




论文:Recipe for a General, Powerful, Scalable Graph Transformer
作者:Ladislav Rampášek, Mikhail Galkin, Vijay Prakash Dwivedi, Anh Tuan Luu, Guy Wolf, Dominique Beaini
2021 年,Graph Transformer (GT) 因缓解了与普通消息传递 GNN 相关的许多问题而赢得了最近的分子特性预测挑战。在这里,作者尝试将众多新开发的 GT 模型组织到一个单一的 GraphGPS 框架中,以便为所有类型的 Graph ML 任务启用具有线性复杂度的通用、强大和可扩展的Graph Transformer。
借助 GraphGPS,作者设法将 Graph Transformers 扩展到更大的图,并在几个竞争性基准测试中获得 SOTA,例如锌为 0.07 MAE。值得注意的是位置和结构嵌入对于Graph Transformer是必要的,分别编码节点的“where”和其邻域的“how”。
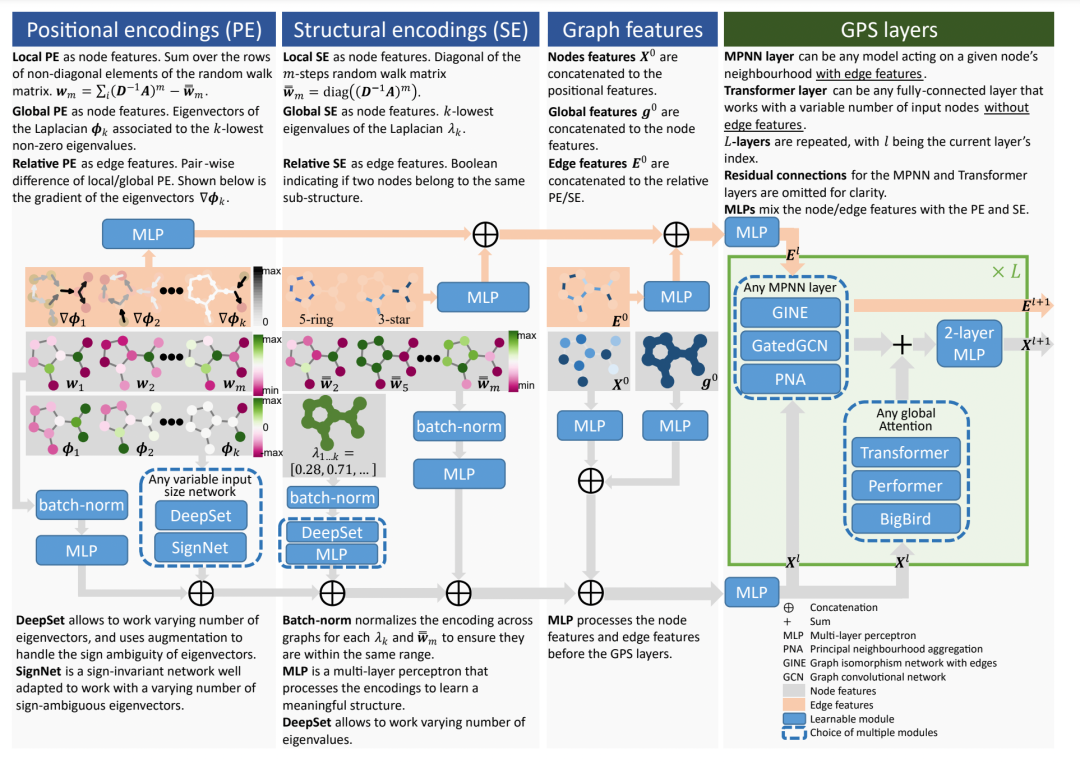
它们甚至可以被证明比 MPNN 更强大!作者通过更加清晰的定义将它们组织成局部、全局和相对类型。

本文发现最好将 MPNN 和 Transformer 层组合在一起:有助于过度平滑,并允许即插即用线性全局注意力,例如 Performer。事实上,与典型分子相比,线性注意力使图转换器能够扩展到更大的图 - 它可以轻松地在具有 5K 节点的图上工作,而无需任何特殊的批处理!
将这 3 个要素放在一起:位置/结构编码、MPNN 的选择和 Transformer 层组合成一层,为 GraphGPS 提供了蓝图:通用、强大、可扩展的图形转换器。
🚀 比以前的图形转换器快 400%;
📈 借助线性注意力模型,可以扩展到多达 10,000 个节点的批量图;
🛠 GraphGPS 库允许将任何 MPNN 与任何 Transformer 以及任何位置/结构编码结合起来。
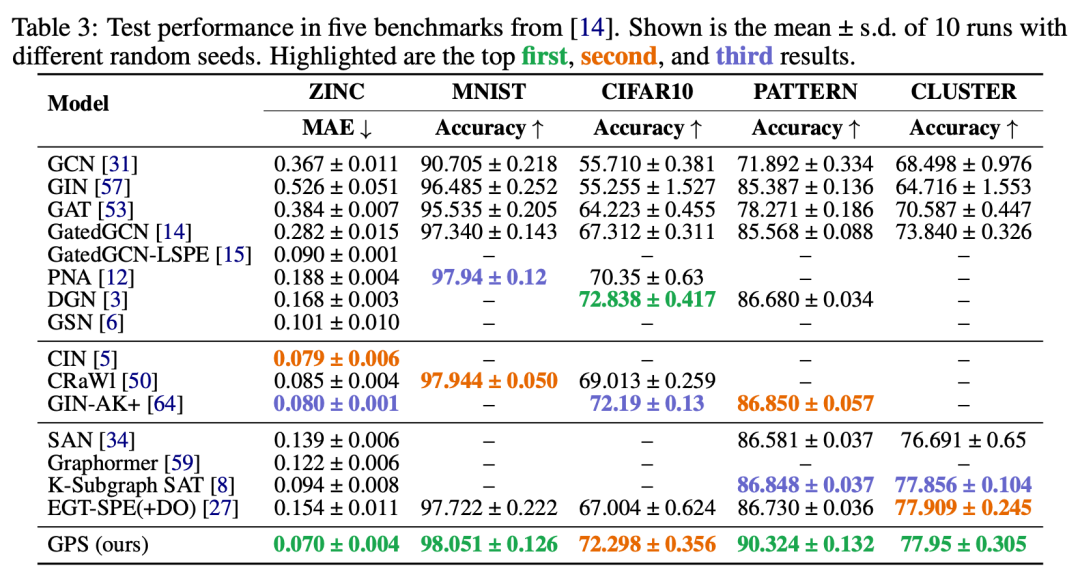
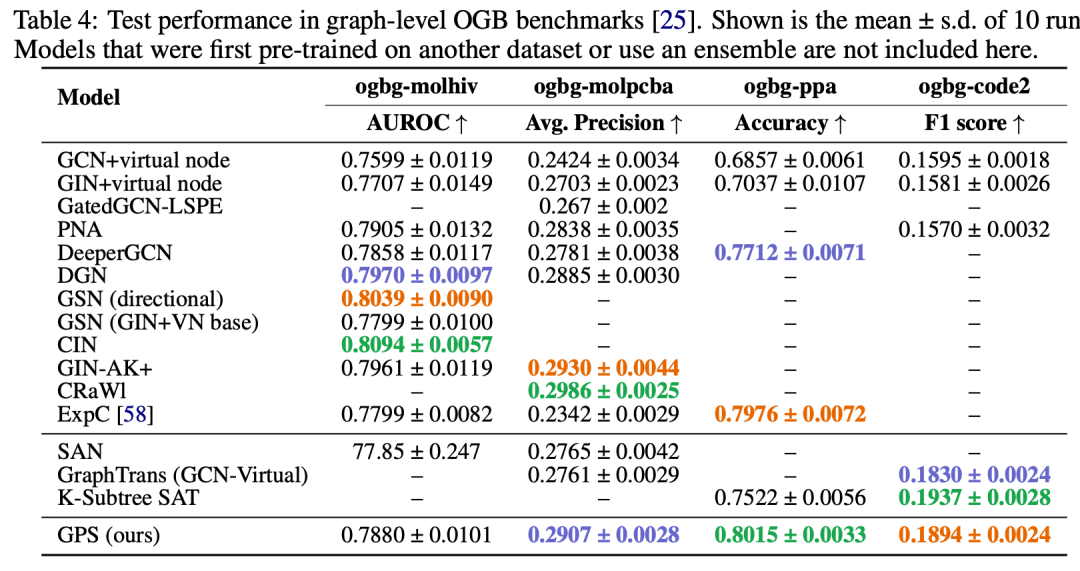
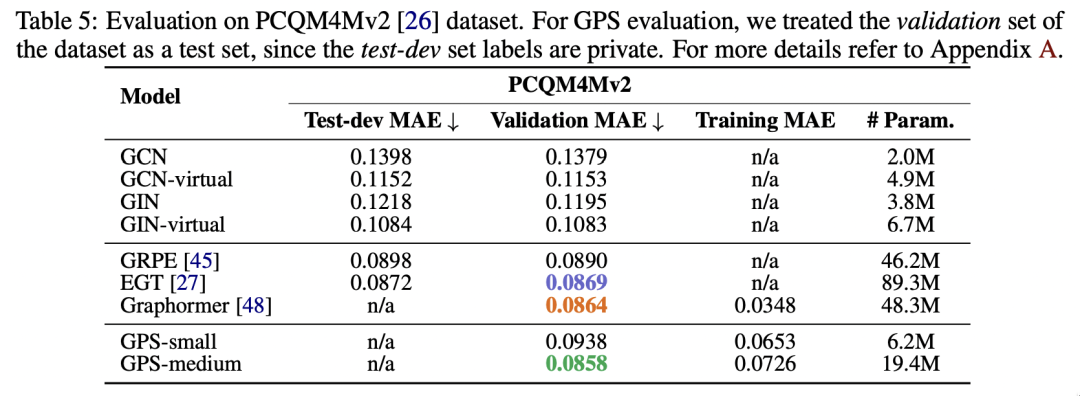
更多详细信息:
- 深入探讨 GraphGPS 的中型博客文章:https://mgalkin.medium.com/graphgps-navigating-graph-transformers-c2cc223a051c
- arxiv 预印本:https://arxiv.org/abs/2205.12454
- Github 仓库:https://github.com/rampasek/GraphGPS
