




目前比较火的链路监控工具的话,开源的有skyworking、cat、pinpoint。skyworking的话,之前也有使用过,但是没有太熟,cat的话上家公司就有使用,但是部署接入的话,还涉及到代码变动,不准备使用。
pinpoint链路监控工具的话,在几年前就一直在使用,那会儿版本还比较低,也是单机部署的,只有一个hbase作为存储,然后后面几年也一直在使用,比较熟悉,于是搭建新的链路监控平台,就准备使用pinpoint 了。
因为存储采用的是hbase,为了更稳定,后面不再重复工作,所以直接准备上集群版,所以需要搭建的有,zookeeper集群、habse集群、hadoop集群、collertor采集器集群高可用。
所需软件:
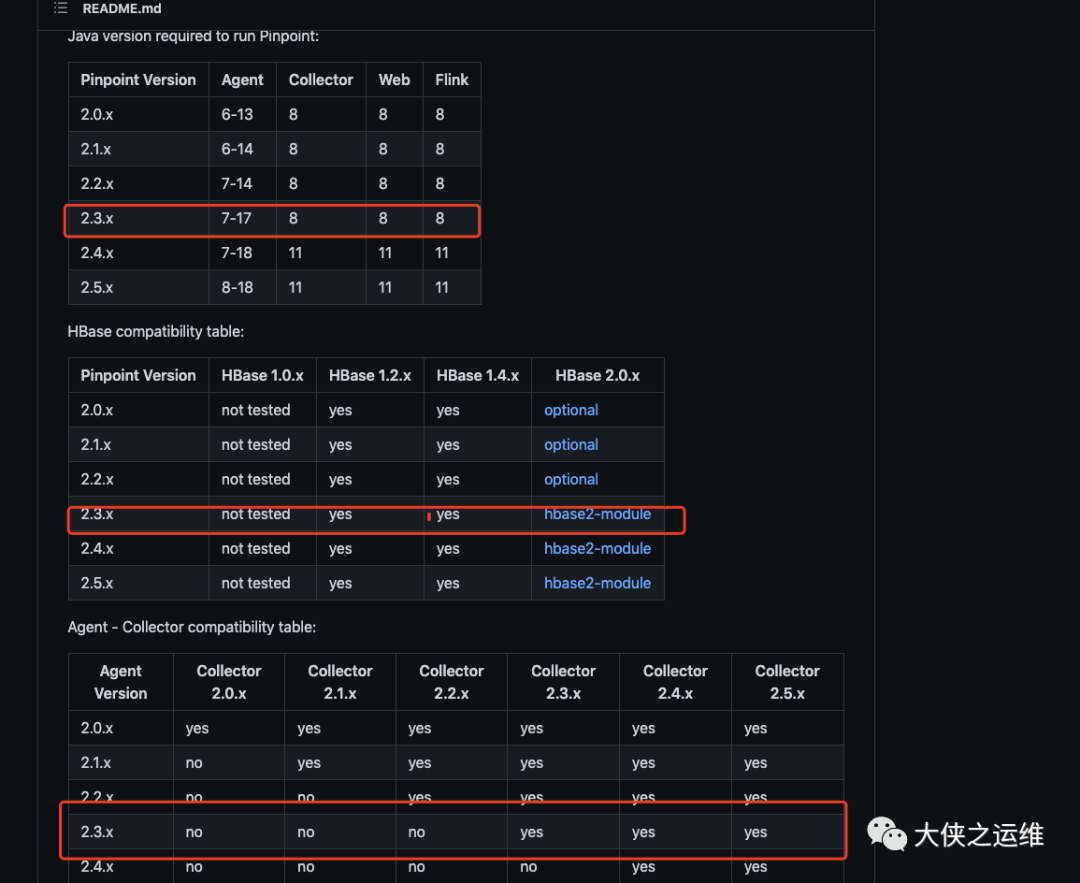
jdk 1.8 #目前pinpoint最新版2.4.0 需要更高版本jdk,这里部署2.3。0zookeeper 3.6.3hadoop 2.7.0hbase 1.4.0pinpoint collector&web 2.3.0nginx 1.21.1
关于版本匹配,可以到github中看下:
https://github.com/pinpoint-apm/pinpoint
官方介绍文档,可以参考:
https://pinpoint-apm.gitbook.io/pinpoint/
本文目录结构:
jdk环境配置集群之间免密配置&host配置zookeeper集群部署hadoop集群部署habse集群部署collertor集群启动web访问启动agent接入后续:监控告警接入
export JAVA_HOME=/opt/jdk-1.8/jdk1.8.0_261export PATH=$JAVA_HOME/bin:$PATHexport CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
192.168.ip1 master192.168.ip2 node1192.168.ip3 node2
tar -xvf zookeeper-3.6.3.tar.gz
#my.cnftickTime=2000initLimit=10syncLimit=5dataDir=/data/zookeeper/serverclientPort=2181dataLogDir=/data/zookeeper/logserver.0=master:2888:3888server.1=node1:2888:3888server.2=node2:2888:3888
#三台分别设置echo 0 > ./server/myid
#启动./bin/zkServer.sh start查看状态./bin/zkServer.sh status

#cat core-site.xml<configuration><property><name>fs.default.name</name> <!--NameNode 的URI--><value>hdfs://master:9000</value></property><property><name>hadoop.tmp.dir</name> <!--hadoop临时文件的存放目录--><value>/data/hadoop/dfs/tmp</value> <!--找个地方放就好了--></property><property><name>io.file.buffer.size</name><value>131072</value></property><property><name>hadoop.native.lib</name><value>true</value></property></configuration>
# cat hdfs-site.xml<configuration><property><name>dfs.namenode.secondary.http-address</name><value>master:9001</value></property><property><name>dfs.namenode.name.dir</name><!--namenode持久存储名字空间及事务日志的本地文件系统路径--><value>file:/data/hadoop/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><!--DataNode存放块数据的本地文件系统路径--><value>file:/data/hadoop/dfs/data</value></property><property><name>dfs.replication</name> <!--数据需要备份的数量,不能大于集群的机器数量,默认为3--><value>2</value></property><property><name>dfs.webhdfs.enabled</name> <!--设置为true,可以在浏览器中IP+port查看--><value>true</value></property></configuration>
#cat mapred-site.xml<configuration><property><name>mapreduce.framework.name</name> <!--mapreduce运用了yarn框架,设置name为yarn--><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name> <!--历史服务器,查看Mapreduce作业记录--><value>master:9003</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>master:9002</value></property></configuration>
# cat yarn-site.xml<configuration><property><name>yarn.nodemanager.aux-services</name><!--NodeManager上运行的附属服务,用于运行mapreduce--><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property><property><name>yarn.resourcemanager.address</name> <!--ResourceManager 对客户端暴露的地址--><value>master:9015</value></property><property><name>yarn.resourcemanager.scheduler.address</name><!--ResourceManager 对ApplicationMaster暴露的地址--><value>master:9011</value></property><property> <!--ResourceManager 对NodeManager暴露的地址--><name>yarn.resourcemanager.resource-tracker.address</name><value>master:9012</value></property><property><name>yarn.resourcemanager.admin.address</name><!--ResourceManager 对管理员暴露的地址--><value>master:9013</value></property><property><!--ResourceManager 对外web暴露的地址,可在浏览器查看--><name>yarn.resourcemanager.webapp.address</name><value>master:9014</value></property></configuration>
#cat hadoop-env.sh#这个我这边是ssh端口不是22,所修改了ssh端口export HADOOP_SSH_OPTS="-p 2222"
#cat slaves 填写两台node节点ip就好
上述配置三台同步
export HBASE_MANAGES_ZK=false
#配置中涉及ip,自己改<configuration><property><name>hbase.rootdir</name><value>hdfs://ip1:9000/hbase</value></property><property><name>hbase.master</name><value>ip1 </value></property><property><name>hbase.cluster.distributed</name><value>true</value></property><property><name>hbase.zookeeper.quorum</name><value> ip1,ip2,ip3</value></property><property><name>hbase.zookeeper.property.clientPort</name><value>2181</value></property><property><name>zookeeper.session.timeout</name><value>200000</value></property><property><name>dfs.support.append</name><value>true</value></property></configuration>


./hbase-1.4.0/bin/hbase shell ./hbase-create.hbase
#cat hbase.propertiespinpoint.zookeeper.address=master,node1,node2hbase.client.host=master,node1,node2hbase.client.port=2181
java -jar ../pinpoint-collector-boot-2.3.0.jar --spring.config.additional-location=./hbase.properties
java -jar ../pinpoint-web-boot-2.3.0.jar --spring.config.additional-location=./hbase.properties &
-javaagent:/opt/pinpoint-agent-2.3.0/pinpoint-bootstrap.jar -Dpinpoint.agentId=id -Dpinpoint.applicationName=x-service
后面计划对一些错误请求,慢请求做一些监控
同样通过企微机器人预警
文章转载自大侠之运维,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
