




1、消息队列解决的问题
1.1、 削峰填谷
顾名思义就是保证服务性能的稳定,防止在并发高峰的时候响应性能变慢以及在低峰期服务器资源的浪费。在业务高峰期的时候大量的请求被同时转发到服务器,可能会导致服务响应变慢阻塞其他事务,甚至导致服务崩溃,而如果单纯的靠增加服务器资源来提高性能只是治标不治本且会导致在空闲时服务器资源大量闲置。消息队列能够将所有的请求信息按主题存放,消息消费者按自己能力去处理消息。而对于请求方可以给个响应,保证其能在一段时间内得到消息处理结果即可。
1.2、 解耦
如果存在多个系统相互关联的情况下,可以使用消息队列作为上下游系统之间的中心。消费者只需保证消息成功存入消息队列接口得到响应即可。消息队列只需保证数据的最终一致性即可。
1.3、 异步
在一些有很多步骤的事务中,可以将不同的事务分别提交到消息队列中。消费者异步读取消息进行消费。
2、RocketMq设计
2.1、整体设计
RocketMq的设计基于主题的发布与订阅模式,如图3.2.1所示,主要由Producer、NameServer、Consumer、Broker四个模块组成,核心功能包括消息发送、消息存储、消息消费。
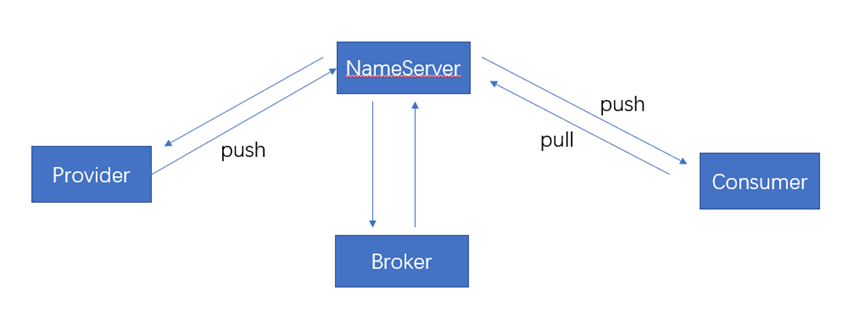
图2.1.1 RocketMq整体架构
Broker:负责消息的存储、投递和查询以及服务的高可用保证,在实际服务部署中一个Broker对应一台服务器,每个Broker可以有多个Topic,一个Topic也可以分片存储在多个Broker上。
NameServer:类似于Dubbo里的zookeeper,支持Broker的动态注册与发现。多个NameServer实例组成集群但相互独立没有信息交换。每个Broker会和所有的NameServer节点建立一个长连接,定时发送心跳包给NameServer,心跳包内容包括Broker的地址、id、集群名称、topic等信息。路由信息管理,每个NameServer将保存关于Broker集群的整个路由信息和用于客户端查询的队列信息。然后Producer和Conumser通过NameServer就可以知道整个Broker集群的路由信息,从而进行消息的投递和消费。
Producer:Producer与NameServer中的一个随机节点建立长连接,定期获取Topic的路由信息,并向提供topic服务的Broker master建立长连接,定时发送心跳。
Consumer:consumer 与 nameserver中随机一个节点建立长连接,定期获取Topic的路由信息,并向提供topic服务的Broker master 和slave建立长连接,定时发送心跳。Consumer既可以向master订阅服务,也可以向slave订阅服务,消费者在向Master拉取消息时,Master服务器会根据拉取偏移量与最大偏移量的距离(判断是否读老消息,产生读I/O),以及从服务器是否可读等因素建议下一次是从Master还是Slave拉取。可以由多个consumer组成消费者组。每个消费组都消费主题中一份完整的消息,不同消费组之间消费进度彼此不受影响,也就是说,一条消息被 Consumer Group1 消费过,也会再给 Consumer Group2 消费。对于同一个消费者组,一个队列同时只能由一个消费者进行消费。
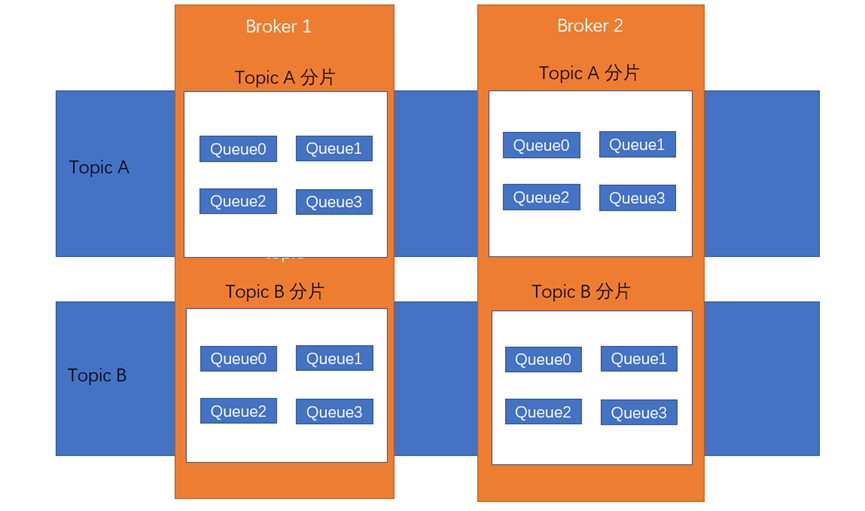
图2.1.2 Topic存储
完整的集群工作流程如下:
1、NameServer运行,监听服务端口,等待Broker、Producer、Consumer连接;
2、Broker启动,跟所有NameServer保持长连接,定时发送心跳包(包含broker信息和注册Topic信息)
3、创建Topic(可用bin目录下的mqadmin工具进行创建),创建Topic时需要指定该Topic存储在哪个Broker上,也可以在发送消息时自动创建Topic。
4、Producer发送消息,启动时先跟NameServer集群中的其中一台建立长连接,并从NameServer中获取当前发送的Topic存在哪些Broker上,按一定策略从队列列表中选择一个队列,(因为一个Topic可能存在好几个Broker上,每个Broker上针对每个Topic存在多个Queue,如图3.2.2所示,这样就可以并行的进行消息的生产和消费)然后与队列所在的Broker建立长连接从而向Broker发消息。
5、Consumer跟Producer类似,跟其中一台NameServer建立长连接,获取当前订阅Topic存在哪些Broker上,然后直接跟Broker建立连接通道,开始消费消息。
2.2 、存储设计
RocketMq的消息存储主要由CommitLog、ConsumeQueue、IndexFile三个文件构成。
CommitLog
Producer端写入的消息主体以顺序方式写入CommitLog文件,单个Broker实例下的所有队列实例共用一个CommitLog文件(这意味着多个Topic消息实体内容都存储在同一个CommitLog中),单个文件大小默认1G,当文件满了写入下一个文件。文件名长度为20位,左边补零剩余为起始偏移量,比如00000000000000000000代表了第一个文件,起始偏移量为0,文件大小为1G=1073741824;当第一个文件写满了,第二个文件为00000000001073741824,起始偏移量为1073741824,以此类推。
ComsumeQueue
消息在落到CommitLog后,会异步地将消息CommitLog中的起始物理偏移量offset,消息大小size和消息Tag的HashCode值存到ConsumeQueue中。ConsumeQueue文件可以看成是基于topic的CommitLog索引文件。组织方式如下:topic/queue/file三层组织结构,具体存储路径为:$HOME/store/consumequeue/{topic}/{queueId}/{fileName}。ConsumeQueue文件同样采用定长设计,每一个条目共20个字节,分别为8字节的Commitlog物理偏移量、4字节的消息长度、8字节tag hashcode。
IndexFile
消息索引文件,主要存储消息 Key 与 Offset 的对应关系。Index文件的存储位置是:$HOME \store\index${fileName},文件名fileName是以创建时的时间戳命名的,固定的单个IndexFile文件大小约为400M,一个IndexFile可以保存 2000W个索引,IndexFile的底层存储设计为在文件系统中实现HashMap结构,故rocketmq的索引文件其底层实现为hash索引。
3、可靠性
3.1、 消息有序性
RocketMq本身只保证在队列中的有序性,因此如果要确保全局消息的有序性时,只能使每个Topic的队列数为1(这样就失去了高并发和吞吐的优势)。在大部分场景下其实只需要保证部分消息有序就好了,因此对于需要保证顺序性的这部分消息必须发送到同一个topic下的同一个队列里。
在第2节中说到,多个消费者可以组成消费者组,不同消费者组可以并行地进行消息消费,因此会存在一条消息同时被属于不同消费者组的消费者消费的情况。Broker会针对每个消费者对队列中消息的消费维持一个消费的偏移量以确保不同消费进度的消费能够正常进行。此时,Broker只有在一条消息收到所有的消费者的消费成功确认后才会认为已经被成功消费了,才会移除这条信息。
3.2 、消息丢失
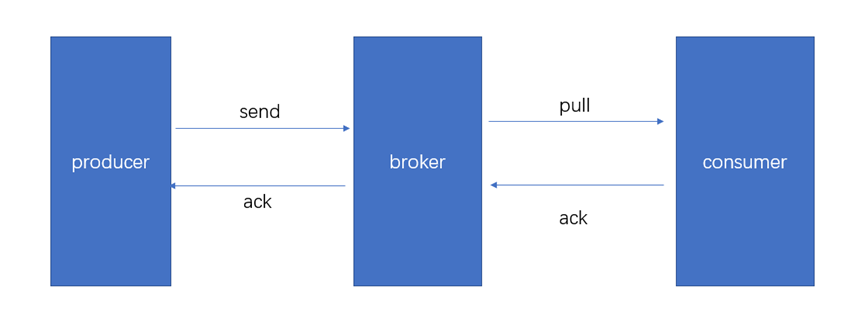
图3.2.1 消息确认
如图3.2.1所示,生产者在将信息发送给broker,当broker将接收到的信息成功落到CommitLog 中和ConsumeQueue中后才会向生产者发送一个确认,生产者只有在收到消息的确认后才认为消息已经发送成功,否则若在一定的时间内没有收到确认则会重试发送消息,若重试仍然出错则抛出异常。这样基本能够保证在消息生产过程中不会有消息丢失。同样消费者只有在成功消费消息后才会向broker发送确认。
3.3、消息重复
如3.1节中所说为了防止消息丢失,broker需要向生产者发送收到消息的确认,消费者需要向broker发送消费成功的确认。但是如果因为网络问题导致确认信息被阻塞或者丢失,则会导致消息重复。为了防止消息重复被消费,消费者需要确保消息消费的幂等性(使业务操作本身具有幂等性;或者维护一个消费记录,每次消费前去查询是否消费过;再或者利用数据库的唯一性约束来保证幂等)。
