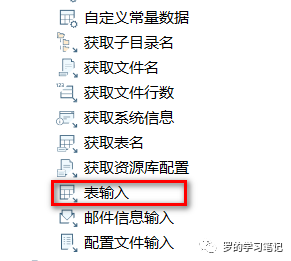
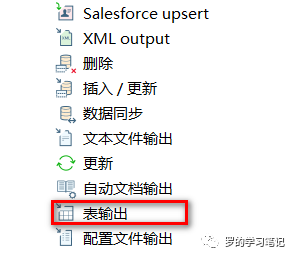
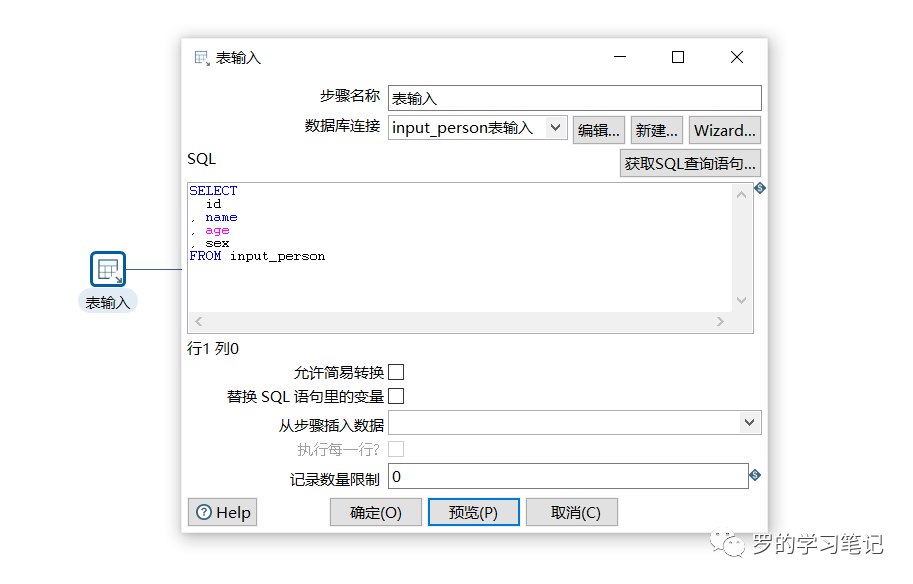
表输入
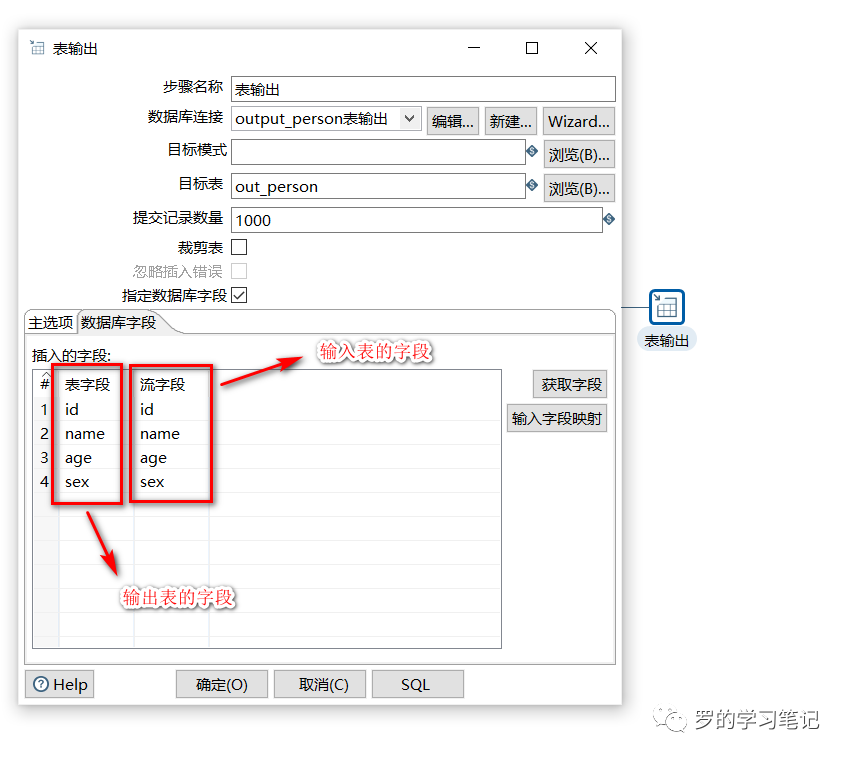
表输出
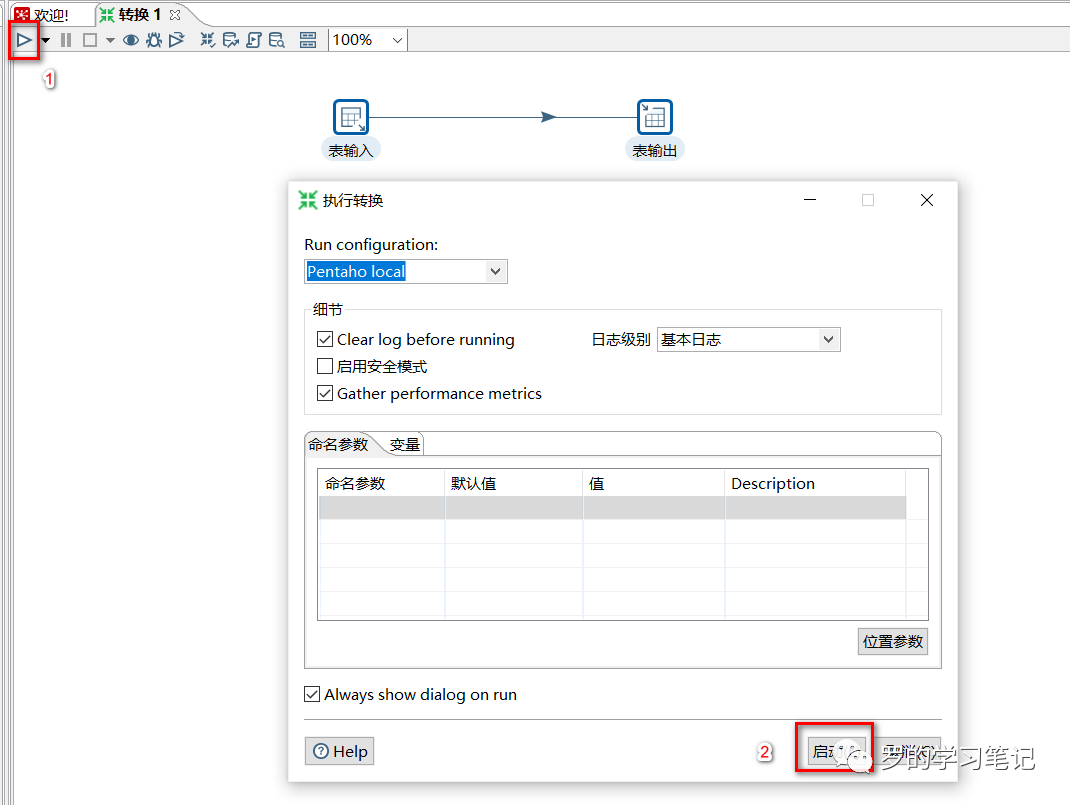
运行
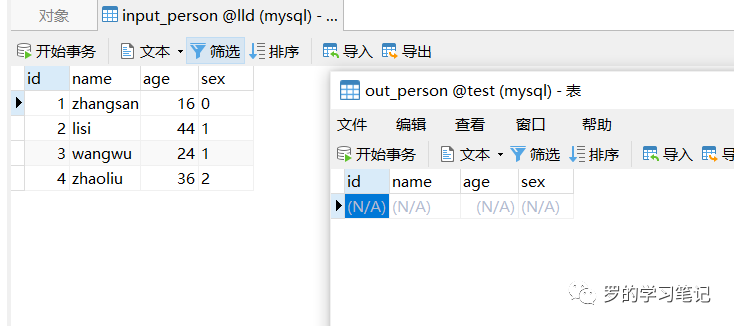
运行前表input_person和表output_perosn
运行日志
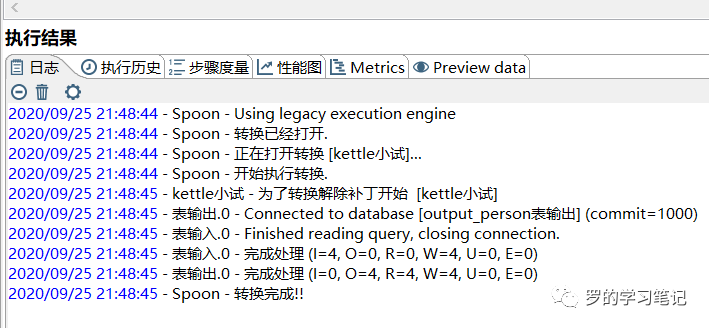
运行后表input_person和表output_perosn
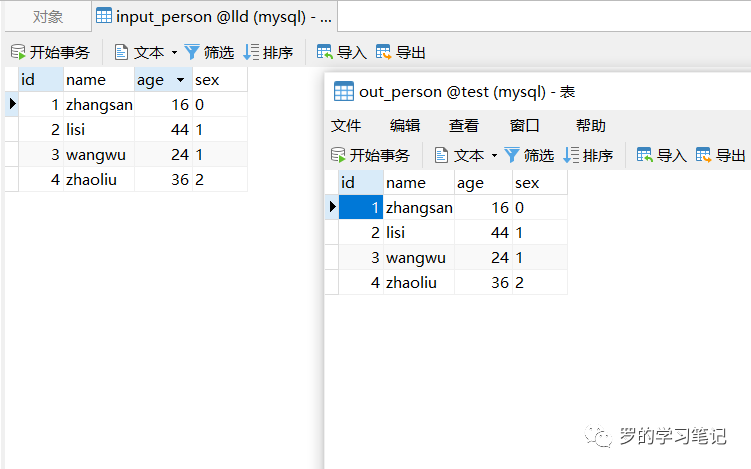
可以看到,数据已经从lld数据库的input_person表复制到test库的output_person表
总结一下kettle的核心概念
可视化编程
转换
Step步骤
一个步骤有如下几个关键特性:
步骤需要有一个名字,这个名字在转换范围内唯一。 每个步骤都会读、写数据行(唯一例外是“生成记录”步骤,该步骤只写数据)。
步骤将数据写到与之相连的一个或多个输出跳,再传送到跳的另一端的步骤。
大多数的步骤都可以有多个输出跳。一个步骤的数据发送可以被被设置为分发和复制,分发是目标步骤轮流接收记录,复制是所有的记录被同时发送到所有的目标步骤。
Hop跳
跳就是步骤之间带箭头的连线,跳定义了步骤之间的数据通路。跳实际上是两个步骤之间的被称之为行集的数据行缓存(行集的大小可以在转换的设置里定义)。当行集满了,向行集写数据的步骤将停止写入,直到行集里又有了空间。当行集空了,从行集读取数据的步骤停止读取,直到行集里又有可读的数据行。
数据行
并行
