





作为核心向量执行引擎,Milvus知道引擎对于跑车的意义。这篇文章介绍了Knowhere是什么,它与Faiss有什么不同,以及Knowhere的代码是如何构造的。
Knowhere的概念
狭义地说,Knowhere是一个操作界面,用于访问系统上层的服务和系统底层的向量相似性搜索库,如Faiss、Hnswlib和HARRE。此外,Knowhere还负责异构计算。更具体地说,Knowhere控制执行索引构建和搜索请求的硬件(如CPU或GPU)。Knowhere就是这样得名的——知道在哪里执行操作。未来版本将支持更多类型的硬件,包括DPU和TPU。
从更广泛的意义上讲,Knowhere还整合了其他第三方索引库,如Faiss。因此,总体而言,Knowhere被认为是Milvus矢量数据库中的核心矢量计算引擎。
从Knowhere的概念可以看出,它只处理数据计算任务,而诸如切分、负载平衡和灾难恢复等任务超出了Knowhere的工作范围。
从Milvus 2.0.1开始,Knowhere(广义上)独立于Milvus项目。
Milvus架构中的Knowhere
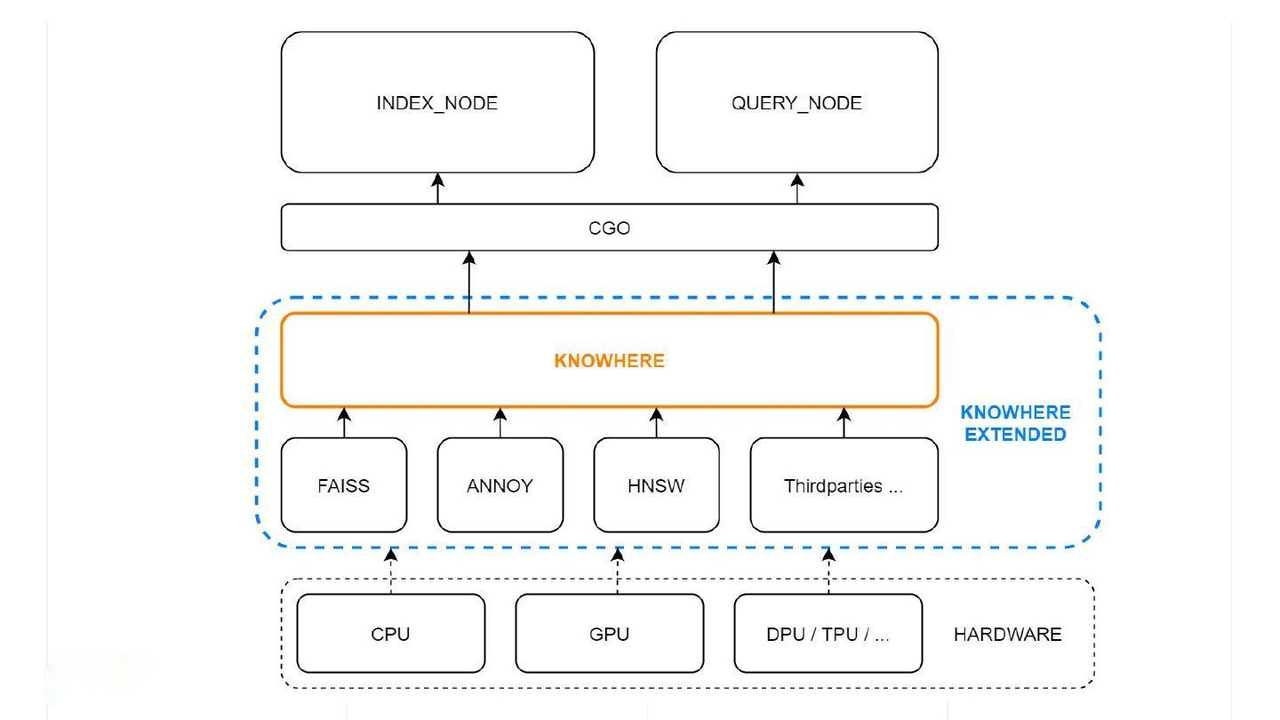
Milvus中的计算主要涉及向量和标量运算。Knowhere只处理Milvus中向量的运算。上图说明了Milvus中的Knowhere架构。
最底层是系统硬件。第三方索引库位于硬件之上。然后Knowhere通过CGO与顶部的索引节点和查询节点进行交互。
本文从更广泛的意义上讨论Knowhere,如建筑插图中的蓝色框架所示。
Knowhere Vs Faiss
Knowhere不仅进一步扩展了Faiss的功能,而且优化了性能。更具体地说,Knowhere具有以下优点。
1、支持BitsetView
最初,在Milvus中引入位集是为了“软删除”。数据库中仍存在软删除向量,但在向量相似性搜索或查询期间不会计算该向量。位集中的每个位对应一个索引向量。如果向量在位集中标记为“1”,则表示该向量是软删除的,在向量搜索过程中不会涉及。
位集参数被添加到Knowhere中所有公开的Faiss索引查询API中,包括CPU和GPU索引。
2.支持索引二进制向量的更多相似性度量
除了Hamming,Knowhere还支持Jaccard、Tanimoto、上层建筑和下层结构。Jaccard和Tanimoto可用于测量两个样本集之间的相似性,而上部结构和下部结构可用于测量化学结构的相似性。
3、支持AVX512指令集
Faiss本身支持多个指令集,包括AArch64、SSE4.2和AVX2。Knowhere通过添加AVX512进一步扩展了支持的指令集,与AVX2相比,AVX512可以将索引构建和查询的性能提高20%-30%。
4、SIMD指令自动选择
Knowhere设计用于在具有不同SIMD指令(例如SIMD SSE、AVX、AVX2和AVX512)的各种CPU处理器(包括本地和云平台)上运行良好。因此,面临的挑战是,给定一段二进制软件(即MILVU),如何使其在任何CPU处理器上自动调用适当的SIMD指令?Faiss不支持自动选择SIMD指令,用户需要在编译期间手动指定SIMD标志(例如“-msse4”)。然而,Knowhere是通过重构Faiss的代码库构建的。考虑了依赖SIMD加速的常见函数(例如相似性计算)。然后,对于每个函数,实现了四个版本(即SSE、AVX、AVX2、AVX512),每个版本都放在一个单独的源文件中。然后使用相应的SIMD标志进一步单独编译源文件。因此,在运行时,Knowhere可以根据当前的CPU标志自动选择最合适的SIMD指令,然后使用挂钩链接正确的函数指针。
5、其他性能优化
阅读Milvus:一个专门构建的矢量数据管理系统,了解有关性能优化的更多信息。
了解Knowhere代码
如第一节所述,Knowhere仅处理向量搜索操作。因此,Knowhere只处理实体的向量场(目前,一个集合中的实体只支持一个向量场)。索引构建和向量相似性搜索也针对段中的向量场。
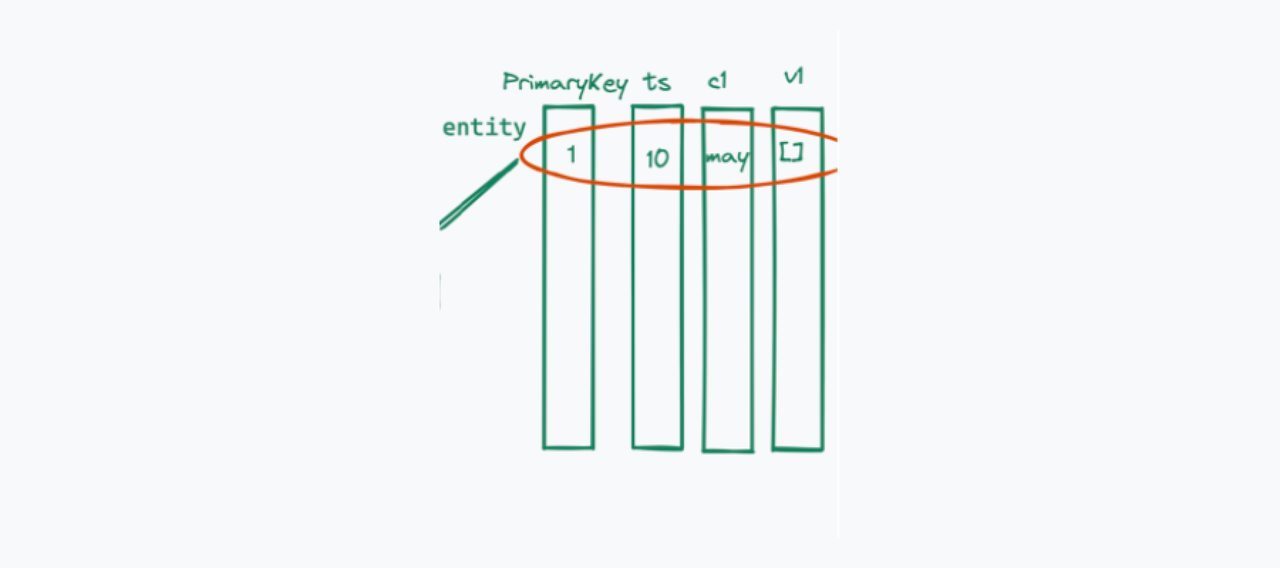
指数
索引是一种独立于原始矢量数据的数据结构。索引需要四个步骤:创建索引、插入数据、训练数据和构建索引。
对于某些人工智能应用程序,数据集训练是向量搜索的一个单独过程。在这种类型的应用中,首先对数据集的数据进行训练,然后将其插入向量数据库(如Milvus)中进行相似性搜索。像sift1M和sift1B这样的开放数据集为训练和测试提供了数据。然而,在Knowhere中,用于训练和搜索的数据混合在一起。也就是说,Knowhere训练段中的所有数据,然后插入所有训练过的数据并为其建立索引。
Knowhere代码结构
DataObj是Knowhere中所有数据结构的基类。Size()是DataObj中唯一的虚方法。索引类继承自DataObj,其中包含一个名为“size_3;”的字段。Index类还有两个虚拟方法—Serialize()和Load()。从索引派生的VecIndex类是所有向量索引的虚拟基类。VecIndex提供的方法包括Train()、Query()、GetStatistics()和ClearStatistics()。
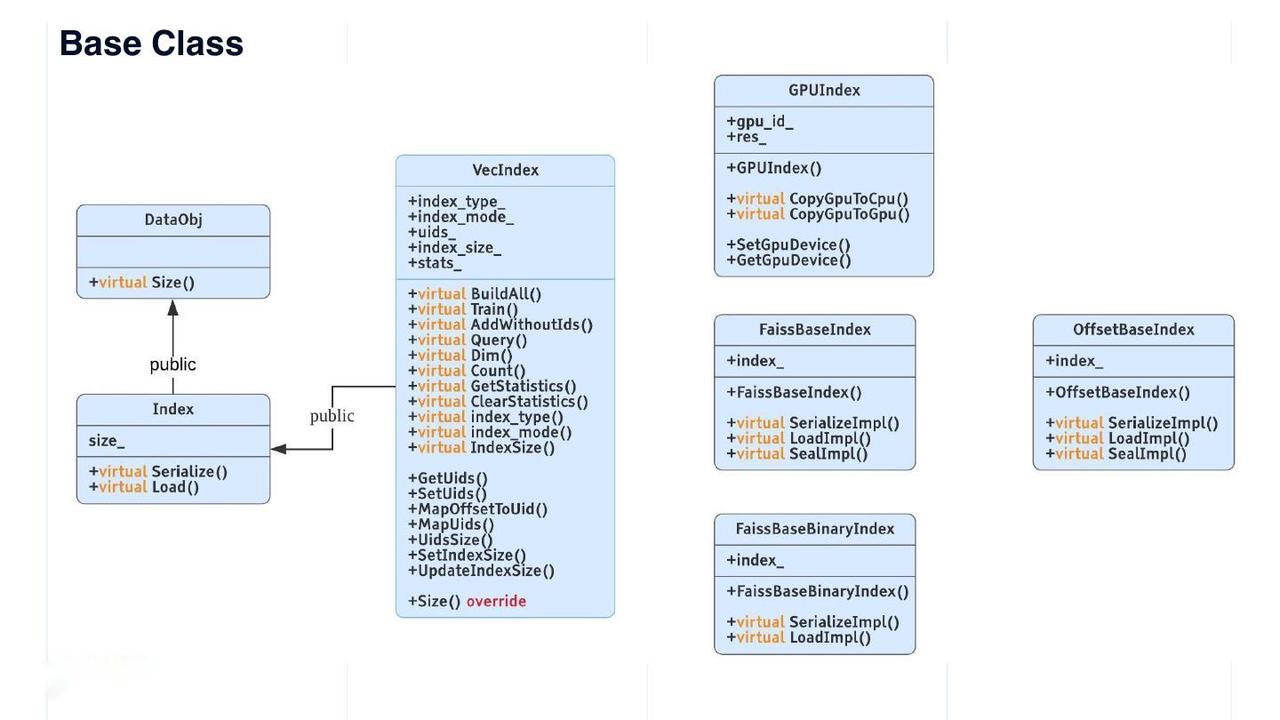
上图右侧列出了其他索引类型。
Faiss索引有两个子类:FaissBaseIndex用于浮点向量上的所有索引,FaissBaseBaryIndex用于二进制向量上的所有索引。
GPUIndex是所有Faiss GPU索引的基类。
OffsetBaseIndex是所有自行开发的索引的基类。索引文件中仅存储向量ID。因此,128维向量的索引文件大小可以减少2个数量级。我们建议在使用此类索引进行向量相似性搜索时也考虑原始向量。
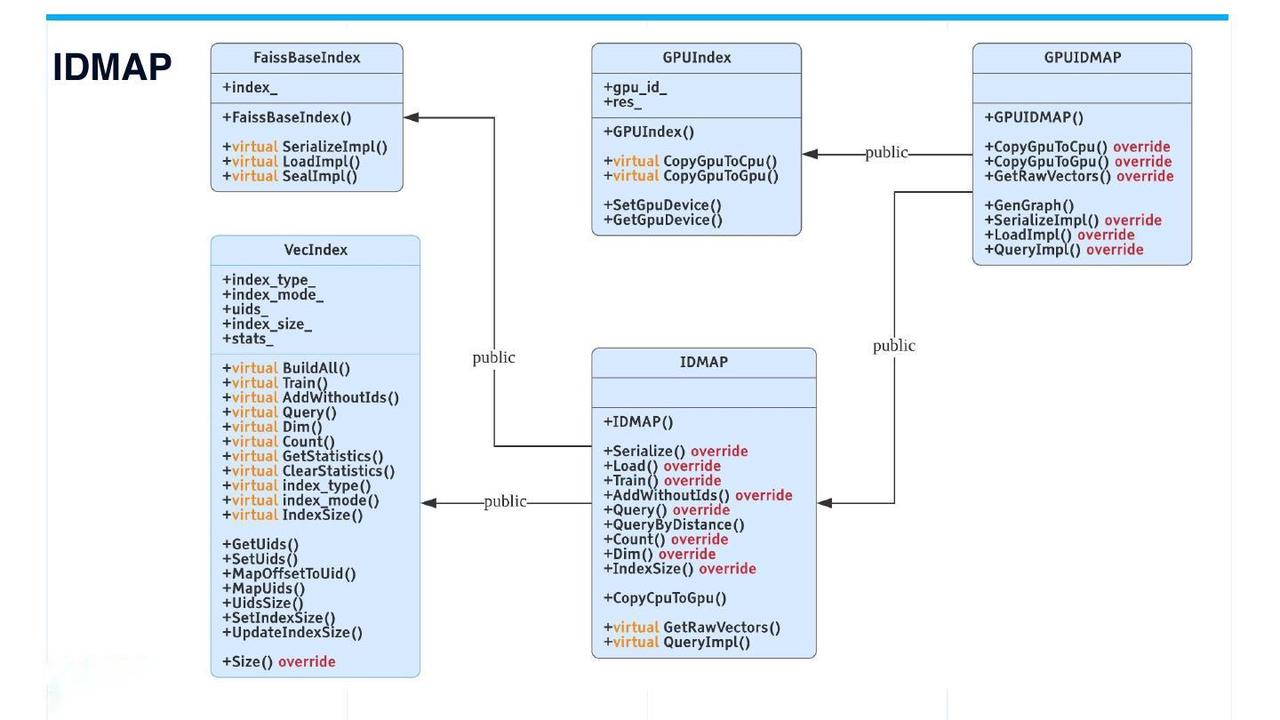
从技术上讲,IDMAP不是索引,而是用于暴力搜索。将向量插入向量数据库时,无需进行数据训练和建立索引。搜索将直接在插入的矢量数据上进行。
然而,为了代码一致性,IDMAP还继承了VecIndex类及其所有虚拟接口。IDMAP的用法与其他索引相同。
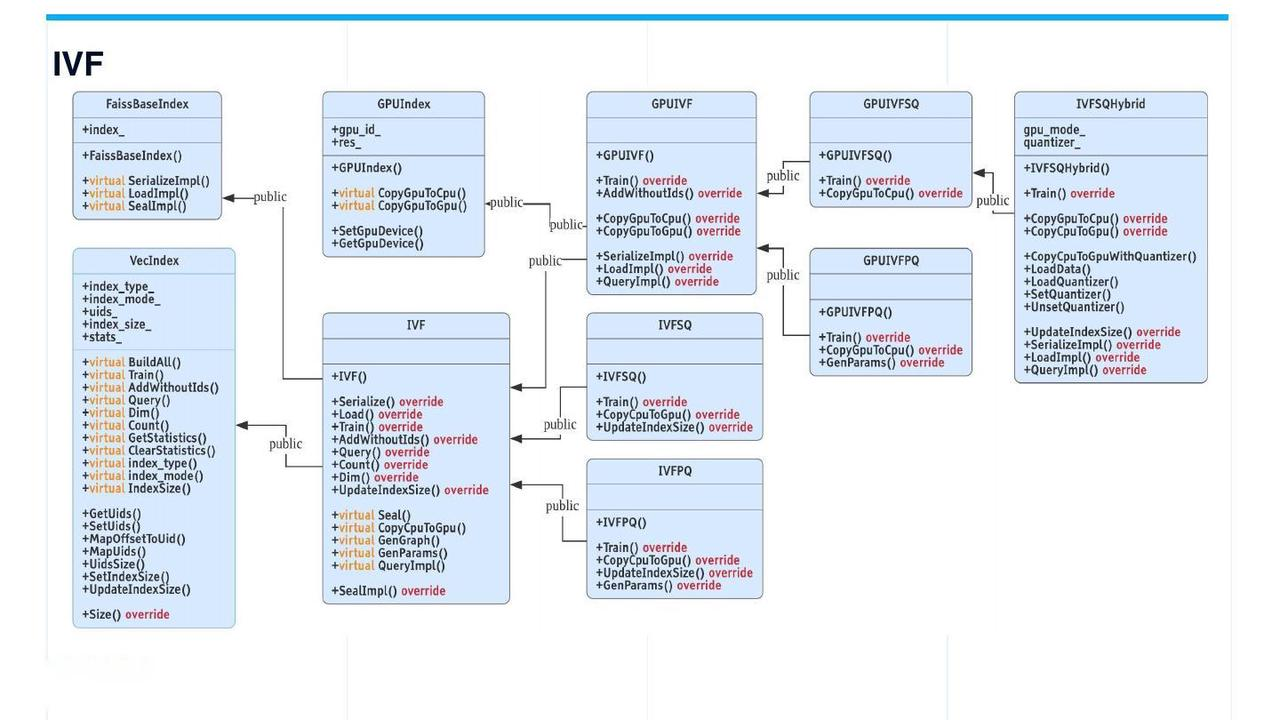
IVF(倒排文件)索引是最常用的索引。IVF类派生自VecIndex和FaissBaseIndex,并进一步扩展到IVFSQ和IVFPQ。GPUIVF源于GPUIndex和IVF。然后,GPUIVF进一步扩展到GPUIVFSQ和GPUIVFPQ。
IVFSQHybrid是一种自行开发的混合索引,通过GPU上的粗量化执行。在CPU上执行bucket中的搜索。通过利用GPU的计算能力,这种类型的索引可以减少CPU和GPU之间内存复制的发生。IVFSQHybrid具有与GPUIVFSQ相同的召回率,但具有更好的性能。
二进制索引的基类结构相对简单。BinaryIDMAP和BinaryIVF是从FaissBaseBinaryIndex和VecIndex派生的。
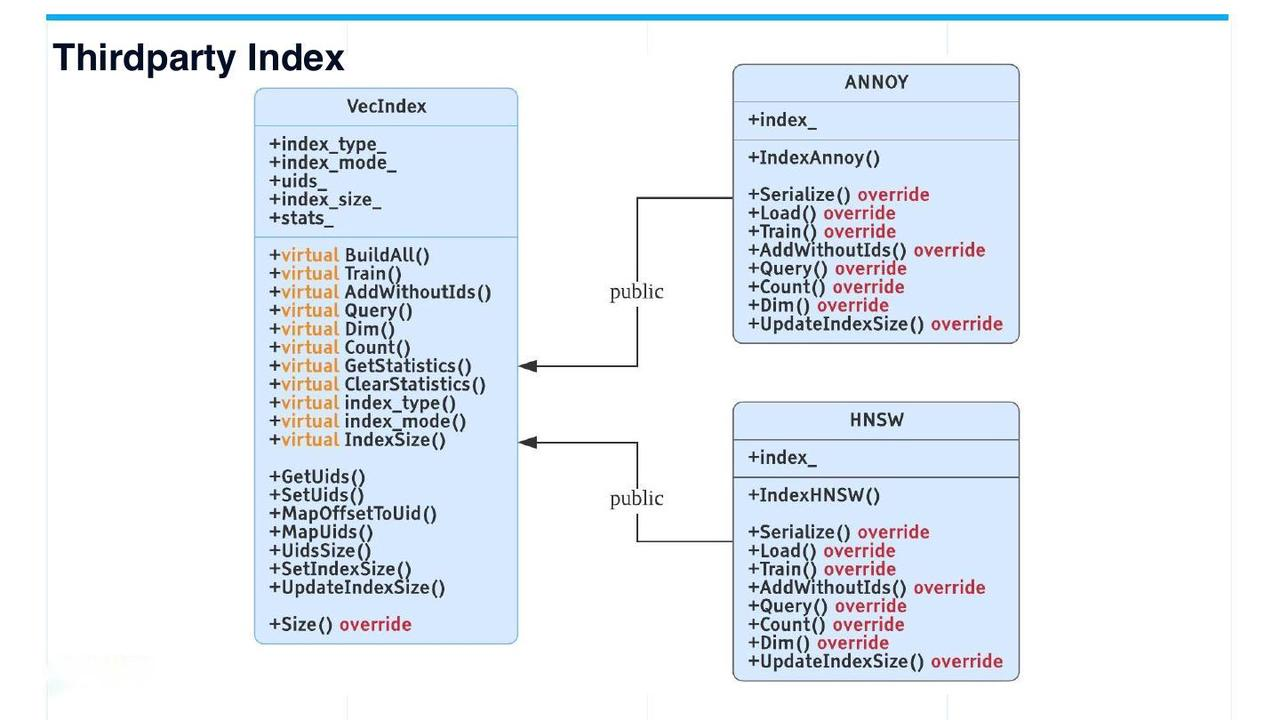
目前,除Faiss外,仅支持两种类型的第三方索引:基于树的索引HARRE和基于图的索引HNSW。这两个常用的第三方索引都是从VecIndex派生的。
向Knowhere添加索引
如果要在Knowhere中添加新索引,可以先参考现有索引:
-
要添加基于量化的索引,请参阅IVF_FLAT。
-
要添加基于图的索引,请参阅HNSW。
-
要添加基于树的索引,请参阅。
参考现有索引后,您可以按照以下步骤将新索引添加到Knowhere。
1.在IndexEnum中添加新索引的名称。数据类型为字符串。
2.在文件ConfAdapter.cpp中的新索引上添加数据验证检查。验证检查主要是验证数据训练和查询的参数。
3.为新索引创建新文件。新索引的基类应包括VecIndex和VecIndex的必要虚拟接口。
4.在VecIndexFactory::CreateVecIndex()中为新索引添加索引构建逻辑。
5.在unittest目录下添加单元测试。
原文标题:What Powers Similarity Search in Milvus Vector Database
原文作者:Yudong Cai
原文链接:https://dzone.com/articles/what-powers-similarity-search-in-milvus-vector-dat
