





栗友们,大家好!我是Zarc
“上期讲到BERT类模型存在的语义坍缩问题,我在文章发布后又仔细看了相关资料,发现其实那些采用transformer结构的模型都或多或少存在这个问题,即词向量空间分布不均衡。”
从这期开始将会连载分享我在学习transformer过程中的一些记录!
“关于transformer的结构、原理、起源等内容的分享网上有很多,这里就不再赘述,强烈推荐B站上李沐老师的transformer讲解[1]的视频。”
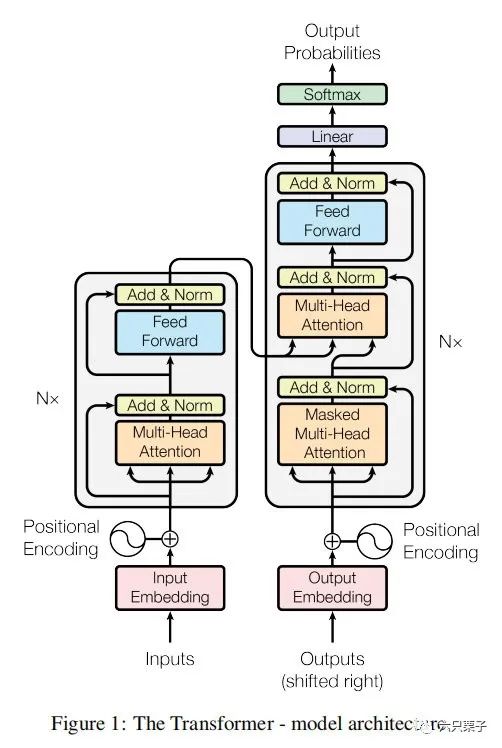
如下图所示,transformer是一个自回归模型,编码器和解码器的结构。
本文将分别介绍在实际使用transformer过程中编码器和解码器各个组成单元的输入输出,来帮助大家更进一步理解它的原理。
transformer结构图
01
—
Encoder部分
Input embedding
input embedding的输入为原始的文本embedding叠加一个positional embedding,这个positional embedding是跟输入的原始文本embedding的维度一致,得到模型的输入embedding,也就是multi-head attention的输入,需要关注的是这里使用的mask机制是padding_mask机制,截长补短来统一长度,关于它的positional embedding,可以使用相对位置编码方式和绝对位置编码方式,其中绝对位置编码方式更能表达文本之间位置的相对距离,关于这两种位置编码方式,下期文章将会专门介绍。
输入size:[batch_size, seq_length]
embedding后输出维度:[batch_size, seq_length, model_d]
multi-head attention(多头注意力机制)
左侧为注意力机制的计算规则,右侧为多头注意力机制的原理
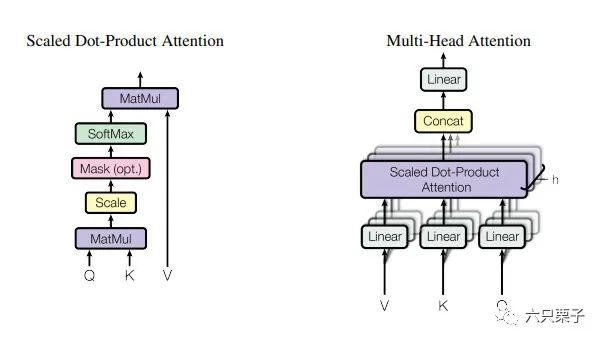
首先是注意力机制的实现(对于单条数据,无多头注意力的情况):
给每个编码器的输入向量中的每个单词创建三个权重矩阵,即Q、K、V矩阵,每个矩阵的大小为[model_d,model_d],这些矩阵的参数可以学习, 将每个句子中所有单词的embedding [seq_length, model_d]与之前创建的权重矩阵相乘,得到 ,维度为[seq_length, model_d] 将每条数据的 和 进行点积计算,来得到句子中的词之间的注意力得分,即得到注意力得分矩阵,大小为[seq_length, model_d] * [seq_length, model_d]的转置,即[seq_length, model_d] * [model_d, seq_length],得到[seq_length, seq_length] 对每条数据的词之间的注意力得分矩阵进行缩放,从而得到更稳定的梯度,论文中默认值是除以model_d的向量维数的平方根 对缩放后的注意力得分矩阵进行归一化,使用的是soft_max函数,这个soft_max函数得分表示每个单词在这个位置与其他单词的相关性的表达,维度仍然是[seq_length, seq_length],在缩放之前有一个可选的mask机制,目的是让那些padding后的向量变为无穷小,经过soft_max后为0 将缩放归一化后的注意力得分矩阵和W_V矩阵进行内积计算,即[seq_length, seq_length] * [seq_length, model_d],得到[seq_length, model_d],这一步的目的是对原始的输入信息进行加权,就得到注意力机制的输出[seq_length, model_d]
上述就是对于单条数据的注意力机制的过程,输入输出都为[seq_length, model_d],如果是处理一批数据,则为[batch_size, seq_length, model_d],对于多头注意力机制,就是在创建Q、K、V矩阵时为每个单词分配n 个Q、K、V权重矩阵,原文是8个,则相应的上方的model_d变为model_d 8,最后在输出的时候拼接起来,即Con-cat(head 1,head 2,......,head 8),多头注意力机制的引入作用类似于CNN中的多卷积核功能,增强模型的特征提取能力。
输入size:[batch_size, seq_length, model_d]
attention后输出维度: [batch_size, seq_length, model_d]
全连接层(Feed Forward Network)
编码器和解码器中的每一层除了注意子层外,还包含一个全连接的前馈网络,这个F F N包含两个线性变换,中间有一个ReLU激活。公式如下:,全连接层的输入输出都是model_d维,即512,中间层的维度是2048
输入size:[batch_size, seq_length, model_d]
全连接层后输出维度: [batch_size, seq_length, model_d]
02
—
Decoder部分
output embedding
output embedding除了输入为原始的翻译后的文本embedding外,其他的部分与模型编码器的输入部分的input embedding相同
输入size:[batch_size, seq_length]
embedding后输出维度:[batch_size, seq_length, model_d]
masked multi-head attention
这个地方的多头attention与之前编码器部分的多头attention类似,只是加了一个mask机制,原因是在解码器部分获得翻译后的文本的输入时,不能看到待翻译文本及其之后的文本,只能看到历史的翻译后的文本信息,因此对这些文本需要进行mask。在time_step为t的时刻,我们的解码输出应该只能依赖于t时刻之前的输出,而不能依赖t之后的输出。因此我们需要想一个办法,把t之后的信息给隐藏起来。那么具体怎么做呢?也很简单:产生一个上三角矩阵,上三角的值全为0,下三角的值全为1,对角线也是0。把这个矩阵作用在每一个序列上。
输入size:[batch_size, seq_length, model_d]
attention后输出维度: [batch_size, seq_length, model_d]
multi-head attention
此处的多头注意力机制与编码器部分的多头注意力机制类似,只是模型的输入不一样,之前是文本+位置的embedding作为输入,此处为了融合翻译前后的信息,对编码器和解码器的信息进行融合,注意力机制输入的queue矩阵和key矩阵来自于编码器部分,输入的value矩阵来自于解码器部分
输入size:[batch_size, seq_length, model_d]
attention后输出维度:[batch_size, seq_length, model_d]
Add + Normalization
残差连接和层归一化与编码器部分相似,有两个地方使用到残差连接模块,一个是解码器部分的embedding和masked multi-head attention的输出,另一个是masked multi-head attention的输出和multi-head attention的输出。
输入size:[batch_size, seq_length, model_d]
残差和归一化后输出维度: [batch_size, seq_length, model_d]
linear + soft_max
将最后的attention向量映射到一个包含所有类别的线性空间,经过soft_max函数来计算最终的预测的概率得分。
03
—
总结
行文至此,transformer的各个模块就介绍完了,面试过程中面试官往往会针对其中的细节进行追问,我梳理下了我在实际面试过程中遇到的相关问题,希望对大家能够有所帮助。
Transformer为何使用多头注意力机制?(为什么不使用一个头) Transformer为什么Q和K使用不同的权重矩阵生成,为何不能使用同一个值进行自身的点乘?(注意和第一个问题的区别) Transformer计算attention的时候为何选择点乘而不是加法?两者计算复杂度和效果上有什么区别? 为什么在进行softmax之前需要对attention进行scaled(为什么除以dk的平方根),并使用公式推导进行讲解 在计算attention score的时候如何对padding做mask操作? 为什么在进行多头注意力的时候需要对每个head进行降维?(可以参考上面一个问题) 大概讲一下Transformer的Encoder模块? 为何在获取输入词向量之后需要对矩阵乘以embedding size的开方?意义是什么? 简单介绍一下Transformer的位置编码?有什么意义和优缺点? 你还了解哪些关于位置编码的技术,各自的优缺点是什么? 简单讲一下Transformer中的残差结构以及意义。 为什么transformer块使用LayerNorm而不是BatchNorm?LayerNorm 在Transformer的位置是哪里? 简答讲一下BatchNorm技术,以及它的优缺点。(这里推荐下栗子鑫的文章——《BN——虽然玄学,但是养活了很多炼丹师》) 简单描述一下Transformer中的前馈神经网络?使用了什么激活函数?相关优缺点? Encoder端和Decoder端是如何进行交互的?(在这里可以问一下关于seq2seq的attention知识) Decoder阶段的多头自注意力和encoder的多头自注意力有什么区别?(为什么需要decoder自注意力需要进行 sequence mask) Transformer的并行化体现在哪个地方?Decoder端可以做并行化吗? 简单描述一下wordpiece model 和 byte pair encoding,有实际应用过吗?
下期将会带来位置编码技术的分享,敬请期待!
关注六只栗子,面试不迷路!
参考资料
李沐老师的transformer讲解: https://www.bilibili.com/video/BV1pu411o7BE?spm_id_from=333.999.0.0
作者 Zarc
编辑 一口栗子
