





大家好,今天大表哥给大家分享是 PG的 TOAST 的大对象存储方式。
TOAST 是 The Oversized-Attribute Storage Technique 的意思。 粗略的可以翻译成大对象存储技术。
通常PG的 一个数据页的大小是8KB ,并且不允许一个大的元祖跨越多个数据页。官方原文如下:
PostgreSQL uses a fixed page size (commonly 8 kB), and does not allow tuples to span multiple pages 。
PG 采取的TOAST 技术就像是 大家平时吃的早餐吐司面包一样,把一个大的面包(元祖)用刀子切成一片一片的. 技术上叫分割成 chunk , 每个chunk 独立形成一行 存储在独立的toast 表中。
什么情况下,可以触发 TOAST 呢?
如果一个元祖的大小,超过 2KB(参数 TOAST_TUPLE_THRESHOLD 决定,这个是编译时候的默认参数,需要重新编译软件才生效),那么PG会尝试进行压缩,把每个元祖控制在2KB之内,如果不能满足2KB之内的需求,
这个时候就需要独立的 toast 的表来存储 oversized 的部分了。
自从PG 11版本之后,可以在建表的语句上进行表级别的修改: 指定参数 toast_tuple_target 来限定 TOAST的阈值
create table toast_table2 (id int, content text) WITH (toast_tuple_target=4096);
通常情况下,在 toast 表中的 chunk 的大小也是 2KB (实际上是1996 bytes)。 换成通俗的来说,就是每个面包片的大小是2KB (实际上是1996 bytes)。
下面我们来试着创建一张带有 toast 的表:
通常我们创建带有 text 类型的表,PG会自动帮我们创建一下先关的TOAST 的表:
可以通过reltoastrelid 这个的对象的oid , 找到具体的 toast 表的名字: pg_toast_33006
dbtest@[local:/tmp]:1992=#5427 create table test_toast(id int, content text);
CREATE TABLE
dbtest@[local:/tmp]:1992=#5427 select oid, reltoastrelid from pg_class where relname = 'test_toast';
oid | reltoastrelid
-------+---------------
33006 | 33009
(1 row)
dbtest@[local:/tmp]:1992=#5427 select relname from pg_class where oid = 33009;
relname
----------------
pg_toast_33006
(1 row)
我们来看一下 toast 的表结构: chunk_id, chunk_seq 构成了唯一的主键, chunk_data 存储的是实际的数据,也是我们说的吐司面片的切片
dbtest@[local:/tmp]:1992=#5427 \d pg_toast.pg_toast_33006
TOAST table "pg_toast.pg_toast_33006"
Column | Type
------------+---------
chunk_id | oid
chunk_seq | integer
chunk_data | bytea
Owning table: "public.test_toast"
Indexes:
"pg_toast_33006_index" PRIMARY KEY, btree (chunk_id, chunk_seq)
接下来,我们创建一个函数来帮助我们生成并返回一个大的字符串:
CREATE OR REPLACE FUNCTION generate_random_string(
length INTEGER,
characters TEXT default '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz') RETURNS TEXT AS$$DECLARE
result TEXT := '';BEGIN
IF length < 1 then
RAISE EXCEPTION 'Invalid length';
END IF;
FOR __ IN 1..length LOOP
result := result || substr(characters, floor(random() * length(characters))::int + 1, 1);
end loop;
RETURN result;
END;$$
LANGUAGE plpgsql;
我们来测试一下这个函数:
dbtest@[local:/tmp]:1992=#5427 select generate_random_string(20);
generate_random_string
------------------------
QB6BJJipFX3LkHoMoHjd
(1 row)
我们尝试插入 4KB的字段长度的数据:
dbtest@[local:/tmp]:1992=#5427 insert into test_toast values (1,generate_random_string(1024*4));
INSERT 0 1
查看对应的 toast 表: 我们可以看到分割成了 3个chunk
dbtest@[local:/tmp]:1992=#5427 SELECT chunk_id, COUNT(*) as chunks, pg_size_pretty(sum(octet_length(chunk_data)::bigint))FROM pg_toast.pg_toast_33006 GROUP BY 1 ORDER BY 1;
chunk_id | chunks | pg_size_pretty
----------+--------+----------------
33012 | 3 | 4096 bytes
(1 row)
每个chunk 的大小是: 我们可以看到 (seq=0,1)每个 trunk 的大小 是 1996 bytes, 符合小于 参数设定的 TOAST_TUPLE_TARGET 2048 bytes 的上限。
dbtest@[local:/tmp]:1992=#5427 SELECT chunk_id, chunk_seq, pg_size_pretty(sum(octet_length(chunk_data)::bigint))FROM pg_toast.pg_toast_33006 group by 1,2 ORDER BY 1;
chunk_id | chunk_seq | pg_size_pretty
----------+-----------+----------------
33012 | 2 | 104 bytes
33012 | 1 | 1996 bytes
33012 | 0 | 1996 bytes
(3 rows)
我们可以看到 切吐司面变的过程就是一刀一刀的来切,每一刀对应着一个 chunk_seg , 核心的内部代码也是这么实现的:
官方文档上提到了 这个源码文件:toast_internals.c
具体的路径是: src/backend/access/common/toast_internals.c 中的这个函数 toast_save_datum
核心切片代码段 : data_todo 就是我们的吐司, chunk_size 就是面包片,循环的一刀一刀的切, 每切一刀, chunk_seq + 1
* Split up the item into chunks
*/
while (data_todo > 0)
{
int i;
CHECK_FOR_INTERRUPTS();
/*
* Calculate the size of this chunk
*/
chunk_size = Min(TOAST_MAX_CHUNK_SIZE, data_todo);
/*
* Build a tuple and store it
*/
t_values[1] = Int32GetDatum(chunk_seq++);
SET_VARSIZE(&chunk_data, chunk_size + VARHDRSZ);
memcpy(VARDATA(&chunk_data), data_p, chunk_size);
toasttup = heap_form_tuple(toasttupDesc, t_values, t_isnull);
heap_insert(toastrel, toasttup, mycid, options, NULL);
...
...
/*
* Free memory
*/
heap_freetuple(toasttup);
/*
* Move on to next chunk
*/
data_todo -= chunk_size;
data_p += chunk_size;
}
我们建表的时候 也可以指定 参数 TOAST_TUPLE_TARGET, 来限定触发TOAST的阈值:
取值范围是 128 to 8016
ERROR: value 64 out of bounds for option “toast_tuple_target”
DETAIL: Valid values are between “128” and “8160”.
这个数值越小,触发TOAST的几率就越大,也就是说数据压缩进入 TOAST 表的几率,就越大。
测试创建2张表:
db_test=# CREATE TABLE toast_test_default_threshold (id SERIAL, value TEXT);
CREATE TABLE
db_test=# CREATE TABLE toast_test_128_threshold (id SERIAL, value TEXT) WITH (toast_tuple_target=128);
CREATE TABLE
插入相同的数据:
db_test=# INSERT INTO toast_test_default_threshold (value) VALUES (generate_random_string(2100, '123'));
INSERT 0 1
db_test=# INSERT INTO toast_test_128_threshold (value) VALUES (generate_random_string(2100, '123'));
INSERT 0 1
查询相关toast 表:
db_test=# SELECT c1.relname, c2.relname AS toast_relname
db_test-# FROM pg_class c1 JOIN pg_class c2 ON c1.reltoastrelid = c2.oid
db_test-# WHERE c1.relname LIKE '%toast%' AND c1.relkind = 'r';
relname | toast_relname
------------------------------+------------------
toast_test_128_threshold | pg_toast_1844245
toast_test_default_threshold | pg_toast_1844236
我们可以看到 TOAST_TUPLE_TARGET = 128 的表触发了 TOAST:
db_test=# SELECT
db_test-# c1.relname,
db_test-# pg_size_pretty(pg_relation_size(c1.relname::regclass)) AS size,
db_test-# c2.relname AS toast_relname,
db_test-# pg_size_pretty(pg_relation_size(('pg_toast.' || c2.relname)::regclass)) AS toast_size
db_test-# FROM
db_test-# pg_class c1
db_test-# JOIN pg_class c2 ON c1.reltoastrelid = c2.oid
db_test-# WHERE
db_test-# c1.relname LIKE 'toast_test_%'
db_test-# AND c1.relkind = 'r';
relname | size | toast_relname | toast_size
------------------------------+------------+------------------+------------
toast_test_128_threshold | 8192 bytes | pg_toast_1844245 | 8192 bytes
toast_test_default_threshold | 8192 bytes | pg_toast_1844236 | 0 bytes
db_test=# SELECT chunk_id, chunk_seq, pg_size_pretty(sum(octet_length(chunk_data)::bigint))FROM pg_toast.pg_toast_1844245 group by 1,2 ORDER BY 1;
chunk_id | chunk_seq | pg_size_pretty
----------+-----------+----------------
1844252 | 0 | 759 bytes
1844265 | 0 | 1339 bytes
(2 rows)
db_test=# SELECT chunk_id, chunk_seq, pg_size_pretty(sum(octet_length(chunk_data)::bigint))FROM pg_toast.pg_toast_1844236 group by 1,2 ORDER BY 1;
chunk_id | chunk_seq | pg_size_pretty
----------+-----------+----------------
(0 rows)
结论: TOAST_TUPLE_TARGET 这个数值越小,触发TOAST的几率就越大,也就是说数据压缩进入 TOAST 表的几率,就越大。
我们来看一下TOAST 表 进行全表扫描效率:
我们这次创建2 张表如下:
db_test=# CREATE TABLE toast_test_default_threshold (id SERIAL, value TEXT);
CREATE TABLE
Time: 6.394 ms
db_test=# CREATE TABLE toast_test_4096_threshold (id SERIAL, value TEXT) WITH (toast_tuple_target=4096);
CREATE TABLE
Time: 6.591 ms
我们向2个表中插入 相同的 50万 的数据:
db_test=# create table tmp_tbl (id SERIAL, value TEXT);
CREATE TABLE
Time: 6.941 ms
db_test=# WITH str AS (SELECT generate_random_string(2048) AS value)
db_test-# INSERT INTO tmp_tbl (value)
db_test-# SELECT value
db_test-# FROM generate_series(1, 500000), str;
INSERT 0 500000
Time: 12104.729 ms (00:12.105)
db_test=# insert into toast_test_default_threshold select id, value from tmp_tbl;
INSERT 0 500000
Time: 13982.846 ms (00:13.983)
db_test=# insert into toast_test_4096_threshold select id, value from tmp_tbl;
INSERT 0 500000
Time: 6855.358 ms (00:06.855)
查看表的大小:
db_test=# SELECT
c1.relname,
pg_size_pretty(pg_relation_size(c1.relname::regclass)) AS size,
c2.relname AS toast_relname,
pg_size_pretty(pg_relation_size(('pg_toast.' || c2.relname)::regclass)) AS toast_size
FROM
pg_class c1
JOIN pg_class c2 ON c1.reltoastrelid = c2.oid
WHERE
c1.relname LIKE 'toast_test_%'
AND c1.relkind = 'r';
relname | size | toast_relname | toast_size
------------------------------+---------+------------------+------------
toast_test_default_threshold | 25 MB | pg_toast_4844457 | 1302 MB
toast_test_4096_threshold | 1302 MB | pg_toast_4844467 | 0 bytes
(2 rows)
我们可以测试一下 全表扫描的时间:
db_test=# EXPLAIN (ANALYZE, TIMING) SELECT * FROM toast_test_default_threshold;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------
Seq Scan on toast_test_default_threshold (cost=0.00..8185.00 rows=500000 width=22) (actual time=0.020..41.540 rows=500000 loops=1)
Planning Time: 0.054 ms
Execution Time: 58.474 ms
(3 rows)
db_test=# EXPLAIN (ANALYZE, TIMING) SELECT * FROM toast_test_4096_threshold;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------
Seq Scan on toast_test_4096_threshold (cost=0.00..171667.01 rows=500001 width=2056) (actual time=0.076..539.210 rows=500000 loops=1)
Planning Time: 0.059 ms
Execution Time: 558.273 ms
(3 rows)
我们可以明显看出 在全包扫描的情况下: 带有 toast 存储的表 明显 比 不带toast 存储的表要快很多,
全包扫描耗时比: 大致 1:10
toast_test_default_threshold (带有toast ) VS toast_test_4096_threshold (不带toast ) = 43.163 ms : 473.915 ms
原因也是大家比较容易理解的: toast_test_default_threshold 本身 只有 25MB ,超出 2K 的部分都存储在了 toast的表中
而 toast_test_4096_threshold 这个表 由于我们手动的设置了 toast_tuple_target=4096 , 所以并没触发 toast 存储
relname | size | toast_relname | toast_size
------------------------------+---------+------------------+------------
toast_test_default_threshold | 25 MB | pg_toast_4844457 | 1302 MB
toast_test_4096_threshold | 1302 MB | pg_toast_4844467 | 0 bytes
toast_test_default_threshold : value 以指针的形式指向了 toast 表
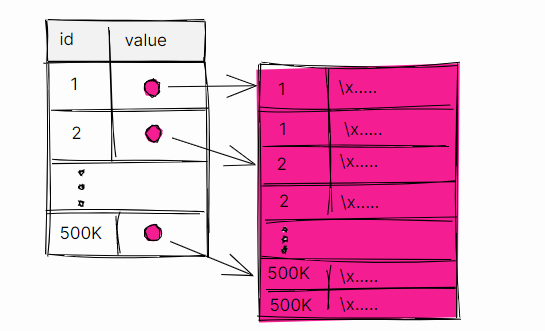
toast_test_4096_threshold: 全部存储在了表内
目前我们得出的结论是:全表过滤扫描, 那么优化器是不会选择扫描外部的toast 的表的,只会扫描本表中的指向toast表的指针。
现在即使我们排除大文本字段,只查询 ID 这个int 类型的字段, 2者耗时还是有巨大的差距, 因为优化器的选择的执行计划并没有变还是全表扫描
耗时比 依旧在1:10
db_test=# EXPLAIN (ANALYZE, TIMING) SELECT id FROM toast_test_4096_threshold;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------
Seq Scan on toast_test_4096_threshold (cost=0.00..171667.01 rows=500001 width=4) (actual time=0.057..557.537 rows=500000 loops=1)
Planning Time: 0.028 ms
Execution Time: 576.747 ms
(3 rows)
db_test=# EXPLAIN (ANALYZE, TIMING) SELECT id FROM toast_test_default_threshold;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------
Seq Scan on toast_test_default_threshold (cost=0.00..8185.00 rows=500000 width=4) (actual time=0.020..52.318 rows=500000 loops=1)
Planning Time: 0.056 ms
Execution Time: 69.657 ms
(3 rows)
这个时候,如果我们创建索引,选择索引access 的方式,只查询一条或者几条的话,差距不是很大。
db_test=# create index concurrently idx_toast_1 on toast_test_4096_threshold (id) ;
CREATE INDEX
db_test=# create index concurrently idx_toast_2 on toast_test_default_threshold (id) ;
CREATE INDEX
性能上基本上 无差别: toast_test_4096_threshold vs toast_test_default_threshold = 0.043 ms : 0.045 ms
db_test=# EXPLAIN (ANALYZE, TIMING) SELECT * FROM toast_test_4096_threshold where id = 1000;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------
Index Scan using idx_toast_1 on toast_test_4096_threshold (cost=0.42..8.44 rows=1 width=2056) (actual time=0.023..0.024 rows=1 loops=1)
Index Cond: (id = 1000)
Planning Time: 0.077 ms
Execution Time: 0.043 ms
(4 rows)
db_test=# EXPLAIN (ANALYZE, TIMING) SELECT * FROM toast_test_default_threshold where id = 1000;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------------
Index Scan using idx_toast_2 on toast_test_default_threshold (cost=0.42..8.44 rows=1 width=22) (actual time=0.019..0.020 rows=1 loops=1)
Index Cond: (id = 1000)
Planning Time: 0.295 ms
Execution Time: 0.045 ms
(4 rows)
如果进行大量索引扫描的话,差距还是很明显的 : toast_test_4096_threshold vs toast_test_default_threshold = 145.957 ms: 25.064 ms
db_test=# EXPLAIN (ANALYZE, TIMING) SELECT * FROM toast_test_default_threshold where id > 1000 and id < 100000;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------------------------
Index Scan using idx_toast_2 on toast_test_default_threshold (cost=0.42..3653.04 rows=97581 width=22) (actual time=0.023..20.433 rows=98999 loops=1)
Index Cond: ((id > 1000) AND (id < 100000))
Planning Time: 0.182 ms
Execution Time: 25.064 ms
(4 rows)
db_test=# EXPLAIN (ANALYZE, TIMING) SELECT * FROM toast_test_4096_threshold where id > 1000 and id < 100000;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------------------------
Index Scan using idx_toast_1 on toast_test_4096_threshold (cost=0.42..36565.48 rows=100353 width=2056) (actual time=0.040..142.147 rows=98999 loops=1)
Index Cond: ((id > 1000) AND (id < 100000))
Planning Time: 0.196 ms
Execution Time: 145.957 ms
(4 rows)
至此我们得出结论:
1)全表扫描的情况下, 无论是否 select 选项里有大字段, toast 的表只会扫描指针, 会比本地存储的表,快很多
2)索引扫描的情况下, 如果索引的选择率高,(high selectivity, high cardinality ), 返回的行少, 那么二者差别不大,
如果索引的选择率低,或者大范围索引扫描的话, 本地存储会比toast 的慢很多。
最后share 几个关于 PG 查询表大小的函数的区别:
pg_table_size: 会得到表的总大小(包含toast表,不包含索引)
pg_relation_size: 只会得到表本身的大小
pg_total_relation_size:会得到表的全部大小(包含toast, index的大小)
SELECT
c1.relname,
pg_size_pretty(pg_relation_size(c1.relname::regclass)) AS size,
c2.relname AS toast_relname,
pg_size_pretty(pg_relation_size(('pg_toast.' || c2.relname)::regclass)) AS toast_size,
pg_size_pretty(pg_total_relation_size((c1.relname::regclass)::regclass)-pg_table_size((c1.relname::regclass)::regclass)) AS index_total_size
FROM
pg_class c1
JOIN pg_class c2 ON c1.reltoastrelid = c2.oid
WHERE
c1.relname LIKE 'toast_test_%'
AND c1.relkind = 'r';
relname | size | toast_relname | toast_size | index_total_size
------------------------------+---------+------------------+------------+------------------
toast_test_default_threshold | 25 MB | pg_toast_4844457 | 1302 MB | 11 MB
toast_test_4096_threshold | 1302 MB | pg_toast_4844467 | 0 bytes | 11 MB
(2 rows)
Have a fun! 😃
