




编辑:小舟
AlphaFold2 是 2021 年 AI for Science 领域最耀眼的一颗星。现在,有人在 PyTorch 中复现了它,并已在 GitHub 上开源。这一复现在性能上媲美原版 AlphaFold2,且在算力、存储方面的要求对于大众来说更加友好。
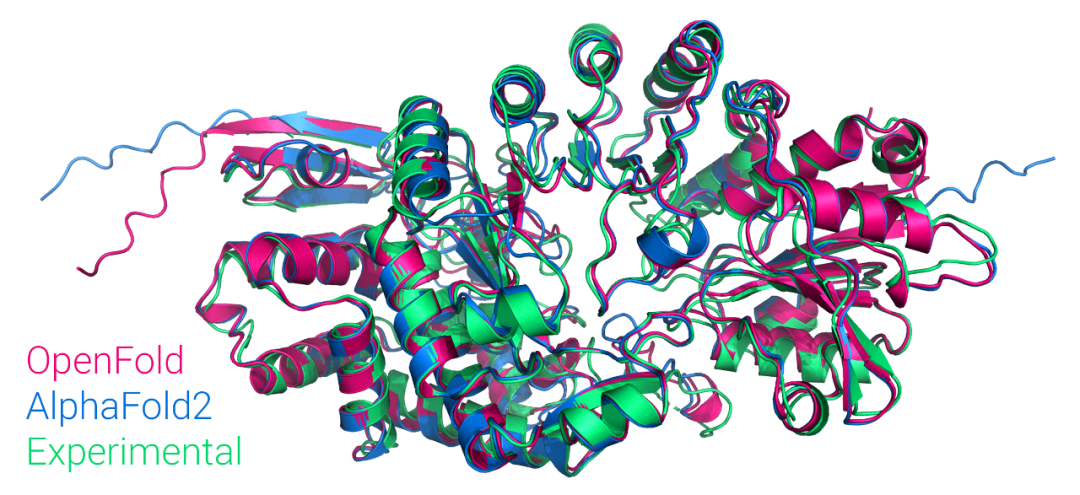


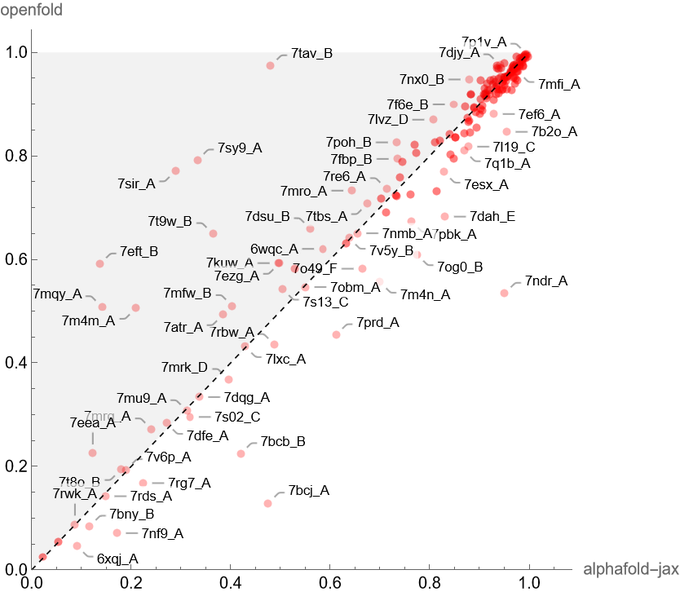
短序列推理:加快了在 GPU 上推理少于 1500 个氨基酸残基的链的速度; 长序列推理:通过该研究实现的低记忆注意力(low-memory attention)对极长链进行推理,OpenFold 可以在单个 A100 上预测 超过 4000 个残基的序列结构,借助 CPU offload 甚至可以预测更长的序列; 内存高效在训练和推理期间,在 FastFold 内核基础上修改的自定义 CUDA 注意力内核,使用的 GPU 内存分别比等效的 FastFold 和现有的 PyTorch 实现少 4 倍和 5 倍; 高效对齐脚本:该团队使用原始 AlphaFold HHblits/JackHMMER pipeline 或带有 MMseqs2 的 ColabFold,已经生成了数百万个对齐。
scripts/install_third_party_dependencies.sh
source scripts/activate_conda_env.sh
source scripts/deactivate_conda_env.sh
python3 setup.py install
# scripts/install_hh_suite.sh
bash scripts/download_data.sh data/
python3 run_pretrained_openfold.py \
fasta_dir \
data/pdb_mmcif/mmcif_files/ \
--uniref90_database_path data/uniref90/uniref90.fasta \
--mgnify_database_path data/mgnify/mgy_clusters_2018_12.fa \
--pdb70_database_path data/pdb70/pdb70 \
--uniclust30_database_path data/uniclust30/uniclust30_2018_08/uniclust30_2018_08 \
--output_dir ./ \
--bfd_database_path data/bfd/bfd_metaclust_clu_complete_id30_c90_final_seq.sorted_opt \
--model_device "cuda:0" \
--jackhmmer_binary_path lib/conda/envs/openfold_venv/bin/jackhmmer \
--hhblits_binary_path lib/conda/envs/openfold_venv/bin/hhblits \
--hhsearch_binary_path lib/conda/envs/openfold_venv/bin/hhsearch \
--kalign_binary_path lib/conda/envs/openfold_venv/bin/kalign
--config_preset "model_1_ptm"
--openfold_checkpoint_path openfold/resources/openfold_params/finetuning_2_ptm.pt
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
文章转载自深度学习与图网络,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
