




注意看下图,本文中,生产者的所有的模式选择,发送原理,都将会在下图的基础上展开讨论。
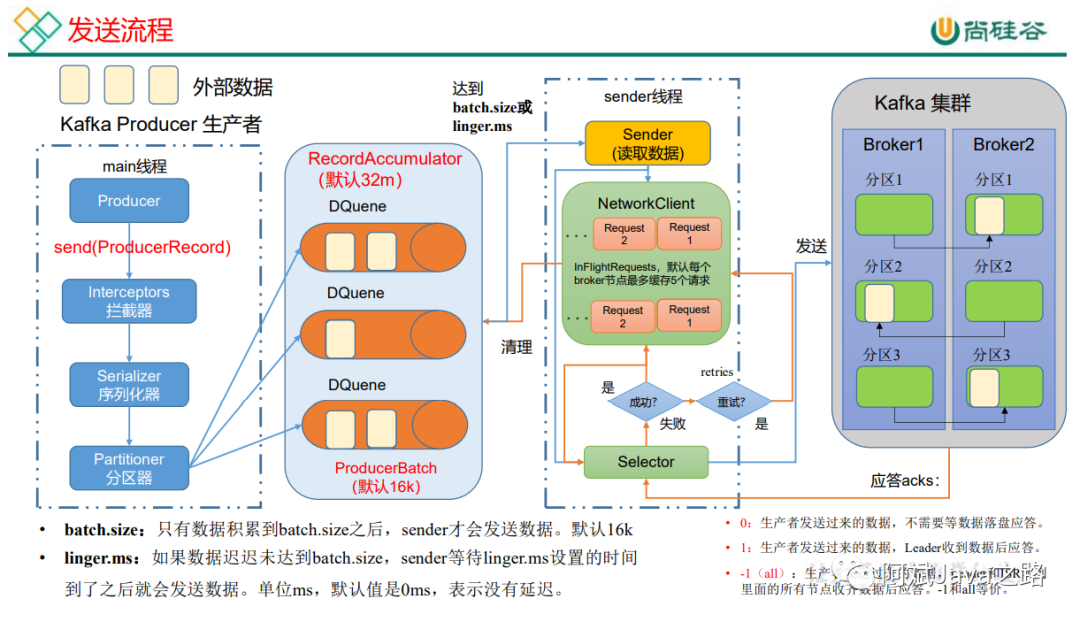
发送流程
在消息发送的过程中,涉及到两个线程,main线程和sender线程,其中main线程是消息的生产线程,而sender线程是jvm单例的线程,专门用于消息的发送。
在jvm的内存中开辟了一块缓存空间叫RecordAccumulator(消息累加器),用于将多条消息合并成一个批次,然后由sender线程发送给kafka集群。
我们的一条消息在生产过程会调用send方法然后经过拦截器经过序列化器,再经过分区器确定消息发送在具体topic下的哪个分区,然后发送到对应的消息累加器中,消息累加器是多个双端队列。并且每个队列和主题分区都具有一一映射关系。消息在累加器中,进行合并,达到了对应的size(batch.size)或者等待超过对应的等待时间(linger.ms),都会触发sender线程的发送。sender线程有一个请求池,默认缓存五个请求( max.in.flight.requests.per.connection ),发送消息后,会等待服务端的ack,如果没收到ack就会重试默认重试int最大值( retries )。如果ack成功就会删除累加器中的消息批次,并相应到生产端。
后面将会具体刨析其中的每个环节具体的细节。
消息发送模式
kafka的消息发送,其实返回的并不是一个void,而是一个future对象。
Future<RecordMetadata> send(ProducerRecord<K, V> record);
Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback);
发后即忘
try {
producer.send(record);
} catch (ExecutionException I InterruptedException e) {
e.printStackTrace();
}
该方式不关心消息的发送结果,所以有可能发送失败。
同步发送
try {
producer.send(record).get();
} catch (ExecutionException I InterruptedException e) {
e.printStackTrace();
}
发送消息后,立马调用同步的get方法,等待消息成功。同步发送的可靠性会更高,要么消息发送成功,要么发送失败抛出异常,根据异常做出相应的处理,回滚也好,补偿也好。不过阻塞等待结果会影响性能,需要发完一条收到结果再发送下一条。
异步发送
kafkaProducer.send(new ProducerRecord<>("first", "atguigu" + i), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null){
System.out.println("主题:"+metadata.topic() + " 分区:"+ metadata.partition());
}
}
});
异步发送,采用了callback的方式来回调,提高了消息发送的吞吐量,也一定程度的提高了消息的可靠性,根据回调的结果来判断是否需要做相应的回滚逻辑。
生产者拦截器 (ProducerInterceptor)
拦截器接口一共有三个方法。三个方法内的实现如果抛出异常,会被ProducerInterceptors内部捕获,并不会抛到上层。
public interface ProducerInterceptor<K, V> extends Configurable {
ProducerRecord<K, V> onSend(ProducerRecord<K, V> record);
void onAcknowledgement(RecordMetadata metadata, Exception exception);
void close();
}
onSend
方法在消息分区之前,可以对消息进行一定的修改,比如给key添加前缀,甚至可以修改我们的topic,如果需要使用kafka实现延时队列高级应用,我们就可以通过拦截器对消息进行判断,并修改,暂时放入我们的延时主题中,等时间达到再放回普通主题队列。
onAcknowledgement
该方法是在我们服务端对sender线程进行消息确认,或消息发送失败后的一个回调。优先于我们send方法的callback回调。我们可以对发送情况做一个统计。但是该方法在我们的sender线程也就是唯一的IO线程执行,逻辑越少越好。
close
该方法可以在关闭拦截器时,进行一些资源的释放。
序列化器(Serializer)
生产者需要通过序列化把对象转为字节数组,才能通过网络发送给kafka。消费者也得通过反序列化把字节数组转为对象。我们需要配置序列化和反序列化器。
// 指定对应的key和value的序列化类型 key.serializer
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
一般情况我们传递的key和value用的都是String,所以用StringSerializer。如果公司有特殊的需要,也可以实现Serializer<T>
自定义自己的对象序列化器。
分区器(Patitioner)
每个topic下有多个分区,分区对消息进行负载均衡,也可以提高消息收发的并行度。具体我们的消息会进入哪个分区,通常分区器中进行安排。
public ProducerRecord(String topic, Integer partition, K key, V value);
public ProducerRecord(String topic, K key, V value);
public ProducerRecord(String topic, V value);
以上是我们消息的构造器,如果我们在消息中指定了分区,那么就会按指定的为准。
默认的分区器是DefaultPartitioner
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster,
int numPartitions) {
if (keyBytes == null) {
return stickyPartitionCache.partition(topic, cluster);
}
// hash the keyBytes to choose a partition
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
如果我们消息指定了key
,那么就会根据key的hash值对分区数进行取余,算出分区。
如果没有指定key
,默认采用sticky的粘性分区策略,消息在相同的分区下填满一个批次就更换下一个分区。
当然我们也可以采用自定义分区
,通过实现Partitioner
并且显示的配置自己的分区器。
消息累加器(RecordAccumulator)
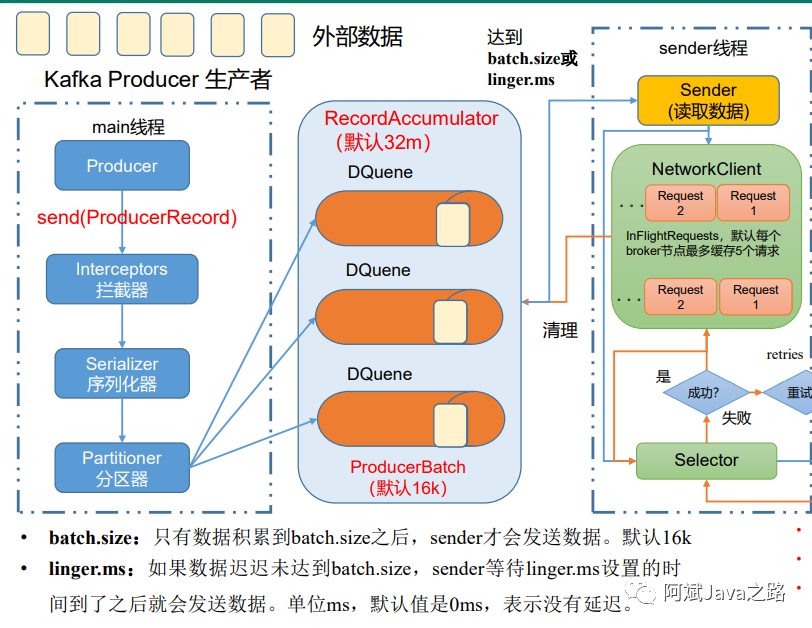
为了提高生产者的吞吐量,我们通过累加器将多条消息合并成一批统一发送。在broker中将消息批量存入。减少多次的网络IO。
累加器默认32m,如果生产者的发送速率大于sender发送的速率,消息就会堆满累加器。生产者就会阻塞,或者报错,报错取决于阻塞时间的配置。
累加器的存储形式为ConcurrentMap<TopicPartition, Deque<ProducerBatch>>
,可以看出来就是一个分区对应一个双端队列,队列中存储的是ProducerBatch
一般大小是16k根据batch.size配置,新的消息会append到ProducerBatch
中,满16k就会创建一个新的ProducerBatch
,并且触发sender线程进行发送。
如果消息量非常发,生成了大量的ProducerBatch
,在发送后,又需要JVM通过GC回收这些ProducerBatch
就变得非常影响性能,所以kafka通过 BufferPool
作为内存池来管理ProducerBatch
的创建和回收,需要申请一个新的ProducerBatch
空间时,调用 free.allocate(size, maxTimeToBlock)
找内存池申请空间。
如果单条消息大于16k,那么就不会复用内存池了,会生成一个更大的ProducerBatch
专门存放大消息,发送完后GC回收该内存空间。
为了进一步减小网络中消息传输的带宽。我们也可以通过消息压缩的方式,在生产端将消息追加进ProducerBatch
就对每一条消息进行压缩了。常用的有Gzip、Snappy、Lz4 和 Zstd,这是时间换空间的手段。压缩的消息会在消费端进行解压。
消息发送线程(Sender)
消息保存在内存后,Sender线程就会把符合条件的消息按照批次进行发送。除了发送消息,元数据的加载也是通过Sender线程来处理的。
Sender线程发送消息以及接收消息,都是基于java NIO的Selector。通过Selector把消息发出去,并通过Selector接收消息。
Sender线程默认容纳5个未确认的消息,消息发送失败后会进行重试。
消息确认机制
producer提供了三种消息确认的模式,通过配置acks
来实现
acks为1
时(默认),表示数据发送到Kafka后,经过leader成功接收消息的的确认,才算发送成功,如果leader宕机了,就会丢失数据。
acks为0
时, 表示生产者将数据发送出去就不管了,不等待任何返回。这种情况下数据传输效率最高,但是数据可靠性最低,当 server挂掉的时候就会丢数据;
acks为-1/all
时,表示生产者需要等待ISR中的所有follower都确认接收到数据后才算发送完成,这样数据不会丢失,因此可靠性最高,性能最低。
消息幂等性
在一般的MQ模型中,常有以下的消息通信概念
至少一次(At Least Once): ACK级别设置为-1 + 分区副本大于等于2 + ISR里应答的最小副本数量大于等于2。可以保证数据不丢失,但是不能保证数据不重复。 最多一次(At Most Once):ACK级别设置为0 。可以保证数据不重复,但是不能保证数据不丢失。• 精确一次(Exactly Once):对于一些非常重要的信息,比如和钱相关的数据,要求数据既不能重复也不丢失。Kafka 0.11版本以后,引入了一项重大特性:幂等性和事务。
所谓的幂等,简单地说就是对接口的多次调用所产生的结果和调用一次是一致的。生产者在进行重试的时候有可能会重复写入消息,而使用Kafka 的幂等性功能之后就可以避免这种情况。
开启幂等性功能的方式很简单,只需要显式地将生产者客户端参数enable.idempotence
设置为true即可(这个参数的默认值为true),并且还需要确保生产者客户端的retries、acks、max.in.filght.request.per.connection参数不被配置错,默认值就是对的。
为了实现幂等性,Kafka引入了ProducerId(pid)和序列号(sequenceNumber)两个概念,每个生产者在重启后,都会被分配一个pid。生产者每个主题分区,都会维护一个序列号,每生产一条消息,都会将序列号加一。broker中会在内存维护一个pid+分区对应的序列号。如果收到的序列号正好比内存序列号大一,才存储消息,如果小于内存序列号,意味着消息重复,那么会丢弃消息,并应答。如果远大于内存序列号,意味着消息丢失,会抛出异常。
所以幂等解决的是sender到broker间,由于网络波动可能造成的重发问题。用幂等来标识唯一消息。
消息事务
由于幂等性不能跨分区运作,为了保证同时发的多条消息,要么全成功,要么全失败。kafka引入了事务的概念。
开启事务需要producer设置transactional.id
的值并同时开启幂等性。
通过事务协调器,来实现事务,工作流程如下:
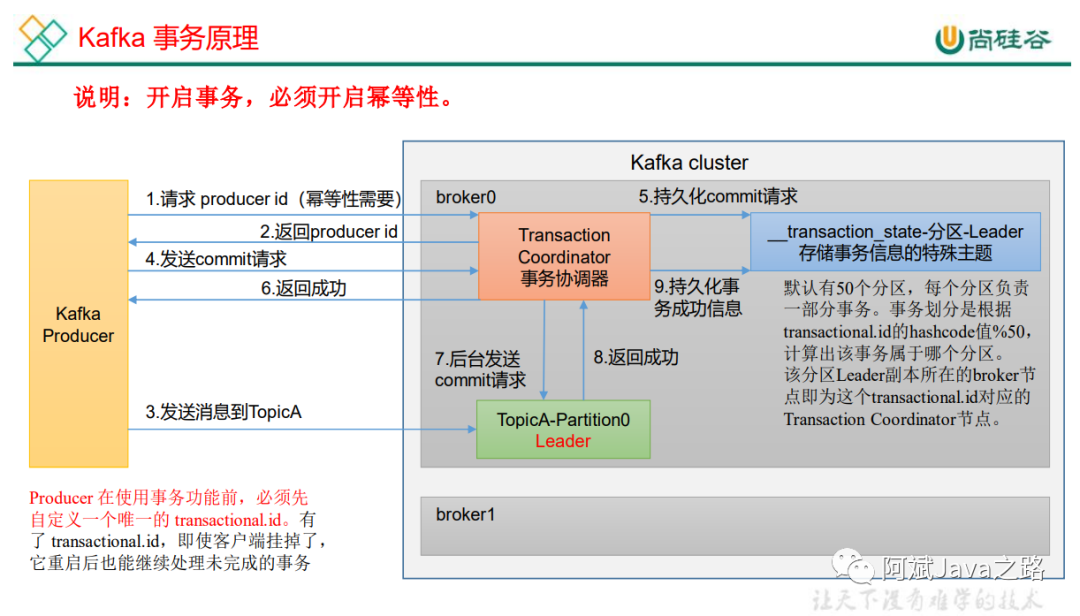
// 1 初始化事务
void initTransactions();
// 2 开启事务
void beginTransaction() throws ProducerFencedException;
// 3 在事务内提交已经消费的偏移量(主要用于消费者)
void sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets,
String consumerGroupId) throws
ProducerFencedException;
// 4 提交事务
void commitTransaction() throws ProducerFencedException;
// 5 放弃事务(类似于回滚事务的操作)
void abortTransaction() throws ProducerFencedException;
在消费端会有一个参数 isolation.level
,默认是“read_ uncommited” ,意思是说消费端应用可以看到(消费到)未提交的事务,这个参数还可以设置为“read_ committed” ,表示消费端应用不可以看到尚未提交的事务内的消息。举个例子,如果生产者开启事务并向某个分区值发送3条消息msg1.msg2和msg3,在执行commitTransaction()或abortTransaction()方法前,设置为“read_ committed”的消费端应用是消费不到这些消息的,不过KafkaConsumer内部会缓存这些消息,直到生产者执行commitTransaction()方 法之后它才能将这些消息推送给消费端应用。反之,如果生产者执行了abortTransaction0方法, 那么KafkaConsumer 会将这些缓存的消息丢弃而不推送给消费端应用。
这样的效果是如何实现的呢?实际上,在我们的broker存储消息的log文件,除了存储普通消息,还会存储控制消息。控制消息,就是标志事务的成功或者回滚。消费端根据控制消息判断事务是提交了还是回滚了,再根据隔离级别来控制消费者能读取的消息。
消息顺序
kafka只能保证单分区下的消息顺序性
,为了保证消息的顺序性,需要做到如下几点。
如果未开启幂等性
,需要 max.in.flight.requests.per.connection 设置为1。
如果开启幂等性
,需要 max.in.flight.requests.per.connection 设置为小于5。
这是因为broker端会缓存producer主题分区下的五个request,保证最近5个request是有序的。
参考
消息压缩机制

END
后台回复关键词 kafka 获取今日推荐资料
微信8.0新增了一万的好友数,之前没加上好友的可以加一下我的个人微信,再晚又满了,一起抱团取暖,结伴内卷。

扫码拉群,学习打卡,交流经验
每周一读
