




前言
Flink TableAPI & SQL允许用户使用functions对数据进行各种transformations操作,这个也是计算引擎的基本能力。
Flink functions可以分为system函数(即内置函数)、catalog函数;system函数没有命名空间,直接使用名称引用;catalog函数有catalog、database命名空间(作用域有限制:catalog.db.func或db.func)。
Flink functions也可以分为temporary functions(临时函数)、persistent functions(永久函数);临时函数的生命周期仅限于当前session,由用户创建;而永久函数生命周期为所有session,由内置函数或catalog函数提供。
温馨提示:微信公众号私信有时效性、过期不可回复,很多朋友私信我没及时看到、未能回复。最近新建钉钉群(44703541),欢迎朋友加入!
系统内置函数
Flink提供丰富的内置函数:Scalar Functions、Aggregate Functions、Column Functions、Time Interval and Point Unit Specifiers等。详见
https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/dev/table/functions/systemfunctions/#system-built-in-functions
如果特定业务场景使用内置函数无法满足开发需求的话,可以自行实现User-defined Functions(即我们常说的UDF函数)。
UDF函数
JVM(Java/Scala)、Python都支持用户自定义函数。
Flink UDF支持如下:
Scalar functions:映射scalar值为新scalar值Table functions:映射scalar值为新rowsAggregate functions:映射多个rows的scalar值为新scalar值Table aggregate functions:映射多个rows的scalar值为新rowsAsync table functions:table source执行查询操作
DataStream UDF实战案例
通过实现MapFunction接口,实现一个我们测试用的DataStream UDF函数MyMapFunction1。
public class MyMapFunction1 implements MapFunction{@Overridepublic String map(String s) throws Exception {return s + " " + new Date();}}
编译打包为UserDefinedFunctions-1.0.jar
实际开发有两种使用该UDF的方法:直接new或者反射。当然推荐反射方式,这样UDF迭代更新时,业务代码并不需要修改、仅需重启即可。
//方法1:通过反射newInstance实例化对象。优点:解耦、可配置类名称String mapFunctionClassName = null;if (args.length == 1 && args[0] != null) {mapFunctionClassName = args[0];} else {mapFunctionClassName = "MyMapFunction1";}Class myMapFunction = Class.forName(mapFunctionClassName);Object object = myMapFunction.newInstance();socketData.map((MapFunction Object>) object).print()//方法2:通过new实例化对象。缺点:耦合固定类名称//socketData.map(new MyMapFunction()).print();//socketData.map(new MyMapFunction1()).print();
完整案例见:
https://github.com/felixzh2020/felixzh-learning-flink/blob/master/FlinkIdeaDemo/src/main/java/NCFlinkUDFIdea.java
启动命令:
[root@felixzh home]# nc -l 4444[root@felixzh home]# java -cp FlinkIdeaDemo-1.0.jar:UserDefinedFunctions-1.0.jar NCFlinkIdea MyMapFunction1

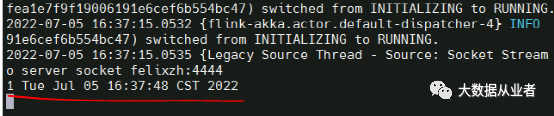
从上图可以看出UDF结果为输入值+当前时间,符合预期。
SQL UDF实战案例
通过继承ScalarFunction类,实现一个SQL UDF函数JsonFunction。
/*** 标量函数:必要有eval方法。* 方法名必须为eval,输入参数类型和个数自定义、返回值类型自定义*/public static class JsonFunction extends ScalarFunction {public String eval(String line) {return line + ":" + line;}}
StreamTableEnvironment实例执行SQL语句之前,需要先注册UDF函数:
//注册的Function名称自定义任意值tEnv.createTemporarySystemFunction("JsonFunction1", JsonFunction.class);
然后,再跟之前一样执行SQL语句:
// execute a Flink SQL job and print the result locallytEnv.executeSql(/ define the aggregation"SELECT JsonFunction1(word), frequency\n"// read from an artificial fixed-size table with rows and columns+ "FROM (\n"+ " VALUES ('Hello', 1), ('Ciao', 1), ('felixzh', 2)\n"+ ")\n"// name the table and its columns+ "AS WordTable(word, frequency)\n").print();
完整案例见:
https://github.com/felixzh2020/felixzh-learning-flink/blob/master/FlinkIdeaDemo/src/main/java/NCFlinkSqlUDFIdea.java
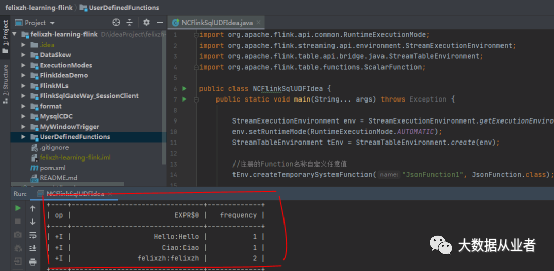
从上图可知UDF处理结果为字段值+字段值,符合预期。
