




在我作为微软Postgres团队的一名工程师的工作中,我遇到了在许多具有挑战性的项目中遇到的各种各样的客户。我最近参与的一个数据库迁移项目是一个需要讲述的故事。零售领域的客户使用Redshift作为数据仓库,使用Databricks作为他们的ETL引擎。他们的安装部署在AWS和GCP上,跨越不同地区的不同数据中心。他们已经遇到了性能瓶颈,同时也产生了不必要的退出成本。
具体来说,客户分析存储中的数据量增长速度超过了处理这些数据所需的计算速度。AWS Redshift无法提供独立的存储和计算能力——因此我们的客户不得不为不断增长的数据量增加Redshift节点,从而支付额外的成本。为了解决这些问题,他们决定将他们的分析领域迁移到Azure上。
将Databricks迁移到Azure很简单,因为Databricks可以作为Azure上的第一方服务。在数据库方面,Azure提供了多种数据库服务,所以我们的客户有一些选择。客户的数据量并不大,大约是500gb,这让他们想知道:他们应该选择PostgreSQL,因为Redshift是基于Postgres的,它可能会减少迁移的工作量。他们的问题是:单一的Postgres节点能提供合适的性能吗?或者他们应该选择纯分析存储,这可能不是必需的,并招致额外的迁移工作。
这篇文章将带领您了解我们的考虑事项、测试、需求、障碍等等,因为我们帮助客户确定哪种数据库可以确保提高性能和降低成本的最佳平衡——同时也可以用最简单的方式迁移Redshift。

交互式分析仪表板需要快速的查询响应
在数据迁移出Redshift之前,客户一直使用Redshift数据仓库来存储和分析与他们网站上的用户事件、销售、营销、支持等相关的数据。这些数据来自各种来源(应用程序),负载接近实时(每1小时)。因此,Redshift数据仓库是他们分析(OLAP)故事的核心部分。
他们使用开源的Metabase作为BI工具来生成仪表板和可视化所有数据——他们有将近600个查询需要从Redshift迁移过来。由于仪表板是面向终端用户的,查询必须执行得非常好,即查询响应时间以一位数秒为单位。此外,分析仪表板具有很强的互动性,即用户可以在20多个不同维度上进行筛选和切片。大约有200个Databricks作业(又名Apache Spark)用于转换和清理存储在数据仓库中的数据,并为从Metabase查询数据做好准备。
单个Postgres节点是否能够提供所需的性能?
由于Amazon的Redshift数据仓库是基于PostgreSQL的(Redshift是Postgres的一个专有分支),而我们的客户的数据容量约500GB并不大,所以客户决定首先在单个服务器上测试普通PostgreSQL,看看单节点Postgres数据库是否能达到要求。他们在Azure数据库中测试了PostgreSQL -单服务器,这是在Azure上为Postgres提供的PaaS。然而,单个Postgres服务器不足以满足客户的应用程序:在Redshift上运行的SQL查询在单个Postgres节点上需要40秒才能完成。这是因为,尽管Postgres提供了可以使用多个线程并行化单个查询的并行查询特性,但它在查询类型和查询计划的哪些部分可以并行化方面是有限制的。因此,我们无法最大化底层硬件资源来改善查询延迟。
此时,我们的团队建议客户在Azure数据库中尝试Hyperscale (Citus)部署选项。
如果您不熟悉Citus,那么可以快速入门:Hyperscale (Citus)是由Citus构建的,它是Postgres的一个开源扩展。在Azure上,Hyperscale (Citus)将Postgres转换成一个分布式数据库,这样你就可以跨服务器组中的多个节点对数据进行分片/分区,使你的Postgres查询能够使用服务器组(即分布式集群)中的所有CPU、内存和存储。Hyperscale (Citus)具有内置逻辑,可以将单个查询转换为多个查询,并跨多个分区(称为分片)异步(并行)运行它们,以有效的方式最大化性能。Citus提供的查询并行性扩展到各种SQL构造—包括join、子查询、GROUP by、CTEs、WINDOW函数等等。
使用Hyperscale (Citus)水平扩展Postgres的一个重要前提是决定你的分布列将是什么。(有些人称分布列为“分布键”或“分片键”)大多数情况下,根据应用程序的使用情况,选择分布列是非常直观的。例如,对于该客户,对于从访问其网站的用户捕获事件的单击流工作负载,我们选择user_id,因为它是一个自然的分片键,因为事件来自于用户,仪表板用于分析和理解用户行为。Hyperscale (Citus)的架构图如下:
 图1:Hyperscale (Citus)分布式数据库由协调节点和工作节点组成。每个节点都是一个安装了Citus扩展的Postgres服务器。Citus协调器将Postgres查询编排到正确的工作节点,工作节点是实际数据存在和计算发生的地方。查询要么路由到单个工作节点,要么在更小的表/索引(称为shard)上执行(OR),在工作节点间并行执行。Citus架构非常类似于大规模并行处理(MPP)数据库;不同的是,使用Citus,你可以获得并行的好处,以及postgresql - join、GROUP by、窗口函数、CTEs、JSONB、HLL、PostGIS等的好处。
图1:Hyperscale (Citus)分布式数据库由协调节点和工作节点组成。每个节点都是一个安装了Citus扩展的Postgres服务器。Citus协调器将Postgres查询编排到正确的工作节点,工作节点是实际数据存在和计算发生的地方。查询要么路由到单个工作节点,要么在更小的表/索引(称为shard)上执行(OR),在工作节点间并行执行。Citus架构非常类似于大规模并行处理(MPP)数据库;不同的是,使用Citus,你可以获得并行的好处,以及postgresql - join、GROUP by、窗口函数、CTEs、JSONB、HLL、PostGIS等的好处。
选择Hyperscale (Citus)来驱动分析工作负载
实时分析是Hyperscale (Citus)的一大亮点。分布式Postgres数据库的MPP特性以及与PostgreSQL生态系统的密切关系使得Hyperscale (Citus)成为从Redshift迁移的一个令人信服的选择。
客户测试了Hyperscale (Citus),发现在类似规模(硬件)的情况下,其性能比Redshift平均提高了约2倍。他们采用了一个2工作节点的Hyperscale (Citus)集群,每个工作节点拥有8vcore (64GB RAM)和512GB存储空间。因此,数据库的总功耗为16vcore、128GB RAM和~3000 IOPs (3 IOPs/GB存储)。下面是从迁移过程中学到的一些东西。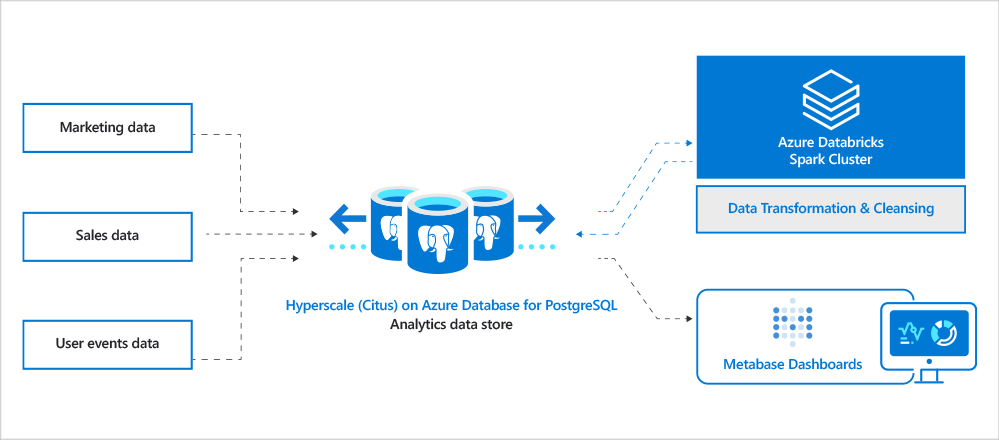
图2:客户分析全景的架构图。包括不同类型的数据源,包括销售、市场营销、用户活动、支持等。数据被Hyperscale (Citus)吸收。Azure Databricks被用作ETL引擎来清理和转换数据,以生成最终的数据集,最终用户可以通过交互的Metabase分析仪表板看到这些数据集。
查询并行性和Postgres索引比Redshift提高了约2倍的性能
在需要对许多不同的列组合进行过滤,而又无法为这些查询扫描整个数据集的工作负载中,查询并行性和索引是游戏规则的改变者。在Hyperscale (Citus)中创建索引的能力确实很有帮助。红移对于索引不是很灵活;你不能运行CREATE INDEX命令,因为Redshift是一个柱状存储。但是,使用Hyperscale (Citus),在创建索引方面可以获得与Postgres相同的灵活性。即使是CREATE INDEX和CREATE INDEX concurrent也可以跨工作节点并行,这可以带来巨大的性能优势。(并发地避免在索引创建期间阻塞写。)我们听说有客户报告说,使用Hyperscale (Citus)创建索引的性能提高了大约5-10倍。
在这个客户场景中,我们创建了30-40多个索引来加快他们的Postgres查询。因为他们的分析应用的交互特性,有很多基于不同维度的动态过滤——使用Postgres索引绝对有帮助。
使用JSONB存储半结构化数据
因为Redshift不支持JSON/JSONB数据类型,我们的客户被迫将他们的大型JSON文档作为文本列存储在Redshift中——而且他们还必须使用Redshift提供的JSON函数来解析JSON文档。好消息是,由于Hyperscale (Citus)本机支持Postgres JSON/JSONB数据类型,您可以存储和查询JSON文档,并且可以使用JSONB以二进制格式存储JSON文档。
作为迁移过程的一部分,我们决定在Hyperscale (Citus)中使用JSONB数据类型而不是文本,这样我们的客户就可以从JSONB中获益——Postgres原生支持JSONB的一组健壮的函数,以及使用GIN类型索引为JSONB列建立索引的能力。通过使用Postgres的最新特性,这不仅有助于应用程序的现代化,而且还带来了显著的性能提升——直接查询JSONB比将文本类型转换为JSON然后查询要好。如果你还没有在Postgres中尝试过JSONB,我强烈建议你尝试一下——它已经改变了许多客户的游戏规则!😄
Postgres中的JSONB数据类型也可以提供6x-7x的压缩
我们观察到的一个有趣的现象是,Hyperscale (Citus)的存储占用面积仅略高于Redshift (Hyperscale (Citus)的550GB vs Redshift的500GB)。由于红移以柱状格式存储数据,它的压缩效果非常好。由于Hyperscale (Citus)是一个基于行的存储,我们预计Hyperscale (Citus)的存储占用空间会明显更高,但我们惊讶地看到,与Redshift相比,存储占用空间的增加非常低,即使有30-40个Postgres索引。
在Postgres中使用JSONB数据类型(该类型天生就会压缩JSON文档(使用toast))产生了差异。随着JSON文档大小的增加,压缩率也会增加。我们已经看到了超过7倍的压缩,一些客户存储大型JSON文档(以mb为单位)。
从Redshift到Hyperscale(Citus)的迁移工作耗时约2周
因为Redshift也是基于PostgreSQL的,所以迁移的工作量很小。总的来说,从Redshift到Hyperscale (Citus)的端到端迁移只花了大约两周的时间。如前所述,第一步是选择正确的分布列,以便告知Hyperscale (Citus)您希望如何跨Hyperscale (Citus)集群中的所有节点对数据进行分片。下一步是决定哪些表应该在Hyperscale (Citus)集群中的所有节点上分布,哪些表应该被引用。完成之后,进行代码更改—包括更改一些SQL查询和数据堆作业—然后使用简单的Postgres pg_dump和pg_restore实用程序进行数据迁移。
在Azure数据库中从Redshift到Hyperscale (Citus)的迁移过程中的一些经验教训:
- 表:迁移了180个表。其中超过80个节点分布在工作节点上。
- 查询迁移:
80%的查询是直接进入的,没有任何修改!
18%的查询需要更改Redshift->Postgres语法才能从文本->JSONB转换中获得好处。我们没有使用Redshift提供的函数,而是使用了Postgres提供的本地JSONB函数/操作符。
2%的查询需要更新与Hyperscale (Citus)相关的查询,即与分布式表相关的查询。 - 数据ricks任务:200个数据ricks任务几乎是不需要更改的,因为Redshift使用的JDBC驱动程序和Postgres/Hyperscale (Citus)的JDBC驱动程序是一样的。
Hyperscale(Citus)有一个共享的无任何架构
Hyperscale (Citus)拥有一个共享的nothing架构,即集群中的每个节点都有自己的计算和存储。我们让你的比例上升/下降计算协调员和工人分别。如果你只是想扩展存储而不是计算,你也可以通过独立扩展worker和coordinator上的存储来实现。我们的客户发现这是一种有效的优化成本的方法,特别是因为使用Redshift他们无法独立扩展存储。
与此同时,我们还提供了横向扩展的能力。你可以轻松地向Azure上的Hyperscale (Citus)服务器组添加更多的服务器,并以在线方式重新平衡数据。我所说的“在线”是指在将数据从现有服务器重新平衡到集群中的新服务器时,读写操作不需要停机(集群=服务器组,我将这两个术语互换使用)。
从红移到超尺度迁移的一些最佳地点(Citus)
根据我们的经验,对于从Redshift迁移到特定工作负载的客户来说,Azure PostgreSQL - Hyperscale (Citus)可能是一个引人注目的选择。正如上面的案例研究所说明的,下面是Hyperscale (Citus)的一些最佳点。如果您的工作负载有一个(或)以上的最佳点,那么可以考虑将Hyperscale (Citus)作为您的分析(OLAP)存储的一个很好的候选。
- 交互式实时分析:由于列过滤器的多种排列而导致查询的不同变化。这方面的一个指标是当终端用户需要使用许多不同的参数询问问题时,这意味着他们需要使用许多不同的列过滤器进行查询。我经常这样描述它:“交互式实时仪表板/分析”vs“纯离线分析”。
- 带有事务和分析的混合工作负载:更新、删除与insert /COPY一起是工作负载的一部分(在混合工作负载中很常见,比如htap,在这个SIGMOD演示中可以看到)。
- 高并发性:超过50个终端用户同时查询数据库(也就是同时与Metabase交互分析仪表板交互),并同时获取数据。
- 对Postgres的偏好:坚持Postgres并使用其最新特性- jsonb, HLL, Partitioning, PostGIS/Geospatial等。
原文标题:Migrating interactive analytics apps from Redshift to Postgres, ft. Hyperscale (Citus)
原文作者:Sai Krishna Srirampur
原文地址:https://techcommunity.microsoft.com/t5/azure-database-for-postgresql/migrating-interactive-analytics-apps-from-redshift-to-postgres/ba-p/1825730
