




在我的日常工作中,我与许多将他们的数据迁移到 Postgres 的客户一起工作。我与从同源 (PostgreSQL) 以及异构数据库源(如 Oracle 和 Redshift)迁移的客户合作。人们为什么选择 Postgres?由于 PostgreSQL 的丰富性以及存储过程、JSONB、用于地理空间工作负载的 PostGIS 等功能,以及许多有用的 Postgres 扩展,包括我个人最喜欢的:Citus。
我帮助人们进行的大部分迁移是同质的 Postgres 到 Postgres 数据到云的迁移。由于 Azure Database for PostgreSQL 运行开源 Postgres,因此在许多情况下,应用程序迁移可以直接进行,不需要大量工作。大部分工作通常用于决定和实施正确的策略来执行数据迁移。对于那些在 Postgres 迁移过程中无法承受任何停机时间的人,当然有数据迁移服务可以提供帮助。但是,如果您可以在特定的维护窗口(例如周末、晚上等)期间为迁移提供一些停机时间,那么可以使用简单的 Postgres 实用程序,例如 pg_dump 和 pg_restore。
在这篇文章中,让我们讨论一下在使用 pg_dump 和 pg_restore 进行 Postgres 数据库迁移时要考虑的权衡 - 以及如何优化迁移以提高速度。让我们也探索一下需要迁移非常大的 Postgres 表的场景。对于大型表,使用 pg_dump 和 pg_restore 迁移数据库可能不是最佳方法。好消息是我们将介绍一个用于在 Postgres 中迁移大型数据库表的漂亮 Python 工具。使用此工具,我们观察到大型 Postgres 表(~1.4TB)的迁移在 7 小时内完成。 45 分钟与 pg_dump/pg_restore 超过 1 天。

使用 pg_dump 和 pg_restore 实现更 快的迁移
pg_dump 是用于备份 PostgreSQL 数据库的标准和传统实用程序。 pg_dump 对您的 Postgres 数据库进行一致的快照,即使该数据库正在被积极使用。 pg_dump 为您提供了多个命令行选项(我称它们为标志),您可以使用它们来控制正在备份的数据的格式和内容。 pg_dump 的一些常见和最有用的命令行选项使您能够执行以下操作:
- 对转储特定模式、特定表、仅数据等的细粒度控制。
- 控制转储的格式;选项包括纯文本或自定义或目录格式,默认情况下是压缩的。
- 使用 --jobs/-j 命令行选项,它提供了指定用于转储的并发线程数的能力。每个线程转储一个特定的表,此命令行选项控制同时转储多少个表。
您可以使用 pg_restore 实用程序从 pg_dump 创建的存档中恢复 PostgreSQL 数据库。与 pg_dump 类似,pg_restore 还提供了对如何恢复存档的大量控制。例如,您可以将还原限制为特定的数据库对象/实体,为还原指定并行作业等。
提示:将执行 pg_dump/pg_restore 的客户端计算机放置在尽可能靠近源和目标数据库的位置,以避免因网络延迟不良而导致的性能问题。如果两者中只有一个是可能的,您可以选择其中一个。只要确保将客户端计算机尽可能靠近目标数据库或源数据库,或两者兼而有之。
总之,pg_dump 和 pg_restore 是用于同构(Postgres 到 Postgres)数据库迁移的最常用的、本机的、健壮的和经过验证的实用程序。当您可以承受停机时间(在一些可接受的维护窗口内)时,使用这些实用程序是执行数据迁移的默认方式。
借助 pg_dump 和 pg_restore 提供的大量命令行选项,重要的是根据手头的场景以最佳方式使用这些选项。让我们来看看您可能面临的一些场景,以了解如何最好地使用 pg_dump 和 pg_restore。
如果您需要迁移超过 5 个大型 Postgres 表怎么办?
假设您的 Postgres 数据库有多个(例如,超过 5 个)大小适中(大于 5GB)的表。您可以使用 -j 标志来指定执行 pg_dump 和 pg_restore 时要使用的线程数。这样做不仅可以最大限度地利用源服务器和目标服务器上的资源(计算/内存/磁盘),而且还可以扩展可用的网络带宽。 (但是您应该小心,pg_dump 和 pg_restore 不会成为网络霸主,也不会影响您的其他工作负载。)因此,使用 pg_dump 和 pg_restore 可以提供显着的性能提升。
如果您在 Postgres 服务器上执行离线迁移,没有其他负载,您可以指定作业数是系统中核心数的倍数,这将最大限度地提高服务器上的计算利用率。但是,如果您只是出于备份/恢复原因在具有生产负载的服务器上执行转储/恢复,请务必指定一些不会影响现有负载性能的作业。
您可以使用目录格式 (-Fd),它会固有地提供压缩转储(使用 gzip)。我们有时会在使用 -Fd 标志时看到超过 5 倍的压缩。对于较大的数据库(例如超过 1 TB),压缩转储可以减少磁盘 IOP 在您从中捕获转储的服务器上遇到瓶颈的影响。
下面是示例 pg_dump 和 pg_restore 命令,它们分别使用 5 个作业进行转储和恢复:
pg_dump -d 'postgres://username:password@hostname:port/database' -Fd -j 5 -f dump_dir
pg_restore --no-acl --no-owner -d 'postgres://username:password@hostname:port/database' --data-only -Fd -j5 dump_dir
如果您的大多数表都很小,但您的一张表非常大,如何迁移?
假设您的数据库有一个大表(超过 5GB),而其余表都很小(小于 1GB)。 您可以将 pg_dump 的输出通过管道传输到 pg_restore,这样您就无需等待转储完成后再开始恢复; 两者可以同时运行。 这避免了将转储存储在客户端,这是一件好事,因为避免将转储存储在客户端可以显着减少将转储写入磁盘所需的 IOP 开销。
在这种情况下,-j 标志可能没有帮助,因为 pg_dump/pg_restore 每个表只运行一个线程。 实用程序将在转储和恢复最大的表时受到限制。 此外,不幸的是,当您使用 -j 标志时,您无法将 pg_dump 的输出通过管道传输到 pg_restore。 下面是一个显示用法的示例命令:
pg_dump -d 'postgres://username:password@hostname:port/source_database' -Fc | pg_restore --no-acl --no-owner -d 'postgres://username:password@hostname:port/target_database' --data-only
上述 2 节中的技术可以使用 pg_dump 和 pg_restore 显着缩短数据迁移时间,尤其是在涉及一个或多个大型表时。此外,这篇关于加快 Postgres 恢复速度的文章介绍了类似的技术,并为您提供了有关如何使用 pg_dump/pg_restore 实现约 100% 性能提升的分步指导。这是我最喜欢的关于 pg_dump 和 pg_restore 的 Postgres 博客之一,因此分享以供参考。
pg_dump/pg_restore 在单表级别是单线程的,这会减慢迁移速度
即使您使用上述优化,由于 pg_dump 和 pg_restore 在迁移单个表时每个都只能使用一个线程,因此整个迁移可能会在一组特定的非常大的表上出现瓶颈。对于超过 1 TB 且有几个表代表大部分数据的数据库,我们已经看到 pg_dump 和 pg_restore 需要数天时间,这导致了以下问题。
如何使用多个线程迁移 PostgreSQL 中的单个大表?
您可以利用多个线程来迁移单个大表,方法是在逻辑上将 Postgres 表分块/分区为多个部分,然后使用一对线程——一个从源读取,一个从每个部分写入目标。您可以根据水印列对表进行分块。水印列可以是单调递增的列(例如,id 列)(或)时间戳列(例如,created_at、updated_at 等)。
有许多商业工具可以实现上述逻辑。本着分享的精神,下面是一个名为 Parallel Loader 的 Python 脚本,它是上述逻辑的示例实现。如果您想自己使用,可以在 GitHub 上找到 Parallel Loader 脚本。
#suppose the filename is parallel_migrate.py
import os
import sys
#source info
source_url = sys.argv[1]
source_table = sys.argv[2]
#dest info
dest_url = sys.argv[3]
dest_table = sys.argv[4]
#others
total_threads=int(sys.argv[5]);
size=int(sys.argv[6]);
interval=size/total_threads;
start=0;
end=start+interval;
for i in range(0,total_threads):
if(i!=total_threads-1):
select_query = '\"\COPY (SELECT * from ' + source_table + ' WHERE id>='+str(start)+' AND id<'+str(end)+") TO STDOUT\"";
read_query = "psql \"" + source_url + "\" -c " + select_query
write_query = "psql \"" + dest_url + "\" -c \"\COPY " + dest_table +" FROM STDIN\""
os.system(read_query+'|'+write_query + ' &')
else:
select_query = '\"\COPY (SELECT * from '+ source_table +' WHERE id>='+str(start)+") TO STDOUT\"";
read_query = "psql \"" + source_url + "\" -c " + select_query
write_query = "psql \"" + dest_url + "\" -c \"\COPY " + dest_table +" FROM STDIN\""
os.system(read_query+'|'+write_query)
start=end;
end=start+interval;
如何调用并行加载程序脚本
python parallel_migrate.py "source_connection_string" source_table "destination_connection_string" destination_table number_of_threads count_of_table
使用 Parallel Loader 脚本,您还可以控制用于迁移大表的线程数。 在上述调用中,number_of_threads 参数控制并行度因子。
并行加载程序脚本的示例调用
python parallel_migrate.py "host=test_src.postgres.database.azure.com port=5432 dbname=postgres user=test@test_src password=xxxx sslmode=require" test_table "host=test_dest.postgres.database.azure.com port=5432 dbname=postgres user=test@test_dest password=xxxx sslmode=require" test_table 8 411187501
上述实现使用表的单调递增的 id 列将其分块并使用并行线程将数据从源表流式传输到目标表。 您可以在此 GitHub 存储库中找到使用 Parallel Loader 的一些先决条件和建议。
比较 Parallel Loader 与 pg_dump 和 pg_restore 的性能,用于大型 Postgres 表
为了比较 pg_dump 和 pg_restore 与 Parallel Loader 脚本的性能,我使用这两种技术将 1.4 TB Postgres 表(带有索引)从一个 Postgres 数据库迁移到同一区域的 Azure 中的另一个。
您可以在下表中看到,对于此 Postgres 到 Postgres 数据迁移,Parallel Loader 脚本的执行速度比 pg_dump 和 pg_restore 快了 3 倍以上。
| 并行加载器 | pg_dump & pg_restore | |
|---|---|---|
| 在同一 Azure 区域中迁移 1.4TB Postgres 数据库(带索引)的时间 | 7 小时 45 分钟 | 超过一天 |
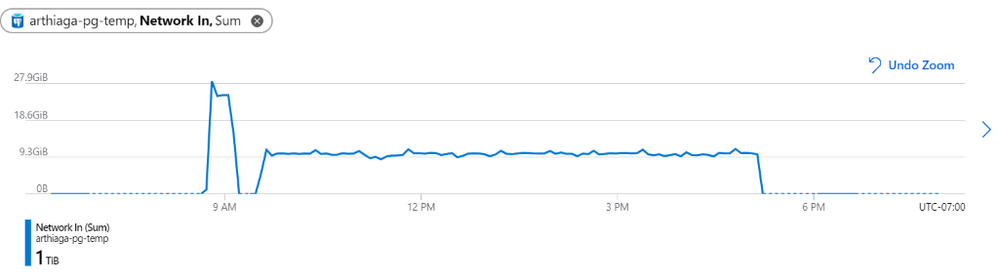
图 1:我们观察到迁移的网络吞吐量为每 5 分钟约 9.5GB,峰值为每 5 分钟 27.9GB。
Parallel Loader 使用 COPY 命令来提高性能
请注意,Parallel Loader 在每个线程中使用 COPY 命令从源读取数据并将数据写入目标数据库。 COPY 命令是在 Postgres 中批量摄取的最佳方式。 我们已经看到使用 COPY 命令的摄取吞吐量超过每秒一百万行。
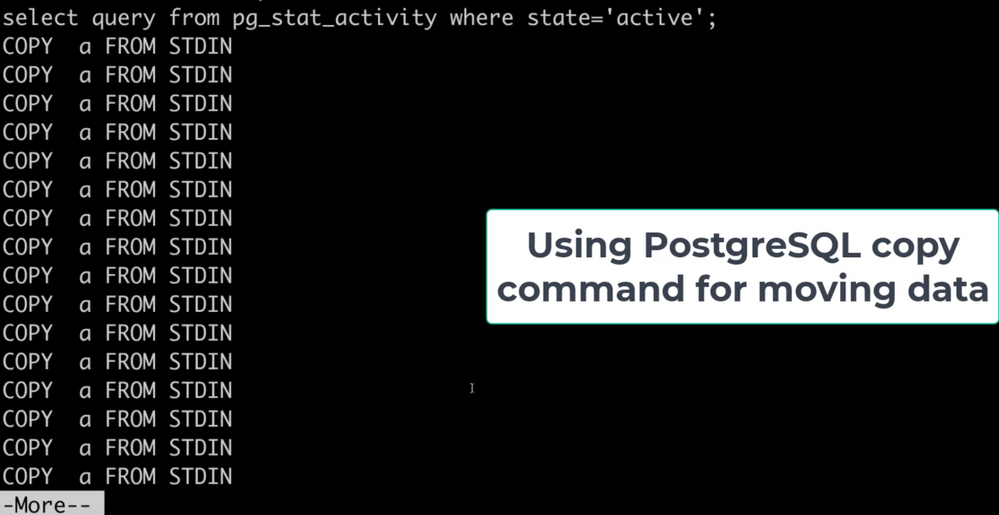
图 2:显示由目标数据库上的 COPY 命令组成的活动 (pg_stat_activity) 的屏幕截图。这些 COPY 命令由 Parallel Loader 脚本在迁移大表时生成。每个 COPY 命令都转换为脚本生成的单个线程。
底线:您可以将 pg_dump/pg_restore 与 Parallel Loader 结合使用,以实现更快的 Postgres 数据迁移
pg_dump/pg_restore 实用程序是从 Postgres 数据库迁移到另一个 Postgres 数据库的绝佳工具。但是,当数据库中有非常大的表时,它们可能会大大减慢。为了解决这个问题,您可以使用本文中介绍的方法:使用 Parallel Loader 脚本将单个大表迁移到 Postgres 并行化。我们已经看到客户结合使用 Parallel Loader 和 pg_dump/pg_restore 来成功迁移他们的 Postgres 数据库。 Parallel Loader 可以处理大型表,而 pg_dump/pg_restore 可用于迁移其余的 Postgres 表。
更有用的数据迁移资源:
- 将数据库存储对象从 Oracle 迁移到 Postgres
- 新的 Oracle 到 Postgres 迁移指南
- pg_dump 的 Postgres 文档
- pg_restore 的 Postgres 文档
- GitHub 上的 Parallel Loader 实用程序
- 用于在 Azure 上将数据迁移到/从 PostgreSQL 迁移的 Azure 数据工厂文档
- 加速 Postgres 恢复,2016 年的老歌
原文标题:Faster Data Migrations in Postgres
原文作者:Sai Krishna Srirampur
原文地址:https://techcommunity.microsoft.com/t5/azure-database-for-postgresql/faster-data-migrations-in-postgres/ba-p/2150850
