





作为一个超高性能分布式数据集成平台,SeaTunnel 以支持海量数据实时同步著称,每天可以稳定高效地同步数百亿数据。
Flink SQL以SQL的形式编写实时任务,相比于传统的数据同步方案,在实时性、易用性等方面有了极大的改善。
在SeaTunnel中使用Flink SQL,数据同步的过程将变得更加简单快速。
在 6 月 25 日 SeaTunnel 线上 Meetup 活动中,来自字节跳动的大数据工程师 陶克路,为我们介绍了如何在 Apache SeaTunnel(Incubating) 中使用 Flink SQL 简化数据同步。
Profile
作者简介

陶克路
字节跳动工程师 目前从事大数据云原生计算相关工作。前阿里云大数据技术专家,多年大数据相关经验。
“
本次演讲概要:
SeaTunnel 的三种使用方式概述
使用 Flink 引擎的两种方式对比
Flink SQL 模块支持功能一览
Flink SQL 模块的实现剖析
Flink SQL 模块的后续方向思考
如何参与社区建设
Apache SeaTunnel(Incubating)
01
SeaTunnel 的三种使用方式概述
SeaTunnel 的使用方式主要包括三种,第一种是 SeaTunnel+Spark,相当于利用 SeaTunnel 生成一个Spark 的 main class,在 Spark cluster 中运行,并将 Source 和 Sink 进行转换,即数据同步流串起来。
第二种是 Seatunnel + Flink 进行数据同步,原理与 Spark 类似,通过 Seatunnel 和配置文件使用对应的 Flink DataSet/Datastream API 生成 Flink 的 main class,最终在 Flink cluster 中运行起来。
最后一种就是 SeaTunnel + Flink SQL,后面会重点介绍。
02
使用 Flink 引擎的两种方式对比
我来演示一下这部分的工作(对照视频演示),现在SeaTunnel使用的三种方式比较简单,比如我现在运行一个Spark作业,输入命令,SeaTunnel在本地起一个Spark,生成一个client, config配置对应参数。提交完作业之后,其实就生成了一个Spark Submit命令。我们可以简单理解成SeaTunnel所做的事情就是根据config生成一个Spark job,提交命令申请,核心逻辑会通过SeaTunnel Spark main class,根据template文件进行一些补充。
这个是定义的配置文件,包含 4 个部分,Spark配置,Source(定义数据源),Sink(定义数据的 Sink),以及数据转换(transform)。Spark会根据 config运行一个job,并生成对应的结果。
Flink作业,同样需要先起一个Flink Cluster,通过DataSet/DataSeaTunnelream API的方式,提交一个Flink提交命令,之后提交到我们刚才启动的Flink cluster上。
Flink SQL的使用也很简单,核心是生成一个Flink SQL作业,提交到集群中。
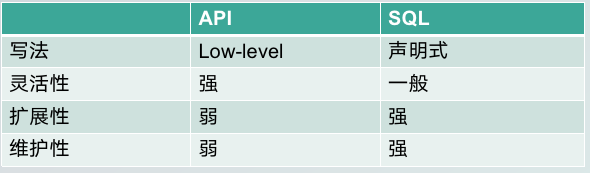
两种不同Flink使用方式对比下,其中一种是使用Flink 的DataSet/DataStream API构建Flink job,这种方法代码量大,主要是拓展connector,将其填充到main class中;而使用SQL方法,是基于声明式的。Flink 对 connector 发现是基于SPI方式,不需要做前面的connector 相关开发工作。
从写法上来说,API方式相对来说更“命令式”些,SQL更加声明式,后者对于开发者来说门槛更低。
从灵活性上来说 ,API比SQL方式灵活性更高。
从扩展性上来说,API更差一些,因为每新增一种connector,就需要写大量代码;而SQL创建connector是基于SPI机制,只需要把connector的Jar包打到cluster中就可以。
从维护性上来说,我们在升级Flink版本时,API需要不断地做相应的升级,但使用SQL不需要担心引擎升级,所以我认为,SQL是一种相对更简单,扩展性更好的方式。
03
Flink SQL 模块支持功能一览
下面介绍一下在SeaTunnel中如何使用Flink SQL。
Connector
DS
动态加载
支持类型:
jdbc, kafka, elaSeaTunnel icsearch-6/7, ...
让Flink SQL跑起来,首先需要支持connector。目前我们支持的 connector类型主要包括jdbc, kafka, elaticsearch-6/7等。这种方式相比于API加载更简单。此外,我们还做了动态加载的功能,当检测到SQL中包含Kafka等类型的connector,自动将其加载到对应的 cluster中,而不是提前放到中。
UDF:暂无
DS
目前我们没有针对UDF做太多扩展,因为Flink本身提供的UDF可以解决大部分问题。
Catalog
DS
InMemoryCatalog 进行中
HiveCatalog JdbcCatalog
Catalog对于生产实践是一个非常必要的功能,它可以存储数据的元数据,可以直接使用 catalog 中之前定义的某个表。目前,我们支持了InMemoryCatalog,正在支持中的Catalog有在大数据领域中广泛使用的开发类型HiveCatalog,以及JdbcCatalog。
Flink SQL模块目前具备的功能如demo所示。指路视频 10:38-16:14 。

04
Flink SQL 模块的实现剖析
接下来解析一下Flink SQL模块的实现逻辑。指路视频 16:24-21:27 。
命令行解析
配置解析和设置
SQL Parse
Connector 动态加载
目前实现方式的好处和缺点
增加connector简单
不能很好地支持application mode
Flink SQL实现的逻辑很简单,首先是通过Shell读取命令,把参数拼接成一个命令,提交给flink cluster。再根据反射获取Flink Env的Configuration,经过SQL解析获取connector type,将其加载到CLASSPATH中,并将其设置到Flink参数中来,让解析进行下去,提交到Flink集群上。
这种实现方式有好处也有缺点,好处是增加connector非常简单,只需要在SeaTunnel connector下的Flink SQL中加入一个Sub-module,包含Flink本身的依赖,打包时把它输出到下图所示地址。
目前Flink SQL模块实现的一个缺点,是不能很好地支持application mode。
05
Flink SQL 模块的后续方向思考
对于Flink SQL 模块的后续发展方向,我有一些自己的思考,欢迎社区讨论共建。
已有功能完善
DS
首先是针对已有功能的完善,主要包括以下3点:
Connector Enrichment,支持更多的connector类型;
Udf Enhancement,这部分工作不紧急,因为如果Flink自带的功能可以覆盖掉大部分用户场景的话,其实并不需要这部分工作;
Catalog Enhancement,如前所述,catalog对于生产环境来说不可或缺,我们后续将优先支持Hive和JDBC catalog。
易用性增强
DS
其次是增强易用性,Application Mode 支持。Application mode支持对底层部署模式有要求,只能在YARN和K8s上部署,YARN支持相对简单,只需要特定参数;但k8s会涉及到依赖的Jar包问题,相对复杂,所以后续节能还需要讨论如何支持。
06
如何参与社区建设
对于如何参与社区贡献,我也有一些自己的心得供大家参考。
首先,大家需要熟悉 git 的基本原理,主要包括:
git clone&pull&push,不必赘述;
git rebase&git merge,我认为rebase对开发者影响比较大,merge会生成一条新的commit记录,现在比较成熟的社区都会使用rebase,而不是merge;
git cherry-pick,我们可能经常需要将自己的Commit提交到开源社区的不同分支上,所以需要掌握下这个技能。
第二,熟悉 GitHub 的项目协作方式,GitHub上的协作方式主要包括:
Fork
Pull requeSeaTunnel
Add multi-remote upSeaTunnelream
Fetch&rebase
第三,Good first contribute。熟悉基本功能后,需要找到一个commit的切入点,建议可以到社区找一下打了Good first issue标签的任务,它们一般比较友好,易于解决。
第四,邮件列表讨论。在对开源社区比较熟悉之后,可以在开源社区的邮件列表中进行讨论,投入自己感兴趣的方向;
最后一点,如果在使用过程中发现问题,可以提出Proposal修复这些问题,慢慢熟悉流程。
我的分享就到这里,谢谢!
Apache SeaTunnel

// 保持联络 //
微信号 : Seatunnel
来,和社区一同成长!
Apache SeaTunnel(Incubating) 是一个分布式、高性能、易扩展、用于海量数据(离线&实时)同步和转化的数据集成平台。
仓库地址:
https://github.com/apache/incubator-seatunnel
网址:
https://seatunnel.apache.org/
Proposal:
https://cwiki.apache.org/confluence/display/INCUBATOR/SeaTunnelProposal
Apache SeaTunnel(Incubating) 2.1.0 下载地址:
https://seatunnel.apache.org/download
衷心欢迎更多人加入!
能够进入 Apache 孵化器,SeaTunnel(原 Waterdrop) 新的路程才刚刚开始,但社区的发展壮大需要更多人的加入。我们相信,在「Community Over Code」(社区大于代码)、「Open and Cooperation」(开放协作)、「Meritocracy」(精英管理)、以及「多样性与共识决策」等 The Apache Way 的指引下,我们将迎来更加多元化和包容的社区生态,共建开源精神带来的技术进步!
我们诚邀各位有志于让本土开源立足全球的伙伴加入 SeaTunnel 贡献者大家庭,一起共建开源!
提交问题和建议:
https://github.com/apache/incubator-seatunnel/issues
贡献代码:
https://github.com/apache/incubator-seatunnel/pulls
订阅社区开发邮件列表 :
dev-subscribe@seatunnel.apache.org
开发邮件列表:
dev@seatunnel.apache.org
加入 Slack:
https://join.slack.com/t/apacheseatunnel/shared_invite/zt-123jmewxe-RjB_DW3M3gV~xL91pZ0oVQ
关注 Twitter:
https://twitter.com/ASFSeaTunnel
往期推荐



我知道你在看哟

