




介绍
在ShardingSphere-proxy 搭配 MogDB/openGauss 动态读写分离 中介绍了ssp + MogDB 实现了静态读写分离、动态读写分离和高可用,本文主要来整理一下如何实现分布式。
数据分片指按照某个维度将存放在单一数据库中的数据分散地存放至多个数据库或表中以达到提升性能瓶颈以及可用性的效果。 数据分片的有效手段是对关系型数据库进行分库和分表。分库和分表均可以有效的避免由数据量超过可承受阈值而产生的查询瓶颈。数据分片的拆分方式又分为垂直分片和水平分片。
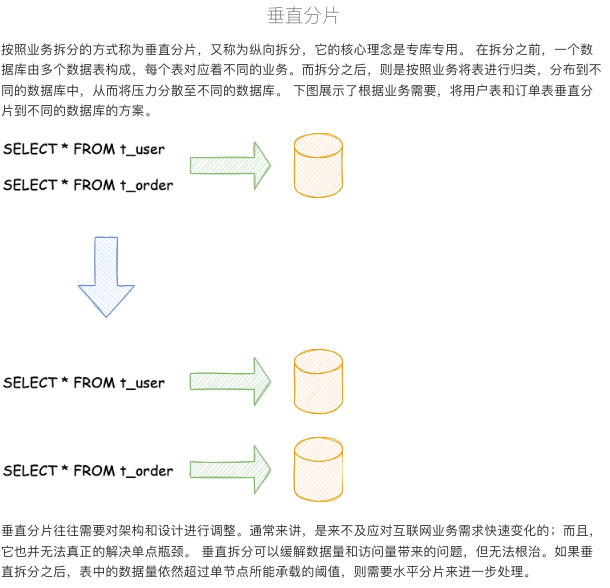
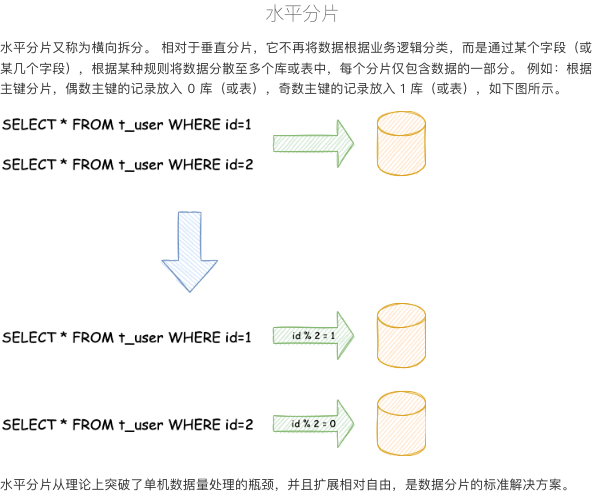
分片算法
- standard:标准分片算法,处理使用单一键作为分片键的 =、IN、BETWEEN AND、>、<、>=、<= 进行分片的场景
- comples: 复合分片算法,处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。
- hint: 处理使用 Hint 行分片的场景
分片策略
由分片键 + 分片算法组成,由于分片算法的独立性,将其独立抽离
数据节点分布
数据节点分布有 均匀分布 和 自定义分布 两种方式来表示逻辑表与真实表的映射关系。
- 均匀分布, 例如 ssp{0..2}.t_order_{0…2}
- 自定义分布方式, 例如ssp0.t_order_0,ssp0.t_order_1,ssp1.t_order_2
安装部署
环境准备
- must have Java JRE 8 or higher
- MogDB 安装部署完成,且运行状态正常
- zookeeper 集群部署完成,且运行状态正常
- ShardingSphere-proxy 安装部署参考
数据库准备
本次准备做3主节点的分布式数据库,需要用PTK部署3套集群,数据库准备操作,也需要在三个数据库集群操作
--创建用户及数据库
MogDB=# create user ssp password 'sspMogdb@123';
MogDB=# create database ssp owner ssp;
ssp=# grant create on schema public to ssp;
--配置pg_hba.conf,允许ssp所在服务器(122.221)以md5的加密方式访问数据库
$ gs_guc reload -I all -N all -h "host all all 192.168.122.221/32 md5"
配置文件
server.yaml与读写分离配置方式保持不变,修改config-sharding.yaml文件就好
databaseName: sharding_db
dataSources:
ssp0:
url: jdbc:postgresql://192.168.122.157:27000/ssp
username: ssp
password: sspMogdb@123
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
ssp1:
url: jdbc:postgresql://192.168.122.157:28000/ssp
username: ssp
password: sspMogdb@123
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
ssp2:
url: jdbc:postgresql://192.168.122.157:29000/ssp
username: ssp
password: sspMogdb@123
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
rules:
- !SHARDING
tables:
t_order:
actualDataNodes: ssp${0..2}.t_order_${0..2}
tableStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: t_order_inline
keyGenerateStrategy:
column: id
keyGeneratorName: snowflake
t_order_item:
actualDataNodes: ssp${0..2}.t_order_item_${0..2}
tableStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: t_order_item_inline
keyGenerateStrategy:
column: id
keyGeneratorName: snowflake
bindingTables:
- t_order,t_order_item
broadcastTables:
- t_broadcast
defaultDatabaseStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: database_inline
defaultTableStrategy:
none:
shardingAlgorithms:
database_inline:
type: INLINE
props:
algorithm-expression: ssp${id % 3}
t_order_inline:
type: INLINE
props:
algorithm-expression: t_order_${id % 3}
t_order_item_inline:
type: INLINE
props:
algorithm-expression: t_order_item_${id % 3}
keyGenerators:
snowflake:
type: SNOWFLAKE
scalingName: default_scaling
scaling:
default_scaling:
input:
workerThread: 40
batchSize: 1000
output:
workerThread: 40
batchSize: 1000
streamChannel:
type: MEMORY
props:
block-queue-size: 10000
completionDetector:
type: IDLE
props:
incremental-task-idle-seconds-threshold: 1800
dataConsistencyChecker:
type: DATA_MATCH
props:
chunk-size: 1000
启动登录
--启动
/opt/ssp/bin/start.sh
--查看启动日志
# tail -100f /opt/ssp/logs/stdout.log
OpenJDK 64-Bit Server VM warning: Setting LargePageSizeInBytes has no effect on this OS. Large page size is 2048K.
OpenJDK 64-Bit Server VM warning: Failed to reserve shared memory. (error = 12)
OpenJDK 64-Bit Server VM warning: Failed to reserve shared memory. (error = 12)
OpenJDK 64-Bit Server VM warning: Failed to reserve shared memory. (error = 12)
Thanks for using Atomikos! This installation is not registered yet.
REGISTER FOR FREE at http://www.atomikos.com/Main/RegisterYourDownload and receive:
- tips & advice
- working demos
- access to the full documentation
- special exclusive bonus offers not available to others
- everything you need to get the most out of using Atomikos!
[INFO ] 2022-07-19 00:00:57.558 [main] o.a.s.d.p.s.r.s.RuleAlteredContextManagerLifecycleListener - mode type is not Cluster, mode type='Memory', ignore
[INFO ] 2022-07-19 00:00:57.586 [main] o.a.s.p.v.ShardingSphereProxyVersion - Database name is `PostgreSQL`, version is `9.2.4`, database name is `sharding_db`
[INFO ] 2022-07-19 00:00:57.820 [main] o.a.s.p.frontend.ShardingSphereProxy - ShardingSphere-Proxy Memory mode started successfully
--登录
$ gsql -h 192.168.122.221 -p 3307 -Uroot -Wroot sharding_db -r
gsql ((MogDB 3.0.0 build 62408a0f) compiled at 2022-06-30 14:21:11 commit 0 last mr )
Non-SSL connection (SSL connection is recommended when requiring high-security)
Type "help" for help.
sharding_db=>
表
单表
指所有的分片数据源中仅唯一存在的表,适用于数据量不大且无需分片的表。
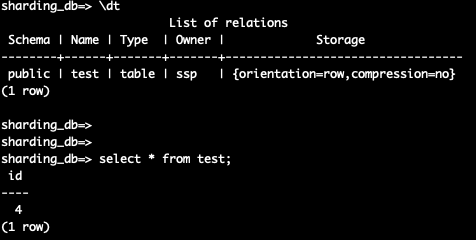
- 通过ssp创建单表,表将随机在某个数据源中创建
- 通过ssp执行 \dt 命令可能查不到单表,但是create会提示表已经存在,原因是后台真正执行的数据库可能没有这个表
- 如果不同数据源下同一个数据库的同一个schema下都有相同名字的单表,那ssp只会返回查询到的表
$ gsql -h 192.168.122.221 -p 3307 sharding_db -r -Uroot -W root
sharding_db=> create table test(id int);
sharding_db=> create table test1(id int);
sharding_db=> create table test2(id int);
sharding_db=> \dt
No relations found.
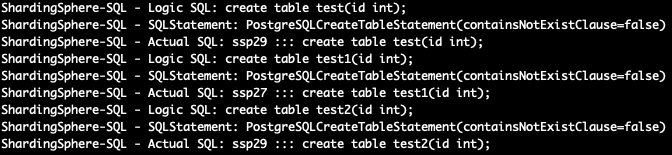
单表查询
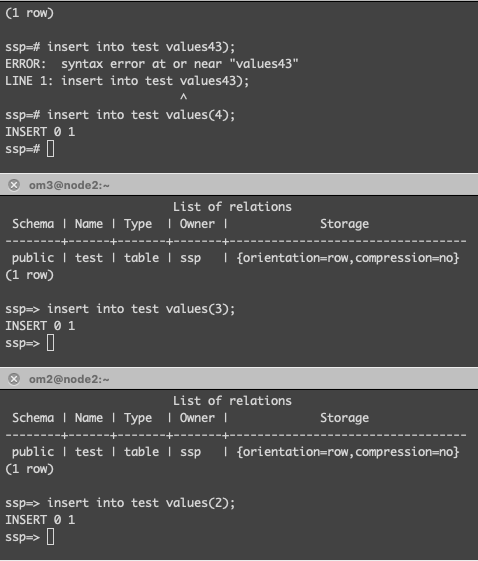
广播表
所有的分片数据源中都存在的表,表结构及其数据在每个数据库中均完全一致。
- 适用于数据量不大且需要与海量数据的表进行关联查询的场景。
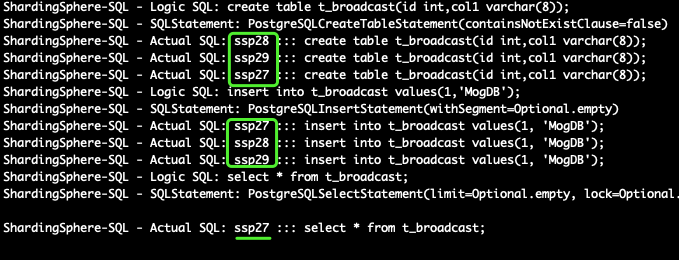
- 广播表需要提前在配置文件中配置好,否则会当单表创建。
- 查询会随机选一个分片数据源
sharding_db=> create table t_broadcast(id int,col1 varchar(8));
CREATE TABLE
sharding_db=> insert into t_broadcast values(1,'MogDB');
INSERT 0 1
sharding_db=> select * from t_broadcast;
id | col1
----+-------
1 | MogDB
分片表
分片表可以分为 逻辑表 和 真实表 两部分,逻辑表就是我们在ssp中创建的表时使用的表名,而真实表是在各个分片数据库真实存在的表
- 适用于数据量比较大的表
- 需要提前在配置文件中规划好分片策略
--创建表
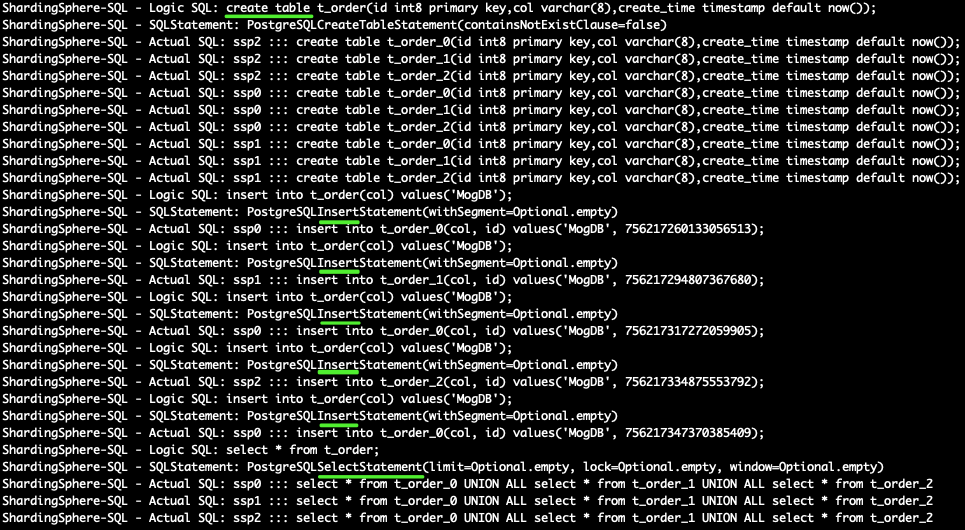
sharding_db=> create table t_order(id int8 primary key,col varchar(8),create_time timestamp default now());
CREATE TABLE
--插入数据
sharding_db=> insert into t_order(col) values('MogDB');
INSERT 0 1
sharding_db=> insert into t_order(col) values('MogDB');
INSERT 0 1
sharding_db=> insert into t_order(col) values('MogDB');
INSERT 0 1
sharding_db=> insert into t_order(col) values('MogDB');
INSERT 0 1
sharding_db=> insert into t_order(col) values('MogDB');
INSERT 0 1
--查询数据,select * 语句底层原理是同一个数据源下各个分片做union all
sharding_db=> select * from t_order;
id | col | create_time
--------------------+-------+----------------------------
756217260133056513 | MogDB | 2022-07-19 18:17:24.652767
756217317272059905 | MogDB | 2022-07-19 18:17:38.277903
756217347370385409 | MogDB | 2022-07-19 18:17:45.451977
756217294807367680 | MogDB | 2022-07-19 18:17:32.920422
756217334875553792 | MogDB | 2022-07-19 18:17:42.475368
(5 rows)
ssp日志信息
注意事项
--分片表必须要加主键约束,否则会有如下报错
ERROR: Insert statement does not support sharding table routing to multiple data nodes.
--主键字段要使用int8,否则会出现如下报错
ERROR: integer out of range
--数据分片编号应该从0开始,否则取模会有问题,例如如下报错
ERROR: Route table ssp20 does not exist, available actual table: [ssp27, ssp28, ssp29]
绑定表
当多个分片表进行关联查询时,会出现笛卡尔积的情况,这样对性能有极大的影响,为了避免笛卡尔积现象,将分片规则一致的一组分片表进行绑定,且必须使用分片字段进行关联,在配置文件中使用bindingTables指定绑定关系。
举例说明:
--sql语句
SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
--未绑定之前
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
--绑定之后
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
思考
- 有没有副本集,某个节点故障怎么办
- 高可用与分布式如何动态结合? 数据源配置vip ?
最后修改时间:2022-08-02 15:59:14
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
