




选择比努力更重要!!!
第一篇文章我想以UNet开篇,作为图像分割领域神一般的存在,在医学影像领域影响深远,至今仍是医学图像分割的必修课。
2015年作者参加了一个果蝇细胞分割的比赛ISBI,提出了UNet。网络结构参考FCN,结构极其简单且灵活多变;在小数据集上也可以表现的较好,而医学图像的数据集一向比较难以获取。所以,UNet影响至今仍可称得上无与伦比。另外,UNet在超分辨率上的表现也是不逊于图像分割的。
1. Introduction
在2012年的ISBI的EM分割竞赛中,Ciresan等人设计网络成功摘夺桂冠。作者通过滑动窗口来训练网络,以某一像素的邻域(patch)作为输入,用于预测每个像素的类别标签。首先,该网络能够实现定位操作;其次,对像素的邻域而言,训练数据的数量需远大于训练图像的数量。
但是,上述网络中有两点明显的不足:
该网络运行效率很慢。对于每个邻域,网络都要运行一次,且对于邻域重叠部分,网络会进行重复运算;
网络需要在精确的定位和获取上下文信息之间进行权衡。越大的patch需要越多的最大池化层,其会降低定位的精确度,而小的邻域使得网络获取较少的上下文信息。
该网络没有全连接层,且仅使用每个卷积的有效部分,例如:分割图仅包含在输入图像中可获得完整上下文信息的像素。该策略允许通过重叠-切片(overlap-tile)策略对任意大的图像进行无缝分割,如下图所示。为了预测图像边缘区域中的像素的类别标签,通过对输入图像进行镜像操作来推断缺失的上下文信息。这种切片策略对于将网络应用于大型图像是重要的,否则图像的分辨率将受限于显存(the GPU memory)。
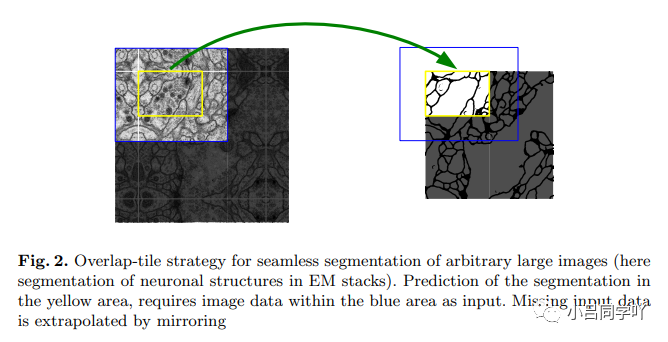
图二:上图为重叠-切片策略示意图(此处为EM stacks中神经元结构的分割)。预测黄色方框中的分割需要蓝色方框中的图像数据作为输入,缺失的数据由镜像推断。上图白色方框内是原始输入图像,边缘区域是由原图镜像产生的,然后根据蓝色方框的图像作为输入,预测出来黄色方框的分割图。
形变是组织中最常见的变化,因此对可用的训练图像广泛地应用弹性形变的图像增强方法,使得网络能够学习这种形变的不变性,无需提供带注释的图像语料库(the annotated image corpus)供网络学习,且实际的形变能有效地模拟。这在医学图像的分割是特别重要的。
在许多细胞分割任务中的另外一个挑战为对同一类别的接触目标的分离,如下图所示。为此,采用加权损失,即在细胞接触之间的分离背景标签中的损失函数中设置较大大的权重。
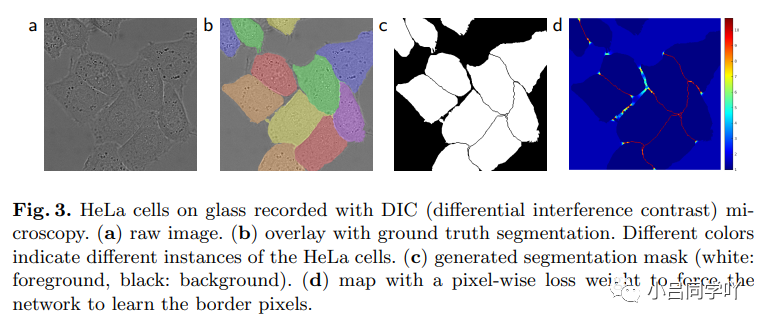
图三:上图为DIC(微分干涉,differential interference contrast)显微镜记录的HeLa细胞。图a为原始图像;图b为与真实的带标记的分割数据相叠加,其中不同的颜色表示HeLa细胞的不同实例(instance);图c为生成的分割掩膜,其中白色区域表示前景,黑色区域表示背景;图d为用于网络学习边缘像素的带加权损失的像素图。
2. Network Architecture
U-net网络由一个收缩路径(左边)和一个扩张路径(右边)组成。其中,收缩路径用于获取上下文信息(context),扩张路径用于精确的定位(localization),且两条路径相互对称。
该网络能从极少的训练图像中,依靠数据增强将有效的标注数据更为有效地使用。
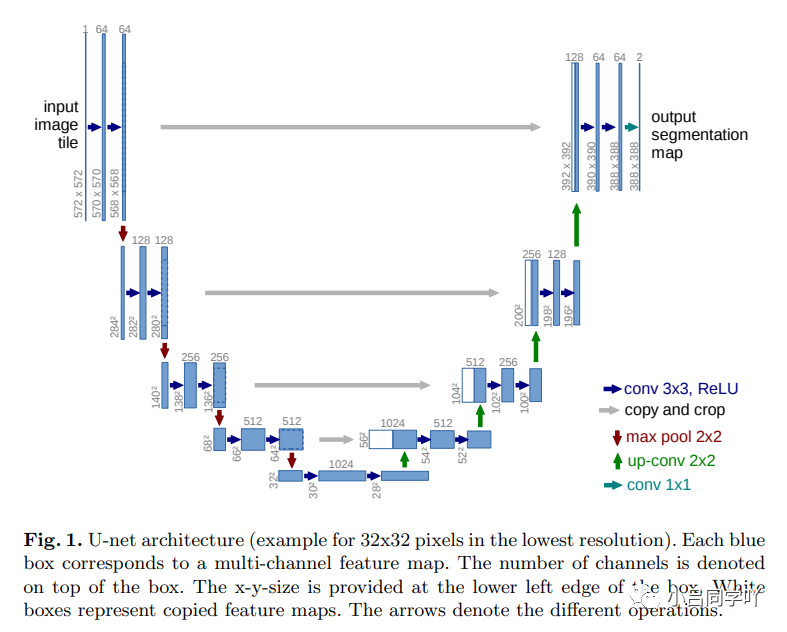
图一:上图为U-net网络结构图(以最低分别率为32*32为例)。每个蓝色框对应一个多通道特征图(map),其中通道数在框顶标,x-y的大小位于框的左下角;白色框表示复制的特征图;箭头表示不同的操作。
其中,收缩路径遵循典型的卷积网络结构,其由两个重复的3 × 3卷积核(无填充卷积,unpadded convolution)组成,且均使用修正线性单元(rectified linear unit,ReLU)激活函数和一个用于下采样(downsample)的步长为2的2 × 2最大池化操作,以及在每一个下采样的步骤中,特征通道数量都加倍。
在扩张路径中,每一步都包含对特征图进行上采样(upsample);然后用2 × 2的卷积核进行卷积运算(上卷积,up-convolution),用于减少一半的特征通道数量;接着级联收缩路径中相应的裁剪后的特征图;再用两个3 × 3的卷积核进行卷积运算,且均使用ReLU激活函数。
在最后一层,利用1 × 1的卷积核进行卷积运算,将每个64维的特征向量映射网络的输出层。总而言之,该网络有23个卷积层。
由于在每次卷积操作中,边界像素存在缺失问题,因此有必要对特征图进行裁剪。
3. Training
由于未填充的卷积其输出图像的大小小于恒定边界宽度的输入。为了最小化开销和最大限度地利用显存,比起输入一个较大的批次,更倾向于较大的输入切片,因而将批次大小缩减为单张图像。相应地,通过使用高动量(high momentum,0.99)使得大量先前的训练样本在当前的优化步骤中更新。
能量函数(the energy function)是通过与交叉熵损失函数相结合的最终特征图,并利用像素级的soft-max函数来计算的。soft-max函数定义为:
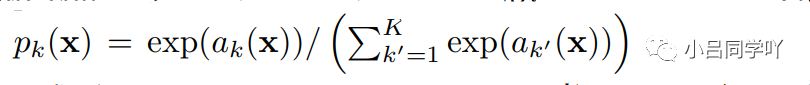
其中,ak(x)表示在第x像素点上第k个特征通道的激活函数。K为类别数,pk(x)为近视最大函数(the approximated maximum-function)。
加权交叉熵定义为:
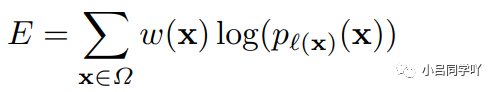
其中,l=1, ..., K表示每个像素正确的标签,权重函数ω,且将权重函数定义为:
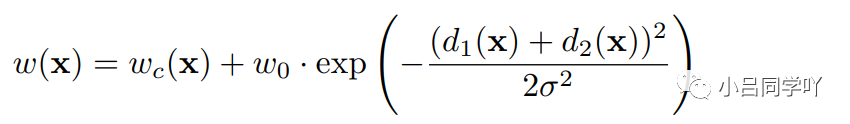
其中,ω表示平衡类别频率的权重图,d1表示到最近细胞边界的距离,d2表示到第二近细胞边界的距离。
基于经验,将ω0=10和σ≈5像素。对于分割边界操作,使用了形态学方法。
权值初始化:
在有许多卷积层和不同路径的深度网络中,良好的权值初始化是非常重要的。否则,网络的某些部分可能会提供过多的激活,而其他部分永远不会提供。理想情况下,初始权值的调整应使网络中的每个特征映射具有近似的单位方差。对于具有我们的架构的网络(交替卷积和ReLU层),这可以通过从一个标准差为p2/N的高斯分布中提取初始权值来实现,其中N表示一个神经元的传入节点数。例如,对于一个3x3的卷积和前一层的64个特征通道,N=9×64=576。
3.1. 图像增强
当只有少量的训练样本可用时,数据扩充是使网络具有所需的不变性和鲁棒性的关键。对于显微图像,我们主要需要位移和旋转不变性以及对变形和灰度值变化的鲁棒性。特别是训练样本的随机弹性变形似乎是训练带少量标注图像的分割网络的关键概念。
在3×3的网格上使用随机位移矢量产生平滑形变,其中位移来自于10像素标准差的高斯分布,且通过双三次插值法计算得出。在收缩路径的末尾的drop-out层进一步暗示了数据增强。
4. Experiments
略。实验结果比较好,此处就不详加介绍了。
参考:
[1] U-Net: Convolutional Networks for Biomedical Image Segmentation (arxiv.org)
不定期更新文章,关注我一起共同进步!
