





导读:最近多次被小伙伴问到关于 Routine Load 消费延迟的问题,这里分享最近解决的关于 kafka 向 Doris 写入数据的消费延迟问题的调优过程,希望能提供一些参考意义。
作者|百度资深研发工程师 陈林忠
问题背景
某业务使用 Doris 构建实时数仓,其业务在白天的 Routine Load 平均写入速度为 200-300MB/s,同时集群有约100 QPS的查询负载和部分例行任务。
问题现象
某业务采用 Routine Load 方式从kafka导入数据到 Doris,近期频发整点延迟问题,业务延迟敏感,初步分析延迟有2个基本特征
整点出现
前15分钟消费延迟导致持续堆积,15分钟后回落
kafka 消息堆积如图:
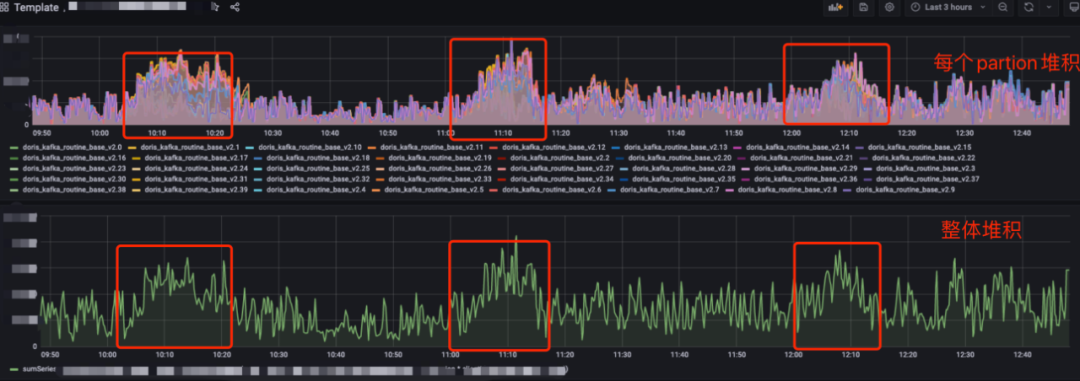
回顾 Routine Load 导入原理
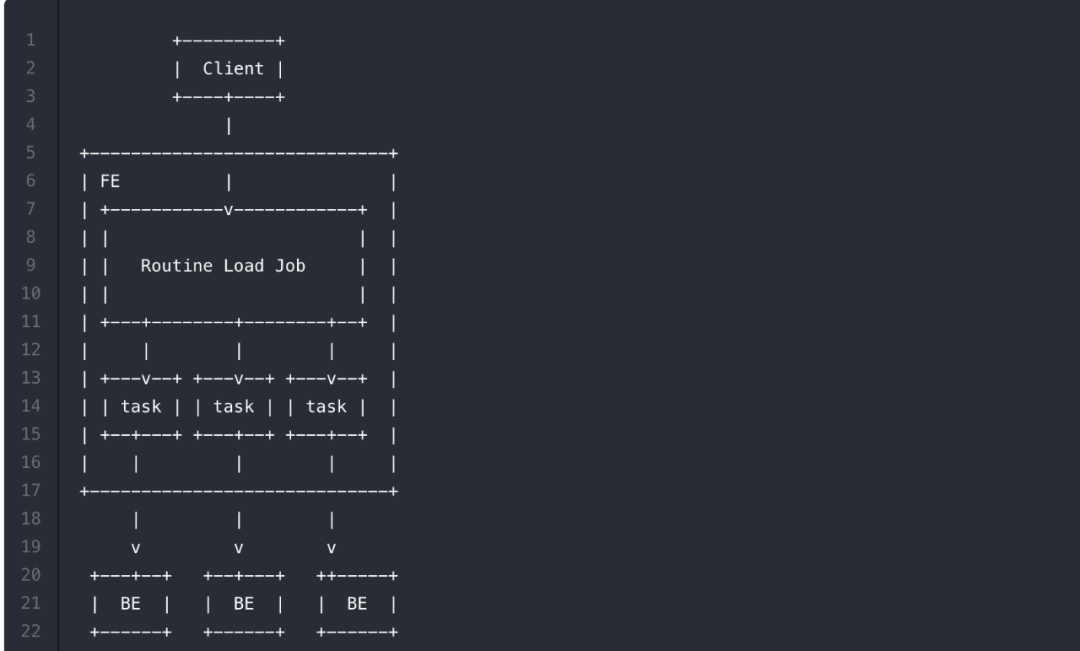
如上图,Client 向 FE 提交一个 Routine Load 作业。
FE 通过 JobScheduler 将一个导入作业拆分成若干个 Task。每个 Task 负责导入指定的一部分数据。Task 被 TaskScheduler 分配到指定的 BE 上执行。
在 BE 上,一个 Task 被视为一个普通的导入任务,通过 Stream Load 的导入机制进行导入。导入完成后,向 FE 汇报。
FE 中的 JobScheduler 根据汇报结果,继续生成后续新的 Task,或者对失败的 Task 进行重试。
整个 Routine Load 作业通过不断地产生新的 Task,来完成数据不间断的导入。
简单总结下:Routinue Load 底层是通过 Stream Load 方式来导入,每一次导入看做是一个 Task,这个 Task 由 FE 下发 BE 执行, Task 完成一批数据导入后通知 FE,FE 更新 Offset 后继续下发新 Task,不断重复这个过程,从而完成数据写入。
其中有2个关键问题:
问题1:每个 Task 读取多少数据后执行真正数据写入呢?
有可能 kafka 一条没有,不能一直等待,有可能kafka中数据量很多,不能一次都读完,Doris通过3个配置项参数来控制:
max_batch_interval: 最大超时时间,BE从kafka中读取最大的读取时间
max_batch_rows: 最大读取的条数
max_batch_size:最大读取的一批的大小
Task 在 BE 上执行时满足这三个条件任意一个则认为读取完成,开始执行真正导入
问题2:如果集群 Routine Load 任务很多, BE 上运行过多的task,负载高,影响集群的稳定性,doris怎么处理的?
doris会控制每个集群的任务的并发数,也叫槽位数,FE下发任务前需要确保BE上由剩余的槽位才下发,这个目的是确保集群负载在一个安全的范围,槽位数是整个集群task共享的,对应配置名称:
routine_load_thread_pool_size:BE侧配置,槽位数,默认值为5,每个BE能同时并行处理多少个roune load任务
max_routine_load_task_num_per_be: FE侧配置,每个BE能做多能同时处理多少个任务,默认值为5
原因分析
1.业务写入量增加导致消费不及时
由于整点延迟特征明显,先观察业务写入量,发现存在整点上涨的情况
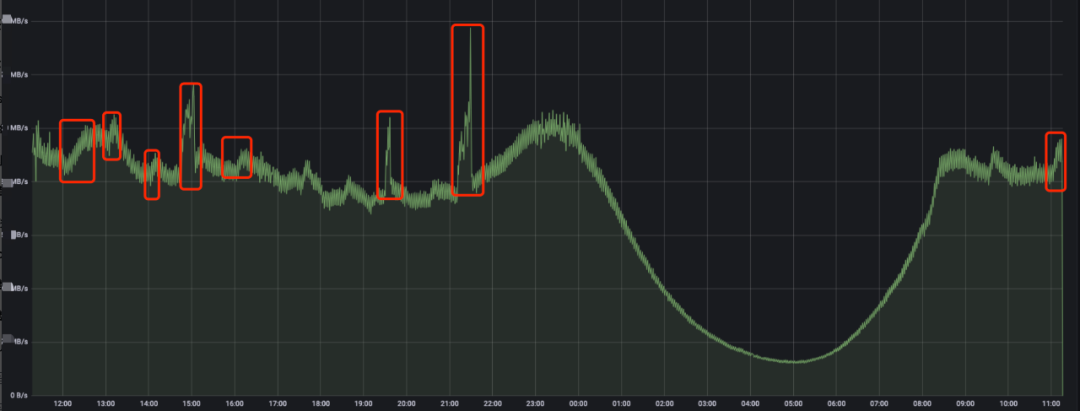
再看下 Doris 的消费能力,发现每次都是批次读满后写入 (left_bytes <0,也即读数据操作是满足 max_batch_size 条件 )到 Doris 中
// be上执行,
grep --color '${label}' be.INFO | grep 'consumer group done'

left_rows、left_time、left_bytes 中哪个值小于0,说明 Task 是满足哪个条件读取数据完成
所以很自然得出初步结论是,kafka 整点写入过大, Doris处理由于批次大小的限制,导致 kafka积累,当前配置批次大小 max_batch_size=500M,所以尝试调大max_batch_size=1G 再继续观察
调整后效果并不明显,延迟依旧存在,同时业务侧反馈这个流量的特征一直都是这样整点有上涨,之前也没有出现延迟,所以流量增长不是根本原因。
2.FE调度瓶颈,Routine Load Task 调度次数少
分析该task的对应调度超时时间为60s,也就是说60s内至少调度一次,每小时调度60次(理论值),找一个BE节点,看节点上多少任务,和每个任务的小时级的调度次数,看下对应的 Task 调度次数,到 BE 上执行命令
//查询05.25 号13点的
grep 'consumer group done' be.INFO | grep 'I0525 13' | awk -F ',' '{print $13}' | awk -F '=' '{print $2}' | awk -F '-' '{print $1}' | sort | uniq -c | sort -nr -k 1

发现当前集群任务种类很多,数十个 Routinue Load Task,每个 Task 调度次数不均匀有的多有的少
上面业务对应的task每小时只有被调度了11次,远小于60理论值, 所以很大可能FE调度不过来,或者是任务的调度资格被抢占了
看下FE的调度日志,到masterFE上执行如下命令,查询对应BE节点的调度情况
// FE默认日志不是 debug 级别,所以需先把日志级别调整为 debug,如何调整debug日志级别?
grep ${beId} fe.log | grep "has idle"
${beId} 表示BE节点的编号,通过show backends 找到

发现有大量的idle=0日志,这个表示没有剩余槽位,当前这次调度失败,调度失败后,任务会重新扔回队列,并且等待下一次调度
所以到这里原因也明确了,集群的 Routine Load Task 较多,由于是共享槽位,任务间调度存在抢占,导致调度次数少影响了消费,之前没有问题因为集群开始的时候 Task 较少,任务抢占不明显,随着时间的推移,新增的task越来越多,抢占导致的问题明显加剧
回到上面现象特征:
整点出现是因为正常情况下该的任务调度虽然远小于理论值,却刚好可以消费完数据,当整点时流量上涨时消费不过来产生积压
前增后落是因为业务流量整点上涨15分钟后回落,产生的积压会随着慢慢回落
所以知道了原因后,在集群负载安全的前提下,只需要把槽位数增加,让每个 BE 节点执行更多任务就能缓解,对应配置是:
routine_load_thread_pool_size:BE 侧配置,槽位数,默认值为5,每个BE能同时并行处理多少个roune load任务
max_routine_load_task_num_per_be: FE 侧配置,每个BE能做多能同时处理多少个任务,默认值为5
将集群上面两个配置调大一倍后,延迟平稳,问题解决

总结
routine load 整个过程分为FE调度,BE执行,所以如果出现消费慢了主要是是看BE的执行情况,和FE的调度情况,BE执行主要看下批次大小是否设置合理比如kafka写入量大,可以把max_batch_size调大,如果kafka写入小,可以把超时时间调小,降低槽位占用情况,如果调度存在瓶颈,在BE的集群负载安全的情况下(主要看cpu_idle,io_util指标) ,可以适当把单个BE的槽位数调大,增加任务的调度机会,如果集群负载比较高,可以考虑新增集群把任务做拆分。
参考
doris routine load 文档: https://doris.apache.org/zh-CN/docs/data-operate/import/import-way/routine-load-manual.html#%E7%9B%B8%E5%85%B3%E5%8F%82%E6%95%B0
调整FE日志级别为DEBUG: https://doris.apache.org/zh-CN/docs/advanced/best-practice/debug-log.html#%E5%BC%80%E5%90%AF-fe-d
如果您遇到任何使用上的问题,欢迎随时通过 GitHub Discussion 论坛或者 Dev 邮件组与我们取得联系。
GitHub 论坛:https://github.com/apache/doris/discussions
Dev 邮件组:dev@doris.apache.org
微信公众号:

Apache Doris官方网站:
http://doris.apache.org
Apache Doris Github:
https://github.com/apache/doris
Apache Doris 开发者邮件组:
dev@doris.apache.org
精彩文章推荐
应用实践 | 知乎基于 Apache Doris 的 DMP 系统的架构与实践 技术实现 | Apache Doris 冷热数据存储(一) Apache Doris 技术实现 - 冷热数据存储(二) 活动邀请 | Apache Doris 社区征文&演讲征集活动开始了!
