




本文将展示在处理分层数据结构时,列传播如何代表一种提高查询性能的简单方法。
我们将通过一个基于数据驱动的项目的真实场景来实现这一点,该项目涉及为体育行业的初创企业开发的实时数据网站。作为分层SQL表结构固有性能问题的解决方案,您将了解关于列传播的所有需要了解的内容。让我们开始吧。
发生情境
我和我的团队最近为拥有数百万页面的足球迷开发了一个网站。该网站的想法是成为足球支持者的权威资源。数据库和应用程序架构并不特别复杂。这是因为调度器负责定期重新计算复杂数据并将其存储在表中,以便查询不必涉及SQL聚合。因此,真正的挑战在于非功能性需求,例如性能和页面加载时间。
应用领域
体育行业中有多家数据提供商,每一家都为其客户提供不同的数据集。具体来说,足球行业有四种类型的数据:
1.传记数据:身高、宽度、年龄、他们效力的球队、获得的奖杯、获得的个人奖项以及足球运动员和教练。
2.历史数据:过去比赛的结果以及这些比赛中的事件,例如进球、助攻、黄牌、红牌、传球等。
3.当前和未来数据:本赛季比赛的结果和这些比赛中发生的事件,以及未来比赛的表格。
4.实时数据:正在进行的游戏的实时结果和实时事件。
我们的网站涉及所有这些类型的数据,特别注意历史数据的SEO原因和现场数据用以支持投注。
分层表结构
由于我签署的保密协议,我无法与您共享整个数据结构。同时,了解足球赛季的结构就足以理解这一真实场景。
具体而言,足球供应商通常按以下方式组织一个赛季的比赛数据:
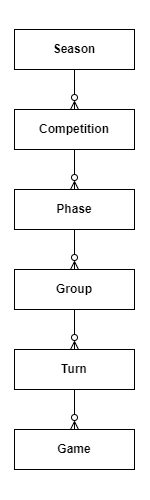
季节:有开始和结束日期,通常持续一个日历年
竞争:比赛所属的联赛。一个赛季内有一场比赛。在这里了解更多关于足球比赛如何运作的信息。
阶段:与比赛相关的阶段(例如资格赛阶段、淘汰赛阶段、决赛阶段)。每个比赛都有自己的规则,许多比赛只有一个阶段。
组:与相位相关的组(例如,A组、B组、C组……)。有些比赛,如世界杯,涉及不同的小组,每个小组都有自己的球队。大多数比赛对所有球队只有一个普通组。
回合:从逻辑角度来看,相当于一天的比赛。它通常持续一周,涵盖属于一个小组的所有球队的比赛(例如,大联盟有17场主场比赛和17场客场比赛;因此,它有34个回合)。
比赛:两队之间的比赛。
如ER模式中所示,这5个表表示分层数据结构:
技术、规格和性能要求
我们在节点中开发了后端。js 和TypeScript 与 Express 4.17.2和 Sequelize 6.10 一起作为 ORM(对象关系映射)。前端是下一个。js 12应用程序是用 TypeScript 开发的。至于数据库,我们决定选择由AWS托管的 Postgres 服务器。
该网站运行在 AWS Elastic Beanstalk 上,前端有12个实例,后端有8个实例,目前每天有1k到5k的观众。我们客户的目标是在一年内达到每天6万次的浏览量。因此,该网站必须准备好每月接待数百万用户,而不会出现性能下降。
在谷歌灯塔测试中,该网站的性能、搜索引擎优化和可访问性得分应达到80分以上。此外,加载时间应始终小于2秒,理想情况下为数百毫秒。真正的挑战在于此,因为该网站由200多万页组成,预渲染将需要数周时间。此外,大多数页面上显示的内容不是静态的。因此,我们选择了增量静态再生方法。当一个访问者点击了一个从来没有人访问过的页面,接下来。js 使用从后端公开的API检索的数据生成它。然后,下一步。js 根据页面的重要性将页面缓存30秒或60秒。
因此,后端必须快速提供服务器端生成过程所需的数据。
为什么查询分层表很慢
现在,让我们看看为什么层次表结构可以代表性能挑战。
连接查询速度慢
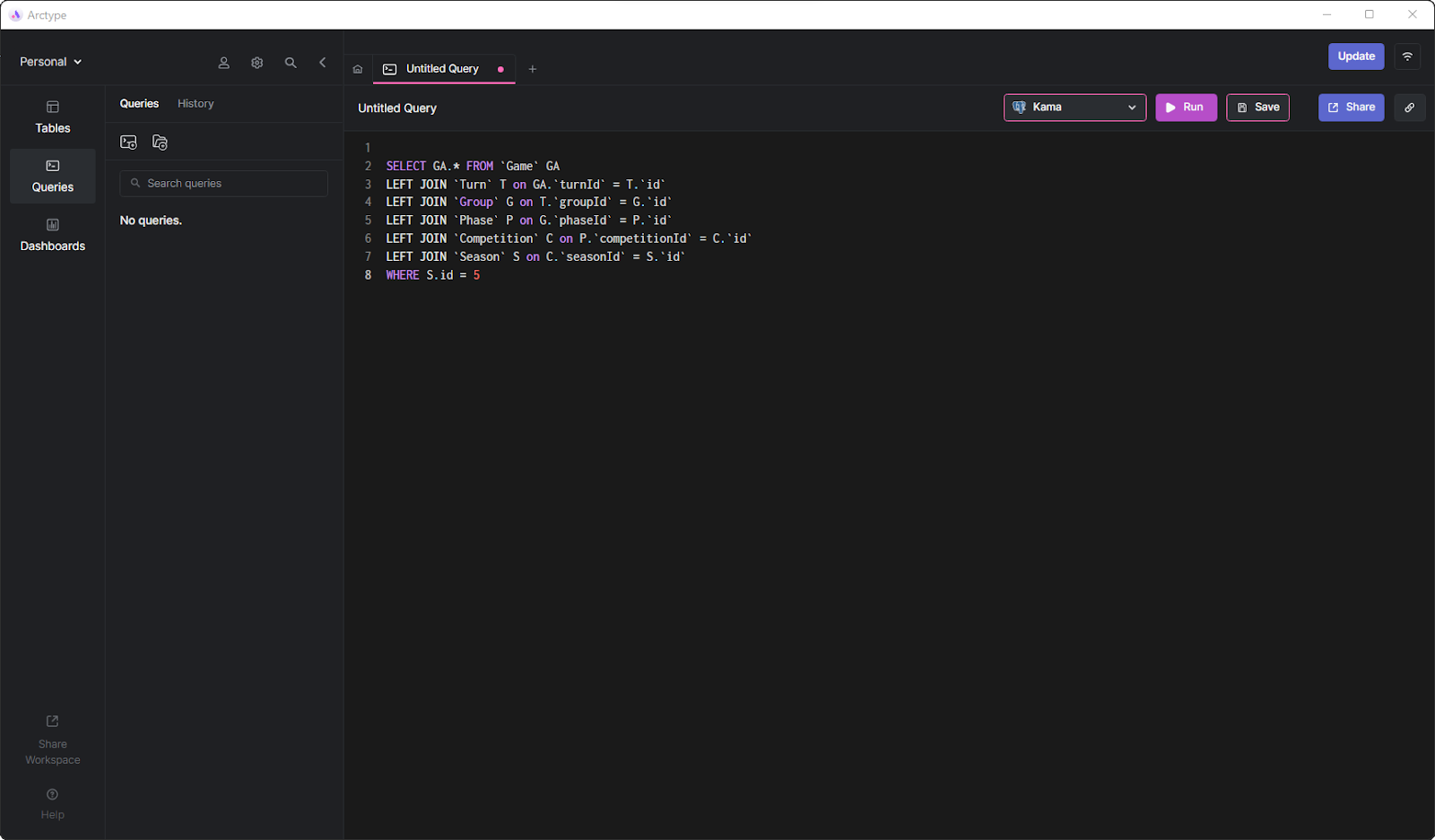
层次数据结构中的一种常见场景是,您希望根据与层次中更高层次的对象相关联的参数来过滤叶子。例如,您可能希望检索在特定季节中玩的所有游戏。由于叶表游戏没有直接连接到季节,因此必须执行一个查询,该查询涉及的连接数与层次结构中的元素数相同。因此,您可能会编写以下查询:
SELECT GA.* FROM `Game` GA
LEFT JOIN `Turn` T on GA.`turnId` = T.`id`
LEFT JOIN `Group` G on T.`groupId` = G.`id`
LEFT JOIN `Phase` P on G.`phaseId` = P.`id`
LEFT JOIN `Competition` C on P.`competitionId` = C.`id`
LEFT JOIN `Season` S on C.`seasonId` = S.`id`
WHERE S.id = 5
这样的查询速度很慢。每个连接执行笛卡尔乘积操作,这需要时间,可能会产生数千条记录。因此,层次数据结构越长,性能就越差。
此外,如果您想检索所有数据,而不仅仅是游戏表中的列,那么由于笛卡尔乘积的性质,您将不得不处理数千行数百列。这可能会变得混乱,但这就是ORM发挥作用的地方。
ORM数据解耦和转换需要时间
当通过ORM查询数据库时,您通常感兴趣的是在其应用程序级表示中检索数据。原始数据库级表示在应用程序级可能没有用处。因此,当大多数高级orm执行查询时,它们从数据库中检索所需的数据,并将其转换为应用程序级表示。这个过程包括两个步骤:数据解耦和数据转换。
在后台,来自连接查询的原始数据首先被解耦,然后在应用程序级别转换为各自的表示。因此,在处理所有数据时,具有数百列的数千条记录成为一个小数据集,每个记录都具有在数据模型类中定义的属性。因此,包含从数据库中提取的原始数据的数组将成为一组游戏对象。每个游戏对象都有一个包含其各自回合实例的回合场。然后,转弯对象将有一个组字段,存储其各自的组对象等。
生成这种转换后的数据是您愿意接受的开销。处理杂乱的原始数据具有挑战性,并会导致代码警报。另一方面,这一过程发生在幕后需要时间,你不能忽视它。当原始记录有数千行时,情况尤其如此,因为处理存储数千个元素的数组总是很棘手。
换句话说,在数据库层和应用程序层,对分层表结构的常见连接查询都很慢。
作为解决方案的列传播
解决方案是在层次结构中将列从父级传播到其子级,以避免此性能问题。让我们了解原因。
为什么应该在分层数据库上传播列
在分析上述连接查询时,很明显问题在于对叶表游戏应用过滤器。你必须遍历整个层次结构。但是,既然游戏是层次结构中最重要的元素,为什么不直接添加季节ID、竞争ID、阶段ID和组ID列呢?这就是列传播的意义!
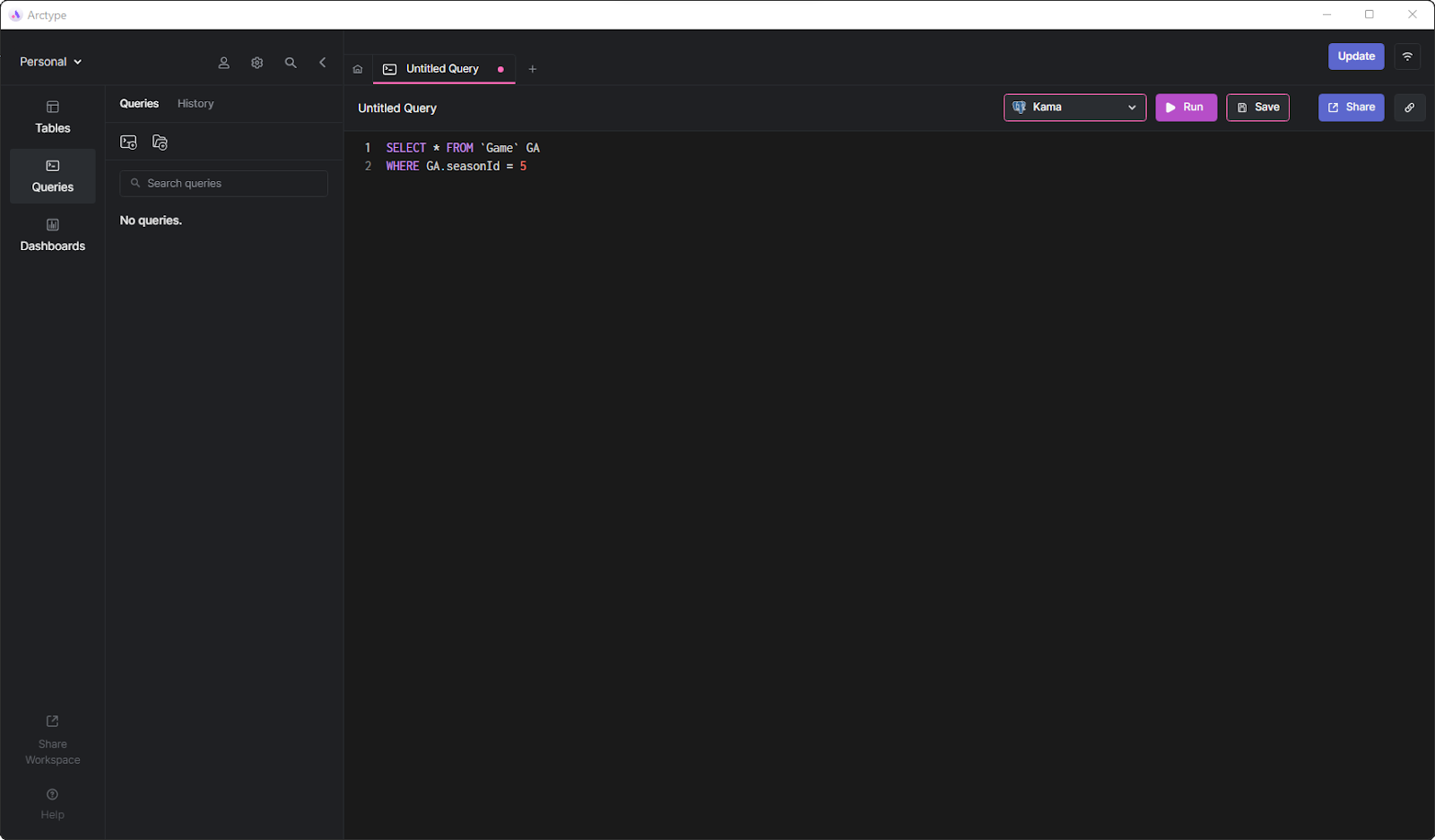
通过将外部键列直接传播到子级,可以避免所有连接。现在,您可以将上面的查询替换为以下查询:
SELECT * FROM `Game` GA
WHERE GA.seasonId = 5
可以想象,此查询比原始查询快得多。此外,它直接返回您感兴趣的内容。因此,您现在可以忽略ORM数据解耦和转换过程。
请注意,列传播涉及数据复制,您应该谨慎而明智地使用它。但是在深入研究如何熟练地实现它之前,让我们看看应该传播哪些列。
如何选择要传播的列
如果您向下传播层次结构中较高的实体的每一列,这将有所帮助;这在过滤方面可能很有用。例如,这涉及到外部键。此外,您可能希望传播用于过滤数据的枚举列,或使用来自父级的聚合数据生成列,以避免连接。
列传播的前三种方法
当我的团队选择列传播方法时,我们考虑了三种不同的实现方法。让我们分析一下。
1、创建物化视图
我们必须在层次表结构中实现列传播的第一个想法是创建具有所需列的物化视图。物化视图存储查询结果,通常表示复杂查询(如上面的连接查询)的行和/或列的子集。
对于物化查询,您可以定义何时生成视图。然后,您的数据库负责将其存储在磁盘上,并使其像普通表一样可用。即使生成查询可能很慢,您也只能谨慎地启动它。因此,物化视图代表了一种快速解决方案。
另一方面,物化视图不是处理实时数据的最佳方法。这是因为物化视图可能不是最新的。它存储的数据取决于您决定何时生成视图或刷新视图。此外,涉及大数据的物化视图会占用大量磁盘空间,这可能是一个问题,并会耗费您的存储成本。
2、定义虚拟视图
另一种可能的解决方案是使用虚拟视图。同样,虚拟视图是存储查询结果的表。与物化视图的不同之处在于,这次数据库不会将查询结果存储在磁盘上,而是将其保存在内存中。因此,虚拟视图总是最新的,可以解决实时数据的问题。
另一方面,每次访问视图时,数据库都必须执行生成查询。因此,如果生成查询需要时间,那么涉及视图的整个过程只能很慢。虚拟视图是一个强大的工具,但考虑到我们的性能目标,我们不得不寻找另一种解决方案。
3、使用触发器
SQL触发器允许您在数据库中发生特定事件时自动启动查询。换句话说,触发器使您能够跨数据库同步数据。因此,通过在层次结构表中定义所需的列并让自定义触发器更新它们,您可以轻松实现列传播。
可以想象,触发器会增加性能开销。这是因为每次它们等待的事件发生时,数据库都会执行它们。但是执行查询需要时间和内存。因此,触发器是有成本的。另一方面,这种成本通常可以忽略不计,尤其是与虚拟或物化视图的缺点相比。
触发器的问题是,定义它们可能需要一些时间。同时,您只能处理此任务一次,并在需要时进行更新。因此,触发器允许您轻松地实现列传播。此外,由于我们采用了列传播并使用触发器实现了它,因此我们在很大程度上满足了客户定义的性能要求。
层次结构在数据库中很常见,如果处理不当,可能会导致应用程序中的性能问题和效率低下。这是因为它们需要长连接查询和ORM数据处理,速度慢且耗时。幸运的是,您可以通过将列从父级传播到层次结构中的子级来避免这一切。我希望这个真实的案例研究可以帮助您构建更好更快的应用程序!
原文标题:Improving Performance in a Hierarchical SQL Structure
原文作者:Antonello Zanini
原文地址:https://dzone.com/articles/improving-performance-in-a-hierarchical-sql-struct
