




本文主要讲解RDD的宽依赖与窄依赖,stage的划分如果遇见shuffle就会是一个分界点,回溯的方式进行stage划分。为什么叫内存计算?
01
—
窄依赖
窄依赖指:每个父RDD的一个Partition最多被RDD的一个Partition所使用。如:map,filter、union等都会产生窄依赖
02
—
宽依赖
宽依赖指:一个父RDD的partition会被多个RDD的partition所使用,例如groupByKey、reduceBykey、sortByKey等产生宽依赖
03
—
特别说明
如果说join操作使用每个partition仅仅和已知的partition进行join,这次join操作就是窄依赖,其他情况的join操作就是宽依赖
解释:因为是特定的partition数量依赖关系,所以就是窄依赖,得出一个推理,窄依赖不仅包含一对一的窄依赖,还包含一对固定个数的窄依赖(也就是说对父RDD个数依赖的Partition的数量不会随着RDD数据量的改变而改变)
04
—
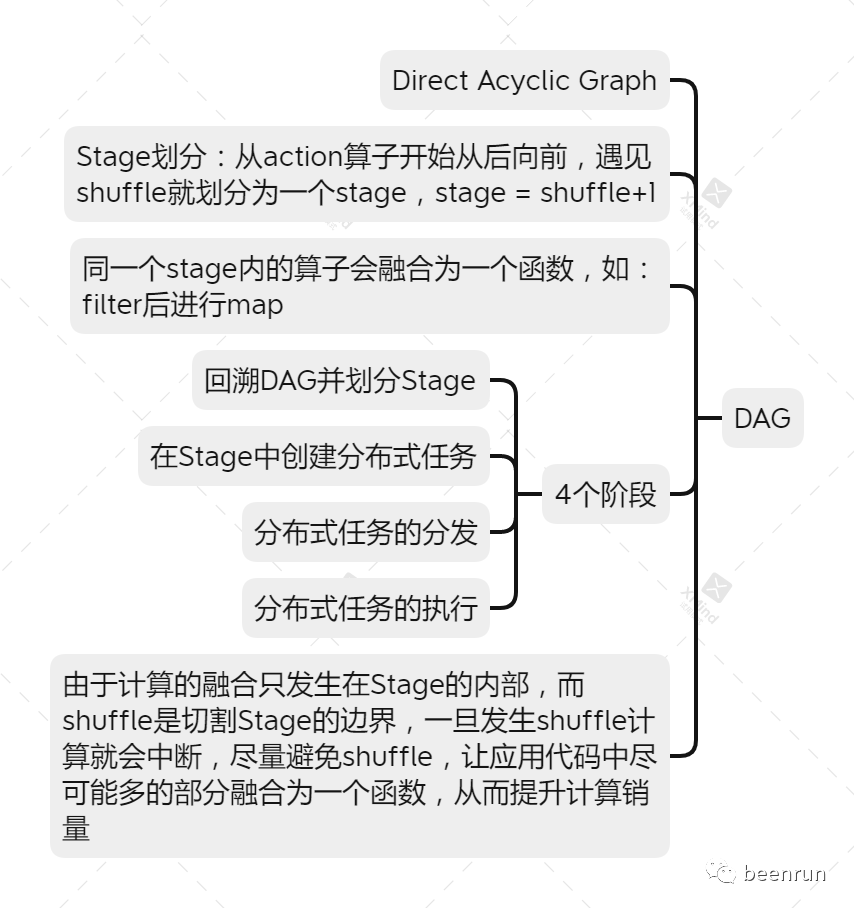
stage的划分
从后向前推理,遇见宽依赖就断开,遇到窄依赖就把RDD加入到当前的stage
每个stage里面的task数量是有该stage最后一个RDD的Partition的数量决定的,最后一个算子
最后一个stage里面的任务的类型是ResultTask,前面其它所有的stage里面的任务类型多是ShuffleMapTask
注意:Hadoop中的MapReduce操作中的Mapper和Reducer在spark中基本等量的算子是:map和reducerByKey
05
—
spark的内存计算理解
spark允许开发者,将分布式数据集缓存到计算节点的内存中,从而实现高效的数据访问
Stage内的流水线式计算模式
文章转载自beenrun,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
