





1
这次在 6月 Meetup 为大家带来的是Scaleph 基于 Apache SeaTunnel (Incubating) 的数据集成介绍,希望你有所收获。
“
本次演讲主要包括五个部分:
关于Scaleph
Scaleph架构&功能简介
SeaTunnel社区贡献
系统演示
开发计划
Apache SeaTunnel (Incubating)

王奇
Apache SeaTunnel Contributor
搜索推荐工程师,大数据 Java 开发
01
Scaleph的缘起
我最早是从事搜索推荐工作,在团队里面负责维护Dump系统,主要是为我们的搜索引擎提供喂数据的功能,先给大家介绍在维护过程中主要的5个痛点问题:

及时性和稳定性
业务复杂/大宽表设计
Dump系统会将电商平台的商品、类目、品牌、店铺、商品标签、数仓的实时/离线数据及模型数据会经过一系列的预处理,最终输出成一张大宽表,在这个过程中,业务的复杂性和多变性,会侵入到Dump系统中来,所以应对的技术挑战相对就更高了。
全量+实时索引
数据联动更新
数据兜底
搜索推荐服务当时也承担着C端绝大部分的流量,当公司其他团队的性能跟不上的时候,他们一般会把数据通过Dump系统送到搜索引擎,然后我们团队代替他们返回给Web页面,避免后续对他们发起二次请求调用。
同时,如果其他团队的业务系统产生了脏数据,也需要Dump系统做数据保护,防止数据外泄给C端用户造成不好的影响,所以开发维护中的时候,也有很大的难度。
02
为什么引入Flink?
作为国内 Flink 的早期使用者,阿里巴巴在搜索推荐领域拥有悠久的历史和成功的经验,在搜索推荐团队开发维护 Dump 系统的职业经历促使我开始关注使用Flink做A/B实验的报表、数据实时流之外的相关工作,主要也就是用Flink来实现Dump系统为搜索去提供Dump平台的工作,使用Flink做数据集成有5个优点:
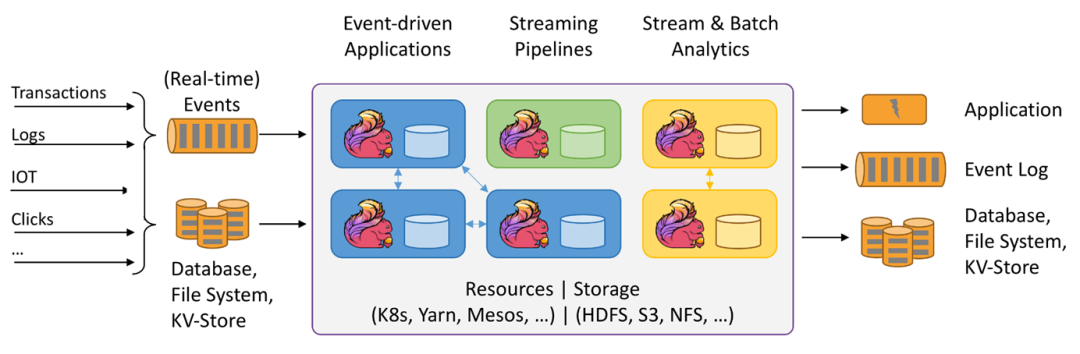
天然的分布式支持:Flink支持多种部署和运行方式,单机、yarn、Kubernetes;
低延迟、海量吞吐:在众多大厂中应用广泛;
生态支持:Flink提供了众多开箱即用的connector,支持csv、avro数据格式,kafka、pulsar等消息系统以及众多的存储系统,和大数据生态紧密结合;
基于分布式轻量异步快照机制实现exactly-once语义,为任务的失败、重启、迁移、升级等提供数据一致性保障;
metrics。Flink除了自身提供的 metrics 外,metrics 框架可以让用户为任务开发自定义的 metrics,丰富监控指标;
03
为什么选择SeaTunnel?
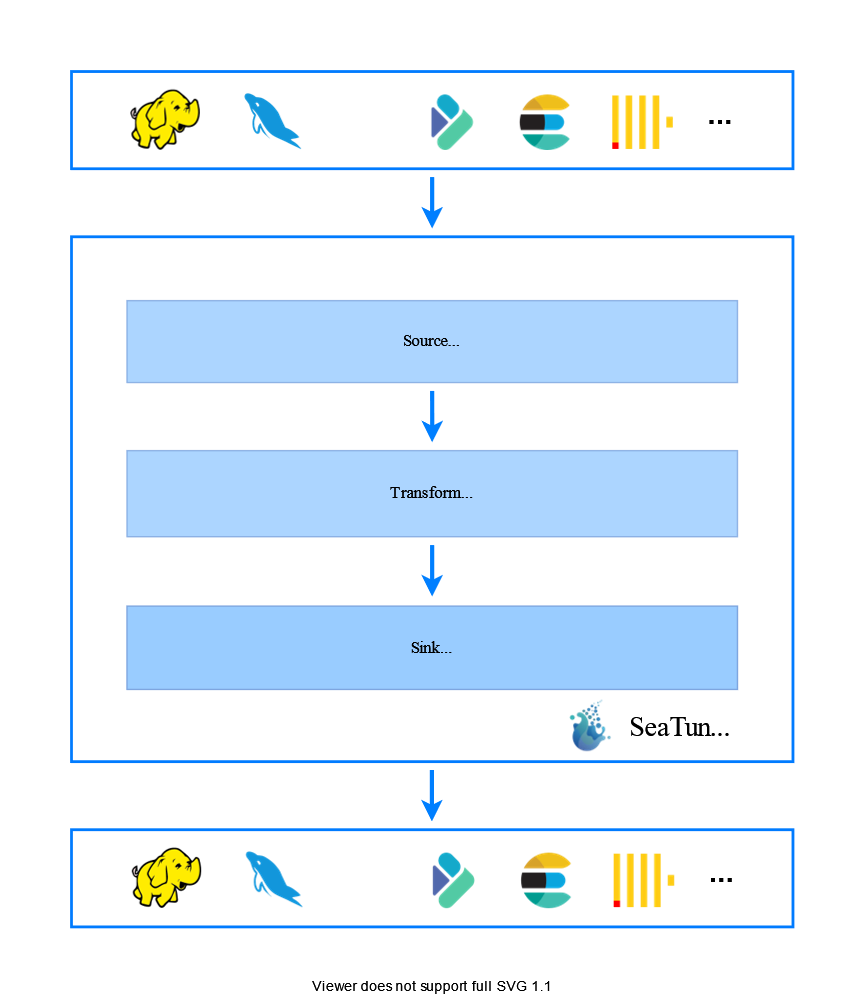
后来接触到 SeaTunnel 的时候,很喜欢 SeaTunnel 的设计理念!SeaTunnel 是运行在 Flink 和Spark 之上,高性能和分布式海量数据的下一代集成框架。
重要的是它是开箱即用的,并且针对现有的生态可以实现无缝集成,因为运行在 Flink 和 Spark 之上,可以很方便地接入公司现有的 Flink 和 Spark 的基础设施。另一方面 SeaTunnel 也有很多的生产案例,在进入 Apache 基金会孵化之后,社区非常活跃,未来可期。
04
关于Scaleph
项目出发点
项目亮点
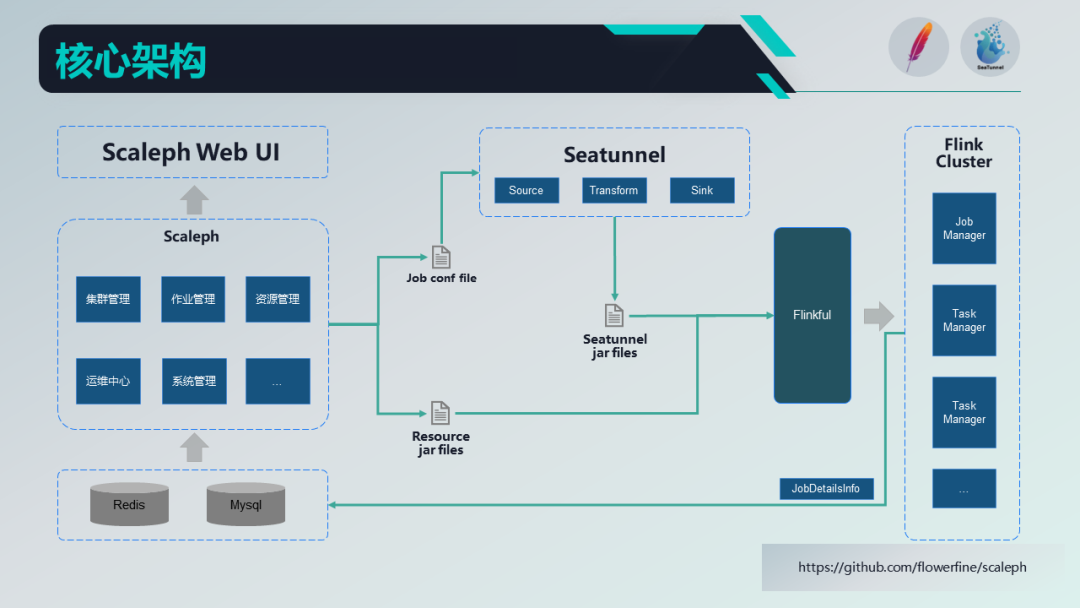
在真正的生产应用中,进行数据集成的时候,以可视化任务编排或 SQL 开发为数据集成的主要形式,我们认为 Drag and Drop 可视化任务编排可以最大程度减轻用户做数据集成的负担;
另外就是实现对作业进行多版本管理,数据源的支持;
Flink集群支持多版本/多部署环境;
实时/周期任务也有相关的支持。
Scaleph功能简介(数据开发)
DS
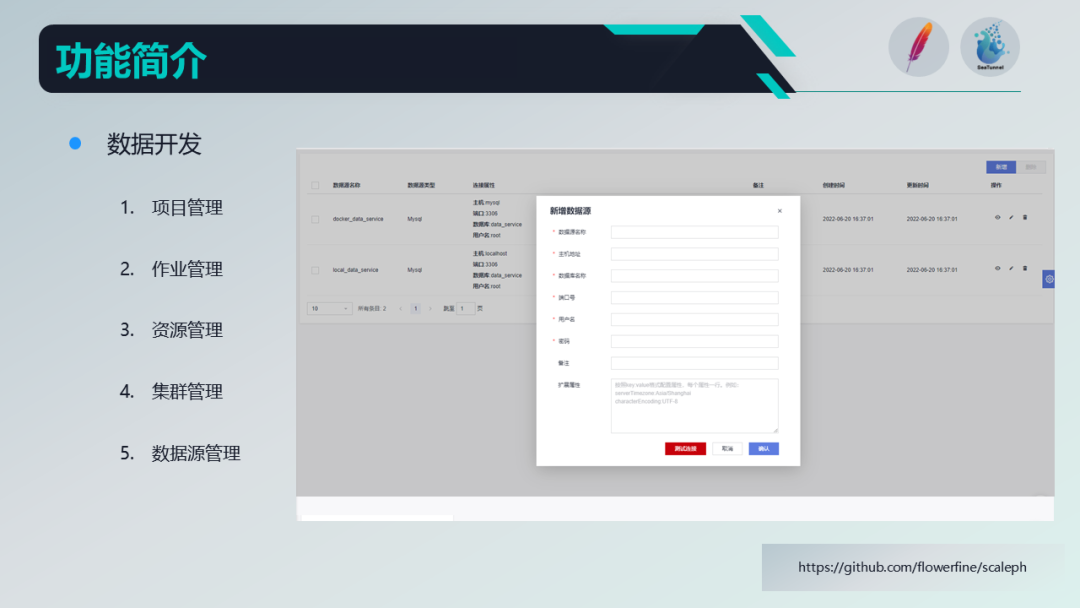
主要是用户创建数据同步任务的时候,能够按照不同的业务维度进行相关的管理工作。
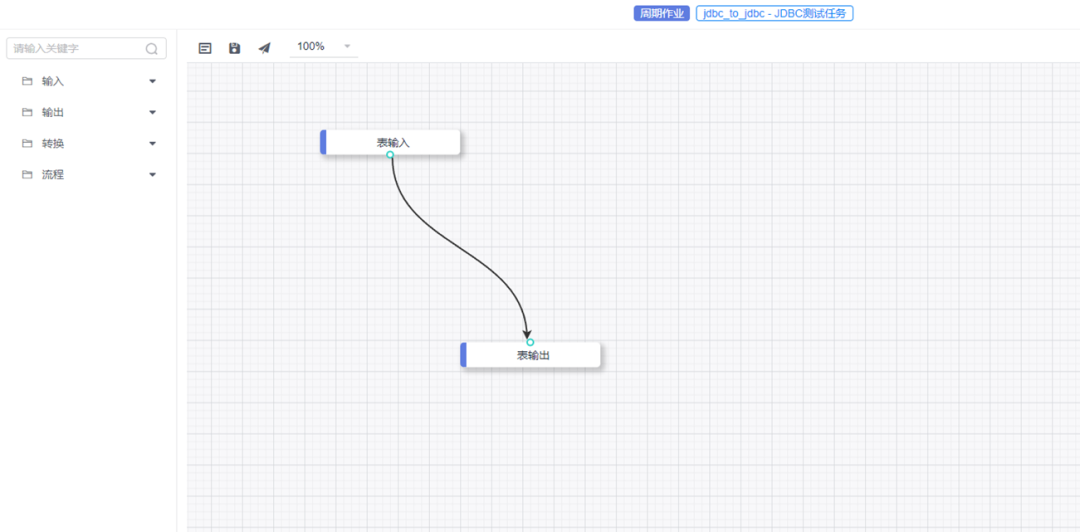
通过拖拉拽的操作可以创建SeaTunnel的数据任务,然后进行相应的提交运行。
主要是提供Flink集群信息的录入,目前可以支持Standalone Session 集群录入,用户录入后,提交SeaTunnel作业时就可以选择集群,任务就会在集群运行。
支持用户提前录入一些数据源信息,这样就不用每个任务都把数据源信息输入一遍。同时,还可以去实现数据源的共享和权限限制,防止数据源信息明文泄露。
Scaleph功能简介(运维中心)
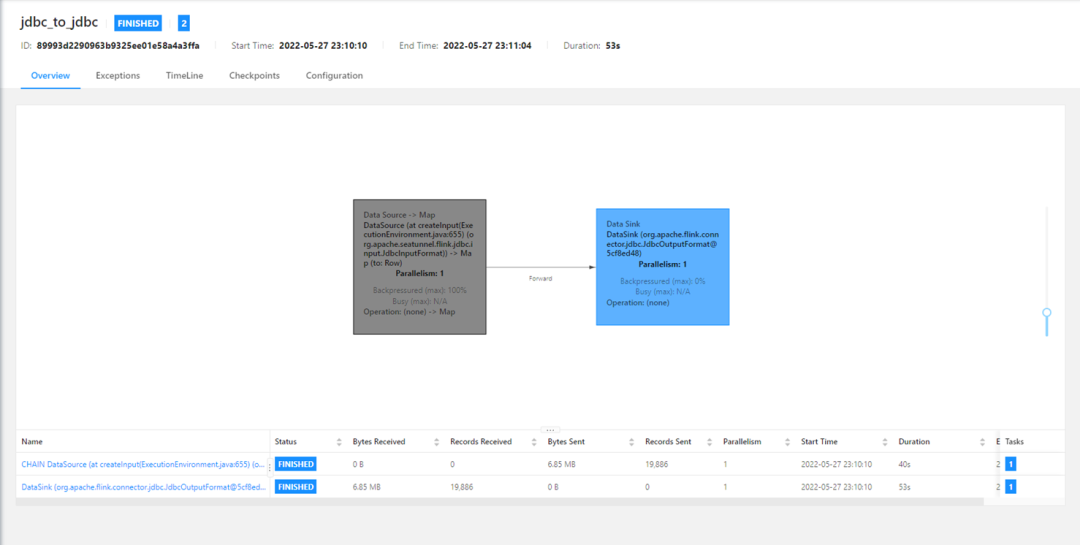
运维中心是一个实时任务和周期任务的运行日志,用户提交任务的时候看到任务相关的信息,我们还提供了链接跳转操作,用户点击可以跳转到Flink的Web UI上面去,通过Flink官方的Web UI页面,可以看到任务具体的执行信息。
Scaleph功能简介(数据标准)
数据治理是个大的体系,大家比较关心元数据、数据血缘、数据资产,但是数据标准也是数据治理的重要一环,我们把公司自己内部使用的标准系统开源出来,给大家分享数据标准的相关知识。

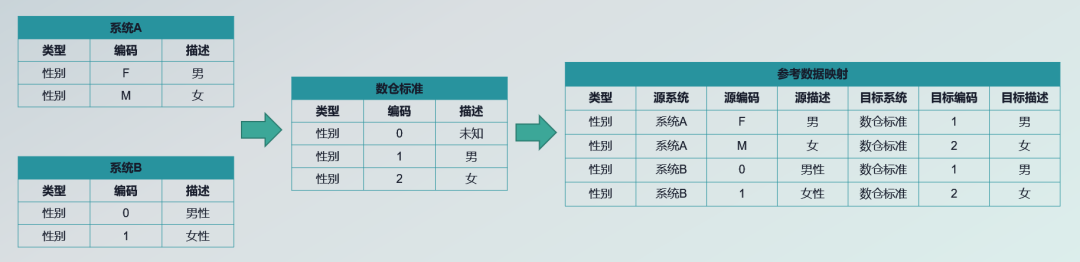
是否能在数据集成过程中,直接通过数据标准进行Transform 操作,实现知识和模型自动维护和映射。
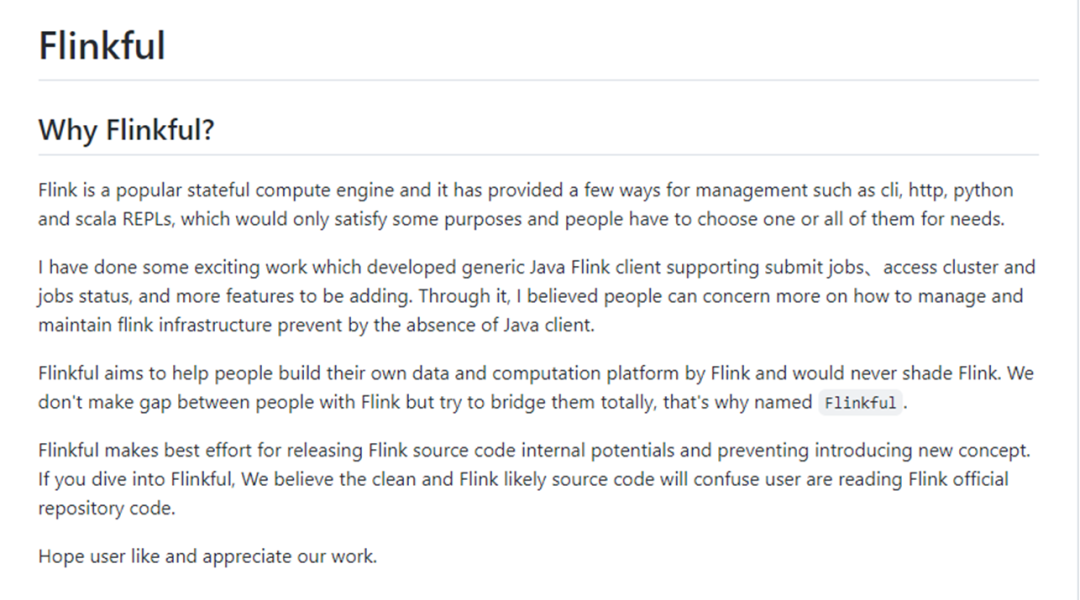
Flinkful是我们为 Flink 开发的一个Java客户端。
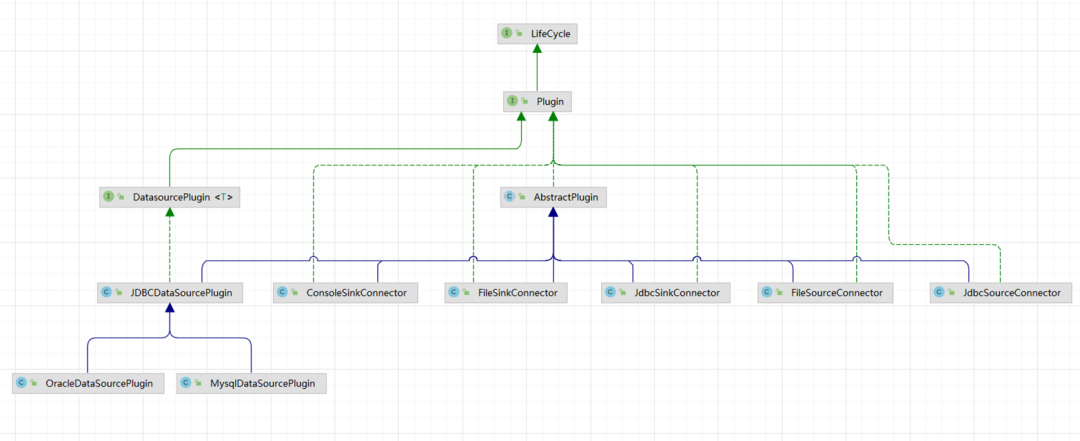
问题分析
DS
01
Flink-jdbc-connector 功能增强
02
Seatunnel-core-flink.jar 瘦身
03
Flink jobId 获取问题
04
SeaTunnel 调用 System.exit() 问题
05
SeaTunnel 社区贡献
这个项目时间充足的话是可以进行 Docker 环境和 IDE 环境演示的,这里时间有限就选择 Docker 环境给大家进行演示,演示视频(直接跳转23'18s):
Apache SeaTunnel

// 保持联络 //
微信号 : Seatunnel
来,和社区一同成长!
Apache SeaTunnel(Incubating) 是一个分布式、高性能、易扩展、用于海量数据(离线&实时)同步和转化的数据集成平台。
仓库地址:
https://github.com/apache/incubator-seatunnel
网址:
https://seatunnel.apache.org/
Proposal:
https://cwiki.apache.org/confluence/display/INCUBATOR/SeaTunnelProposal
Apache SeaTunnel(Incubating) 2.1.0 下载地址:
https://seatunnel.apache.org/download
衷心欢迎更多人加入!
能够进入 Apache 孵化器,SeaTunnel(原 Waterdrop) 新的路程才刚刚开始,但社区的发展壮大需要更多人的加入。我们相信,在「Community Over Code」(社区大于代码)、「Open and Cooperation」(开放协作)、「Meritocracy」(精英管理)、以及「多样性与共识决策」等 The Apache Way 的指引下,我们将迎来更加多元化和包容的社区生态,共建开源精神带来的技术进步!
我们诚邀各位有志于让本土开源立足全球的伙伴加入 SeaTunnel 贡献者大家庭,一起共建开源!
提交问题和建议:
https://github.com/apache/incubator-seatunnel/issues
贡献代码:
https://github.com/apache/incubator-seatunnel/pulls
订阅社区开发邮件列表 :
dev-subscribe@seatunnel.apache.org
开发邮件列表:
dev@seatunnel.apache.org
加入 Slack:
https://join.slack.com/t/apacheseatunnel/shared_invite/zt-123jmewxe-RjB_DW3M3gV~xL91pZ0oVQ
关注 Twitter:
https://twitter.com/ASFSeaTunnel
往期推荐



点击阅读原文,收听回放

