




Simple Nested-Loop Join
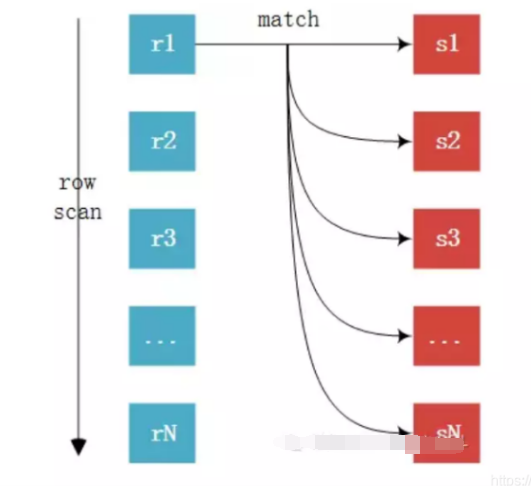
如下图,r为驱动表,s为匹配表,可以看到从r中分别取出r1、r2、......、rn去匹配s表的左右列,然后再合并数据,对s表进行了rn次访问,对数据库开销大
在没有索引的情况下,会进行n次的全表扫描
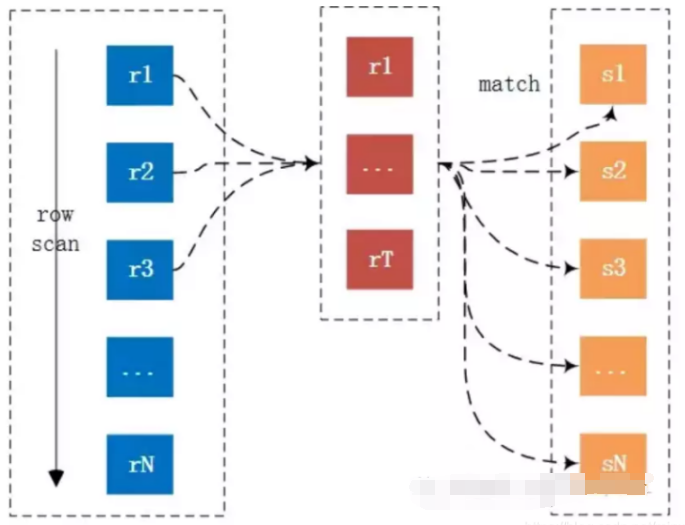
Index Nested-Loop Join(索引嵌套)
这个要求非驱动表(匹配表s)上有索引,可以通过索引来减少比较,加速查询。
在查询时,驱动表(r)会根据关联字段的索引进行查找,挡在索引上找到符合的值,再回表进行查询,也就是只有当匹配到索引以后才会进行回表查询。
如果非驱动表(s)的关联健是主键的话,性能会非常高,如果不是主键,要进行多次回表查询,先关联索引,然后根据二级索引的主键ID进行回表操作,
性能上比索引是主键要慢。
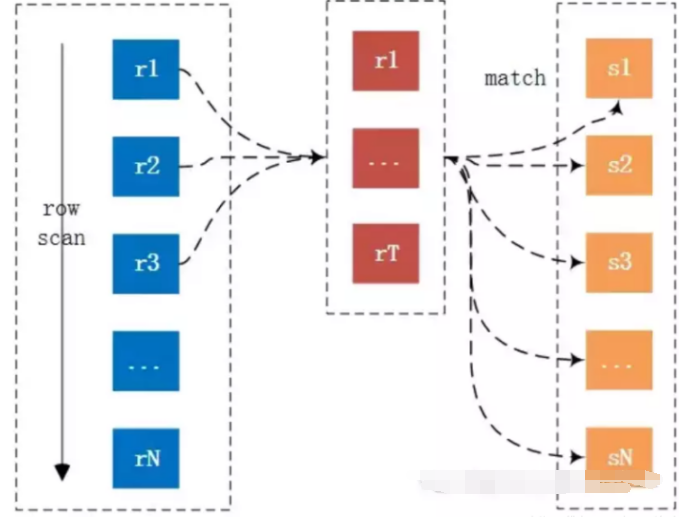
Block Nested-Loop Join
如果有索引,会选取第二种方式进行join,但如果join列没有索引,就会采用Block Nested-Loop Join。可以看到中间有个join buffer缓冲区,是将驱动表的所有join相关的列都先缓存到join buffer中,然后批量与匹配表进行匹配,将第一种多次比较合并为一次,降低了非驱动表(s)的访问频率。默认情况下join_buffer_size=256K,在查找的时候MySQL会将所有的需要的列缓存到join buffer当中,包括select的列,而不是仅仅只缓存关联列。在一个有N个JOIN关联的SQL当中会在执行时候分配N-1个join buffer。
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
