




论文标题:Towards Unsupervised Deep Graph Structure Learning
收录会议:WWW 2022
论文链接:https://arxiv.org/pdf/2201.06367.pdf
代码链接:https://github.com/GRAND-Lab/SUBLIME

1. 引言
近年来,图神经网络(Graph Neural Network, GNN)广泛应用于各种图数据相关的任务当中。然而,图神经网络的学习十分依赖于输入的图结构数据(即图数据中各节点的关联),大大影响了其鲁棒性和普适性。一方面,现实系统中获取的图结构数据难免包含噪声信息,会存在多余边或缺失边的问题;在学习过程中,GNN很容易受到这些噪声数据的影响,从而导致其性能下降 [1]。另一方面,对图结构的依赖也使得GNN无法应用于没有显式结构的非结构数据学习,尽管这些数据中可能存在隐性的结构信息 [2]。这种对输入结构的依赖,使得GNN难以应用于广泛存在于现实世界的非结构数据当中。
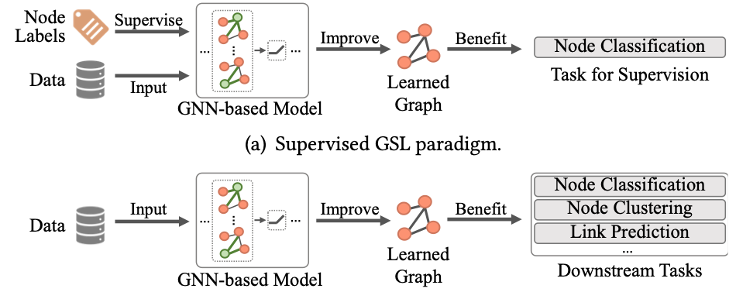
为了解决上述问题,现有方法[1,3,4,5]对图结构学习(Graph Structure Learning, GSL)技术进行研究,该技术旨在利用GNN对输入图结构本身进行学习和优化。目前的图结构学习主要遵循有监督范式,即:利用节点分类这一下游任务的标签信息,对图结构和GNN进行协同优化。这种范式虽被证明有效,却存在着一些局限性:1)对标签信息的依赖。有监督学习意味着需要标签的参与,但标签数据的获取通常需要较高成本,这使得GSL无法应用于更广泛的无标签数据中;2)学习到的边分布存在偏差。因为现有GSL方法通常基于半监督节点分类任务进行学习,其中只有部分节点的标签可知。相比无标签节点,这些有标签节点之间的连接通常能接受到更多的监督,从而造成学到的边分布存在不均匀和偏差;3)下游任务的局限性。现有方法的结构学习依赖于节点分类任务提供的监督信号,因此学到的结构也仅适用于这一下游任务,而可能无法应用于其他下游任务。
针对上述局限性,本文提出了一种新的学习范式——无监督图结构学习,即不依靠任何额外的标签信息,仅根据输入数据本身对图结构进行学习或改进。针对新的学习范式,本文提出了一种基于结构自引导的自监督对比学习方法(Structure Bootstrapping Contrastive Learning Framework, SUBLIME)。该方法采用对比学习技术,从原数据本身中获取监督信号来引导结构学习,并同时利用学到的结构信息对监督信息进行更新。本文开展了大量的实验证明了方法的有效性。
2. 问题定义
本文首先对无监督图结构学习问题进行定义。具体地,针对两种输入数据的情况,我们定义了两种无监督图结构学习问题,即“结构推理”和“结构改进”。其中,结构推理的目标是从非结构数据(仅包含特征矩阵)中学习出潜在的图结构,而结构改进的目标则是从含噪声的图结构数据(包含包含特征矩阵和邻接矩阵)中对原有的图结构进行改进。具体地,我们将学习到的图结构建模为一个优化后的邻接矩阵,该矩阵能够更好的揭示节点之间的真实连接关系,并可被广泛应用于各种下游任务中。


3. 方法
本文所提出的针对无监督图结构学习任务的方法SUBLIME主要由两个部件组成:图结构学习模块和对比学习模块。方法的框架图如下图所示。在图结构学习模块中,我们首先通过图学习器(Graph Learner)来对学到的图结构进行建模,然后通过后处理器(Post-Processor)对建模的图结构进行规范化。在对比学习模块中,我们分别定义了学习者视角(Learner View)和参考视角(Anchor View)。具体地,前者由学习到的图结构构成,后者则从原始数据中初始化而来。对比学习模块通过最大化两个视角之间的互信息,为图结构的学习提供了监督信号。此外,我们设计了一种结构自引导机制,利用从学习者视角中学到的信息对参考视角进行优化。下面将分别对上述的组件进行详细介绍。
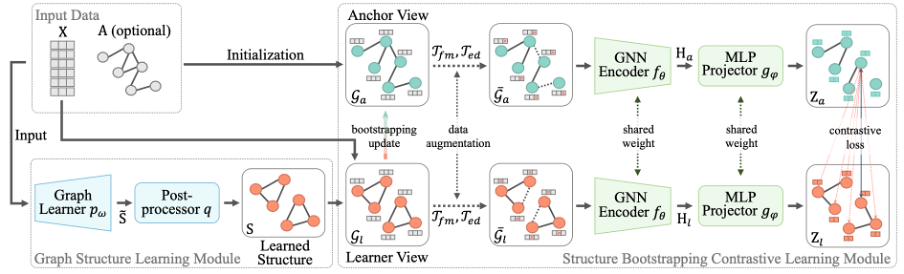
图学习器
为了适应不同输入数据的需要,本文设计了4种图学习器来建模图结构,包括一种全图参数化学习器(FGP Learner),和三种基于度量学习的学习器(Metric Learning-based Learners)。
在FGP学习器中,邻接矩阵的每个元素都用一个可学习的参数来建模,并由一个激活函数来保证训练的稳定性:
而基于度量学习的学习器中,首先会由一个基于神经网络的嵌入函数来得到节点嵌入,然后通过无参数的度量函数(比如余弦相似度)来得到邻接矩阵中的值:
通过定义不同的嵌入函数 ,我们可以得到三种不同的学习器:1)注意力学习器(Attentive Learner):采用注意力机制来生成的节点嵌入;2)多层感知机学习器(MLP Learner):采用多层堆叠的MLP层来计算节点嵌入;3)图神经网络学习器(GNN Learner):采用GNN进行节点嵌入的编码。
根据输入数据的不同特性,我们为它们选择不同的学习器,从而更好地建模图结构。
后处理器
经由图学习器得到的邻接矩阵通常比较粗糙,无法具备真实图结构的许多特性。因此,我们使用后处理对这个邻接矩阵进一步优化,从而产生一个精炼的图邻接矩阵。后处理器中的步骤主要分为4步:稀疏化(基于kNN),对称化(基于矩阵转置求平均),非负化(基于ReLU激活函数),以及归一化(基于对称归一化处理)。通过一系列后处理步骤,我们最终得到一个稀疏、非负、对称且正归一邻接矩阵。
多视角图对比学习
当对学习到的图结构(邻接矩阵)进行建模后,我们采用多视角对比学习的方式,通过从原数据中获取监督信号来指导图结构的优化。基于学到的邻接矩阵,我们将其与特征矩阵X进行结合,得到学习者视角(Learner View),记为。我们利用原始数据对参考视角(Anchor View)进行初始化,该视角为图结构的学习提供指引。具体地,若原数据带有图结构,我们会将该视角初始化为原始特征矩阵和邻接矩阵:;若原数据不含图结构,我们将其中的邻接矩阵初始化为单位矩阵:。
经过视角构建后,我们采用两种数据增广方式(随机遮掩特征(Feature Masking)和随机丢弃连接(Edge Dropping))对两个视角的数据进行增广。通过增大对比学习任务的难度,使模型能够探索到更高质量的图结构。
下一步,我们采用节点级的对比学习模型来最大化两个视角的互信息。具体地,增广后两个视角图首先经由两层GCN的编码,得到每个节点的表征;然后,经过由两层MLP网络构成的投影网络,得到两个视角对应的投影矩阵;最后,我们采用NT-Xent损失函数来最大化两个投影矩阵中对应节点的相似度,从而最大化两个视角的互信息。
结构自引导机制
通过固定的参考邻接矩阵(定义为或者)的指引,我们已经可以采用该模型进行结构学习。然而,这样的固定参考存在以下不足:1)原结构中包含的噪声边会对学到的图结构产生误导;2)固定的参考邻接矩阵包含的信息有限,很难提供持续的指引;3)在学习过程中,容易对固定的结构产生过拟合。
在自引导(Bootstrapping)的算法的启发下,我们设计了一种结构自引导机制(Structure Bootstrapping Mechanism)对参考邻接矩阵进行更新,从而提供可靠、持续、有效的结构学习指引。具体地,我们基于slow-moving的思想,利用学到的邻接矩阵,间歇地对参考邻接矩阵进行更新:
其中为延迟率,是模型中的超参数。通过定义较大的延迟率(),可以将结构自引导机制对参考邻接矩阵的更新幅度控制到比较小的范围,从而实现更稳定的模型训练。
4. 实验
实验设置
本文在8个数据集上展开实验,包括4个图结构数据集(Cora、CiteSeer、PubMed、ogbn-arxiv)以及4个非结构数据集(Wine、Cancer、Digits、20news)。我们在两个下游任务(节点分类和节点聚类)上评估学习结构的质量,并和一系列先进的方法进行对比。
性能对比
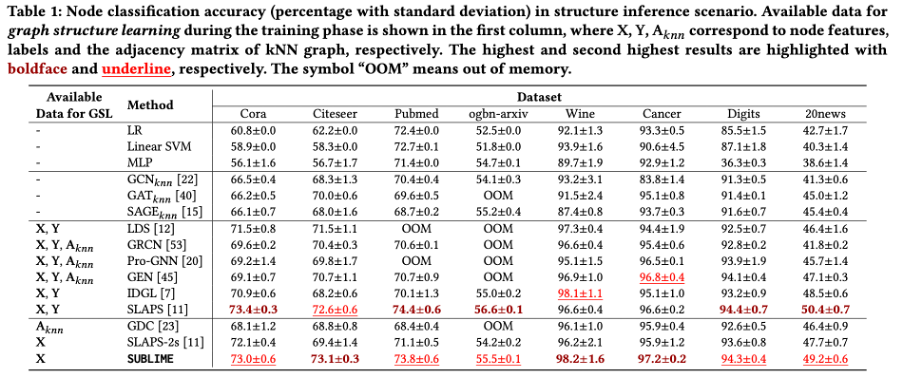
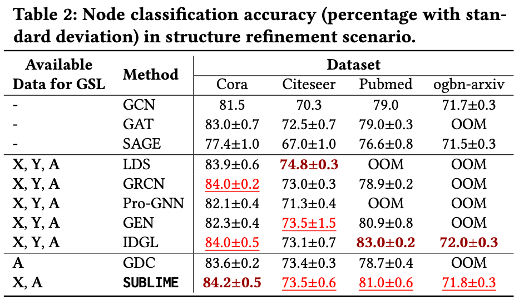
我们在三个场景进行对比:结构推理下的节点分类(表1),结构改进下的节点分类(表2),以及结构改进下的节点聚类(表3)。从实验结果可以看出,本文提出的方法在几乎所有场景和数据集中都能取得最优或次优的性能,说明了该方法能够学习到高质量且普适的图结构。
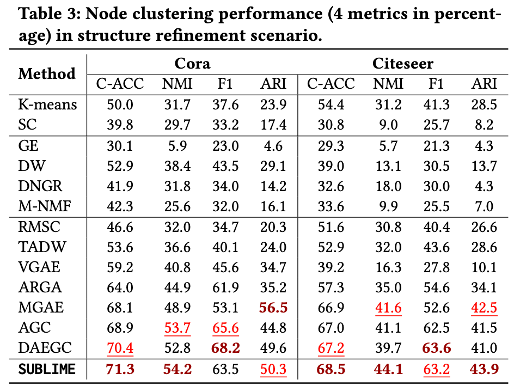
消融实验
通过改变超参数的值,我们对结构自引导机制开展进一步研究。实验结果可以看出,当时,SUBLIME在三个数据集上都具有最佳的性能,说明适中的更新强度能够更好地更新参考视角。通过进一步分析准确率和损失函数的变化可以看出,当时,此时结构自引导机制失效,在训练过程中会出现过拟合的情况,导致性能下降。当,此时会高强度地更新参考视角,导致训练过程非常不稳定,影响最终性能。
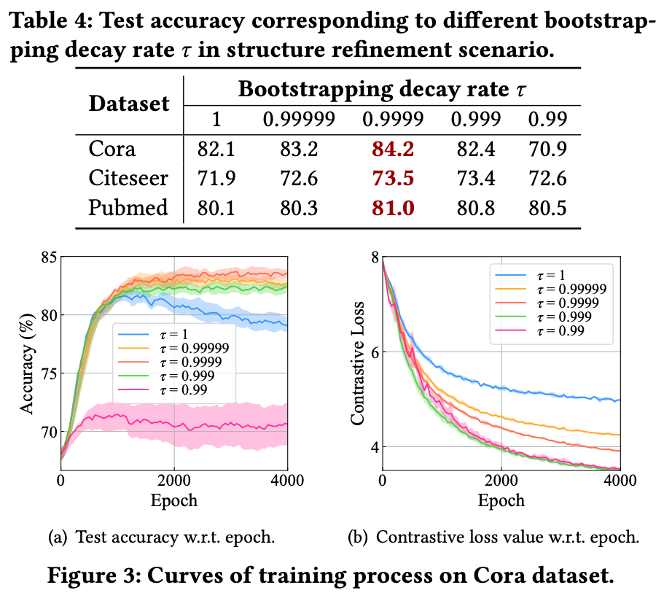
参数实验
本实验研究了两个超参数对性能的影响,包括随机遮掩特征的比率,以及kNN稀疏化中k的取值。从下图的实验结果可以看出,适中的超参数取值能带来最佳的性能,而过大/过小的取值都会导致模型性能的下降。
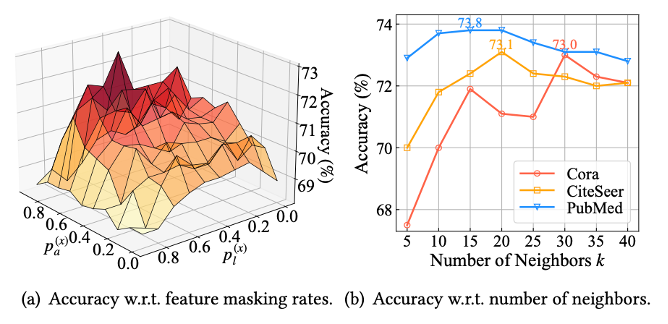
鲁棒性分析
为了研究SUBLIME在含噪声图结构下的性能,我们随机地增加或删除图结构中的边,并观测该方法在不同比率扰动下的性能。由下图可以看出,相比有监督的结构学习方法Pro-GNN [1],SUBLIME在两个场景下都能取得更好或相当的性能。尤其在大量边都被删除的情况下,SUBLIME仍然能学习到高质量的图结构,远超其他方法的性能。
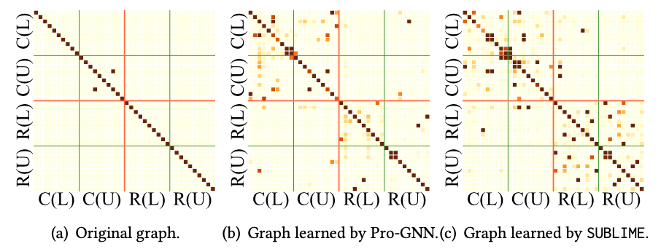
可视化
为了研究SUBLIME究竟学到了怎样的图结构,我们对学到的部分图结构进行可视化。我们考虑了两个类别(C和R)的节点,分别在训练集(L)和测试集(U)中选择了10个节点进行可视化。从下图可以看出,SUBLIME可以学习到大量同类节点之间的连接。同时,相比有监督方法Pro-GNN [1],我们的方法能够均匀地学习到每个节点之间潜在的连接,而不会出现边分布偏差的情况。
5. 总结
本文率先提出了无监督图结构学习的范式,旨在不依赖标签信息的条件下,从数据本身中学习更普适、更高质量的图结构。为了解决无监督图结构学习问题,本文提出了一种基于结构自引导的自监督对比学习方法SUBLIME,通过最大化两个视角的互信息的方式对结构进行建模、学习和优化。实验证明,相比有监督方法,我们的方法能够学习到更高质量的图结构。我们的方法有望应用于各种实际应用中,包括但不限于生物信息学研究,脑电波分析,交通流量预测以及计算机视觉等领域。
参考文献
[1] Jin, Wei, et al. "Graph structure learning for robust graph neural networks." Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020.
[2] Wu, Zonghan, et al. "Connecting the dots: Multivariate time series forecasting with graph neural networks." Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020.
[3] Franceschi, Luca, et al. "Learning discrete structures for graph neural networks." International conference on machine learning. PMLR, 2019.
[4] Chen, Yu, Lingfei Wu, and Mohammed Zaki. "Iterative deep graph learning for graph neural networks: Better and robust node embeddings." Advances in Neural Information Processing Systems 33 (2020): 19314-19326.
[5] Fatemi, Bahare, Layla El Asri, and Seyed Mehran Kazemi. "SLAPS: Self-Supervision Improves Structure Learning for Graph Neural Networks." Advances in Neural Information Processing Systems 34 (2021).
