




标题:WWW'22|SimGRACE:无需数据增广的图对比学习
“Paper title: SimGRACE: A Simple Framework for Graph Contrastive Learning without Data Augmentation
Paper link: https://arxiv.org/abs/2202.03104
Code: https://github.com/junxia97/simgrace
Publication Venue: WWW 2022
Institution: Westlake University
”
研究动机
图对比学习已经成为主流的图表示学习方法,其不仅能够充分挖掘图的结构和语义信息,还避免了对大量人工标注样本的依赖。对比学习需要对图进行数据增广,并拉近不同增广版本的表征推远不同样本的表征。然而,鉴于图数据的复杂性,在图增广的过程中很难保证增广前后语义信息的一致性(如分子图)。目前,在图数据上进行增广主要有三种方式:
需要为每个数据集手动选择增强,并进行反复试验。(GraphCL, NeurIPS 2020) 需要进行复杂的搜索过程实现自动搜索图增广。(JOAO, ICML 2021) 需要丰富的领域知识来作为指导。(MOCL, KDD 2021)
他们各自的缺点总结如下:
方法
SimGARCE
SimGRACE的整体框架如下图所示,包括3个主要组成部分,
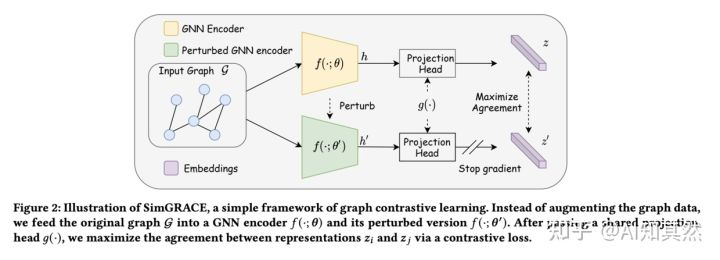
Encoder perturbation: 该部分主要是构造进行扰动的encoder。encoder有2个,, 分别是最终用来得到图表示的encoder和扰动encoder,其中,扰动encoder的参数利用如下图所示的方法得到,用来控制扰动程度,表示从正态分布中采样的扰动。 Projection head: 该部分主要是保证两个encoder的嵌入向量可以在同一空间可比。作者采用两层的MLP 进行project。 Contrastive loss: 该部分不用说了,对比学习常用损失。
定性分析
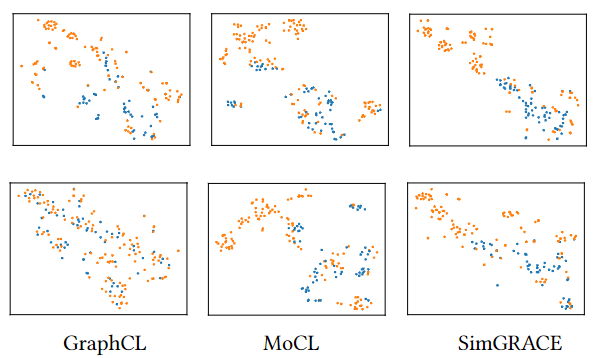 不像GraphCL, MoCL与SimGRACE可以保证增广前后样本语义不会发生很大变化。然而,MoCL需要化学域知识的引导并且无法用在社交图上。
不像GraphCL, MoCL与SimGRACE可以保证增广前后样本语义不会发生很大变化。然而,MoCL需要化学域知识的引导并且无法用在社交图上。
动态定量分析
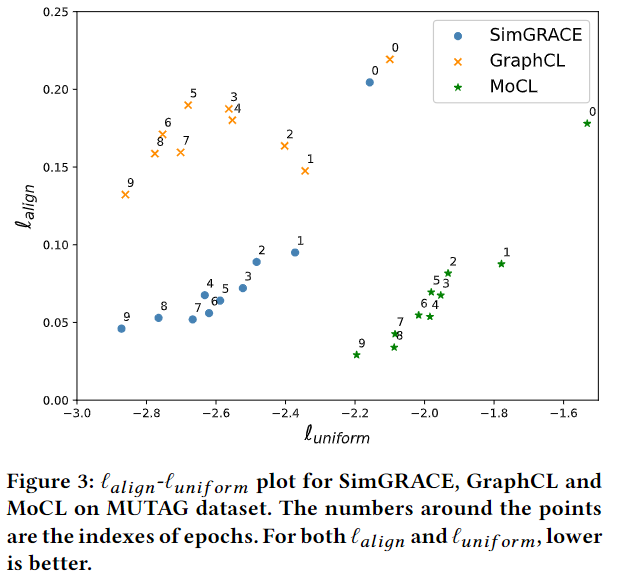 参考先前的工作,定义SimGRACE中表征质量的两种度量:
参考先前的工作,定义SimGRACE中表征质量的两种度量:
作者每个2个训练的epoch就绘制SimGRACE,GraphCL,MoCL的两种指标值(如上图所示)。从图上可以看出,所有方法都可以提高alignment和uniformity。但是,GraphCL 在alignment上的增益比 SimGRACE 和 MoCL 小,也就是说正样本对不能充分的相似,这是因为GraphCL的一些随机增广方法破坏了图的原始语义。相反,MoCL使用领域知识增强图数据,可以保留原始语义。另一方面,虽然MoCL利用领域知识得到比SimGRACE更好的alignment,但uniformity的收益却很小,因此最终效果不及SimGRACE。
AT-SimGRACE
针对现有对比学习方法只对随机扰动(攻击)具有鲁棒性,而对对抗扰动(攻击)的防范性较差的问题。作者引入「对抗样本」来联合训练模型,从训练(理论上)阶段提升对抗能力。标准的对抗训练目标函数如下图所示。
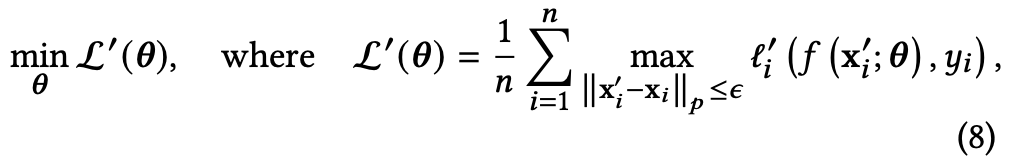
然而这存在2个问题,导致图对比学习无法采用标准的对抗训练方法。
对抗训练是有监督的(监督信号中的标签从哪里来?是用原始样本的标签生成的),而图对比学习没有标签。 每一个样本都需要寻找其对抗样本,计算量开销比较大。
因此,作者提出AT-SimGRACE,解决上述2个问题,
把监督损失,替换为对比损失,融入对抗训练。这样绕过了标签,只要计算正负样本的损失即可。 替换损失后,如何寻找对抗样本并减少计算量呢?作者引入可学习的扰动项,通过对抗的方式确定扰动值,完成扰动对抗样本的产生。同时,由于扰动来自于「稠密的」隐向量空间,相对于稀疏的原始输入空间来说,能够更简单快捷的搜索扰动项,效率更高。具体优化目标如下图所示。
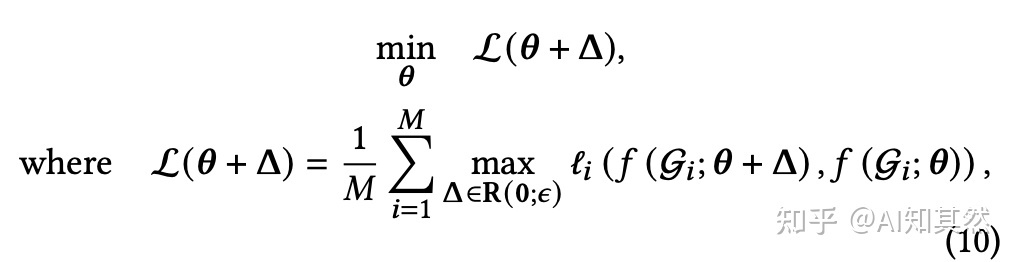
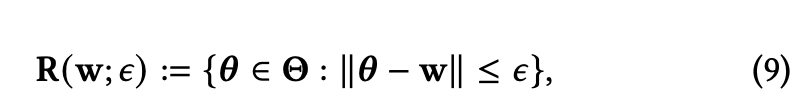
AT-SimGRACE的训练伪代码如下图所示。
 作者在原文也进行了AT-SimGRACE的鲁棒性证明, 具体可参考原文。
作者在原文也进行了AT-SimGRACE的鲁棒性证明, 具体可参考原文。
实验
作者从泛化性、迁移性、对抗鲁棒性和效率等方面进行了大量实验。具体设定可参考原文。
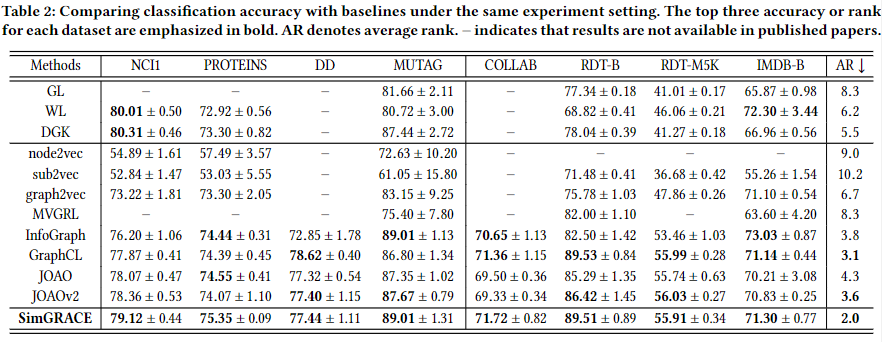
泛化性
非监督
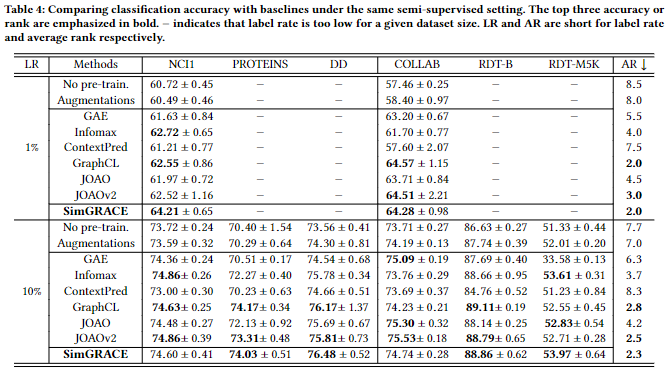
半监督
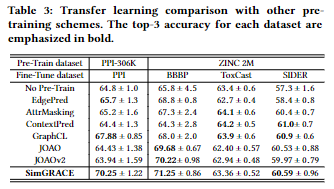
迁移学习
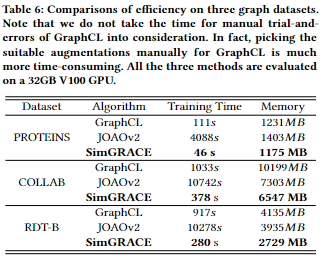
效率
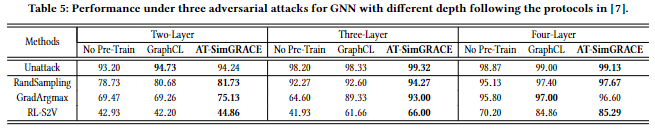
鲁棒性
总结
如前所述,SimGRACE扰动是在嵌入向量空间中进行的。因此,可以理解为更多的是在语义上进行调整,而先前的方法在原始空间中增广很容易破坏数据的语义。在语义空间的增广仍是图对比学习里面一个有潜力的研究方向。
