





栗友们,大家好!我是Zarc
“上期和大家分享了 Transformer 的位置编码原理,其实以自注意力机制为核心的 Transformer 模型是各种预训练模型中的主要组成部分。自注意力机制能够构建序列中各个元素之间的上下文关联程度,挖掘更深层次的语义信息。然而,自注意力机制的时空复杂度为 ,即时间和空间的消耗会随着序列长度呈平方级增长。这种问题的存在会使得预训练模型处理长文本的效率变低。”
接下来几期将会来和大家一起分享Transformer在处理长文本序列时的几个变种,本期要分享的变种是 Transformer-XL。
01
—
Motivation
在介绍Transformer-XL之前,首先要提到 vanilla Transformer[1],Transformer-XL是在它的基础上进一步改进。
vanilla Transformer是 Al-Rfou 等人基于Transformer提出了一种训练语言模型的方法,由于Transformer只能编码固定长度的上下文,来根据之前的字符预测片段中的下一个字符,vanilla Transformer等Transformer模型在处理那些长文本时的做法是将一个长的文本序列截断为多个包含几百个字符的固定长度的片段,然后分别编码每个片段,但是每个片段之间没有任何的信息交互。
如下图所示,在训练阶段,它分别对第一块中的 和第二块中的 进行建模;在测试阶段,由于每次处理的最大长度为4,当模型处理序列 时,无法构建与历史 的关系。另外,由于需要以滑动窗口的方式处理整个序列,所以这种方式效率十分低下。
Transformer处理长文本的传统方法
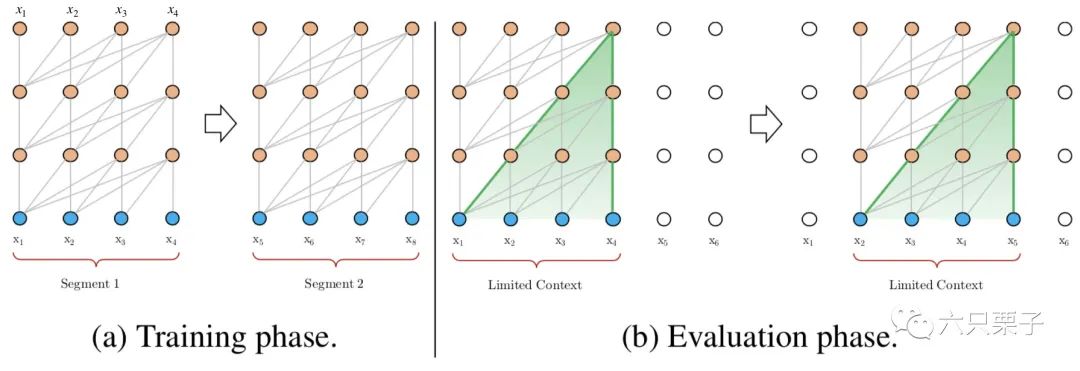
所以虽然这种模型对长文本的处理方式在常用的数据集上的表现比循环神经网络(RNN)更好,但是它仍然有以下几个缺点:
上下文长度受限:字符之间的最大依赖距离受输入长度的限制,模型看不到出现在几个句子之前的单词。 上下文碎片:对于长度超过512个自字符的文本,都是需要从头开始训练的,段与段之间没有上下文依赖性,会让训练效率低下,也会影响模型的性能。 推理速度慢:在测试阶段,每次预测下一个单词,都需要重新构建一遍上下文,并且从头开始计算,这样的计算速度慢。
02
—
Transformer-XL[2]
为了优化对长文本的建模,Transformer-XL提出了两种改进策略——状态复用的块级别循环(Segment-level Recurrence with State Reuse)和相对位置编码(Relative Positional Encodings)。
状态复用的块级别循环
与vanilla Transformer的基本思路一样,Transformer-XL仍然是使用分段的方式进行建模,但其与vanilla Transformer的本质不同是在于引入了段与段之间的循环机制,使得当前段在建模的时候能够利用之前段的信息来实现长期依赖性。如下图所示:
Transformer-XL引入的循环机制
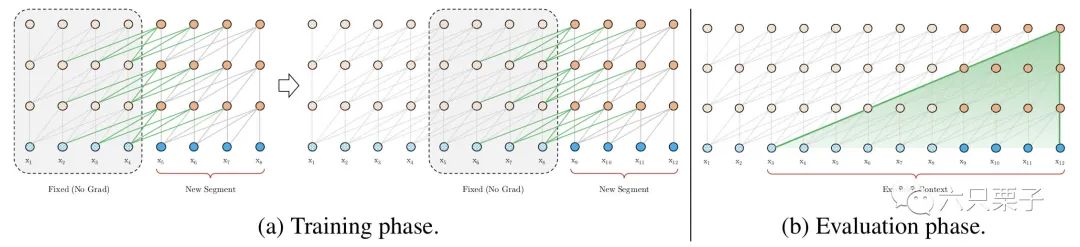
在训练阶段,处理后面的块时,每个隐藏层都会接受两个输入:
该块的前面浅层隐藏层的输出,与vanilla Transformer类似。 前面块的隐藏层的输出,可以使得模型建立长期依赖关系。
这两个输入会被拼接,然后用于计算当前段的 Key 和 Value 矩阵,对于某一段某一层的具体计算公式如下:
其中:
表示第几段;
表示第几层;
表示隐藏层的输出;
表示停止计算梯度;
表示在长度维度上的两个隐层的拼接;
是模型参数。
乍一看,它的计算公式与Transformer比较类似,唯一不同的地方在于Key和Value矩阵的计算上,即 ,它们是基于扩展后的上下文隐层状态 和之前块的缓存信息 ,这种状态复用的块级别循环机制应用于语料库中每两个连续的片段,本质上是在隐含状态下产生一个片段级别的循环。因此,在这种机制下,Transformer利用的有效上下文可以远远超出两个块,同时需要注意的是, 和 之间的循环依赖性使得存在向下一层的计算依赖,这与传统的循环神经网络中的同层循环机制(只存在于相同层之间的循环)是不同的。因此,最大可能的依赖长度随着块的长度 和层数 呈线性增长,即 ,这种机制与RNN中常用的随时间反向传播机制类似,这里是将整个隐层状态全部缓存,而不是RNN那样只保留最后一个状态。
另外,这种设计除了能够处理更长的文本序列,还可以加快测试速度,按照作者的说法,Transformer-XL相比Transformer在测试阶段实现1800倍以上的加速。
相对位置编码
虽然状态复用的块级别循环技术能够将不同块之间的信息联系起来,但是在实际应用中还有一个重要的问题:如何区分不同块中的相同位置?如果采用Transformer中的绝对位置编码方式,那么就会导致对于不同的块,它们的位置向量都是一样的,这显然是不合理的。(关于位置编码的相关知识,可以看我的上篇文章——跟所有的位置编码说嗨嗨)
为了解决这个问题,Transformer-XL引入了相对位置编码策略。位置信息的重要性主要体现在注意力矩阵的计算上,用于构建不同词之间的关联关系,应用相对位置编码后,第 个词和第 个词之间的注意力值 为:
其中:
和 表示可训练的权重(其中 );
表示 所对应的词向量;
表示相对位置矩阵(其中 , 表示最大编码长度),是一个不可训练的正弦编码矩阵,其中第 行表示相对位置间隔为 的位置向量。
接下来针对上式中的各个部分进行介绍:
基于内容的相关度(a):计算查询 与 的内容之间的关联信息; 基于相关信息的位置偏置(b):计算查询 的内容与 的位置编码之间的关联信息, 表示两者的相对位置信息,取 中的第 行; 全局内容偏置(c):计算查询 的位置编码与 的的内容之间的关联信息; 全局位置偏置(d):计算查询 与 的位置编码之间的关联信息。
03
—
总结
这期主要是和大家分享Transformer的变种之一——Transformer-XL,它针对Transformer在处理长文本序列时存在的问题进行了改进,提出了状态复用的块级别循环和相对位置编码,这种改进极大提升了模型的速度和精度,其实针对Transformer在处理长文本序列的改进方法远远不止Transformer-XL一种,各种魔改transformer层出不穷,下期将会和大家分享Transformer的变种之二——Reformer
下期不见不散~
关注六只栗子,面试不迷路!
参考资料
vanilla Transformer: https://arxiv.org/abs/1808.04444
[2]Transformer-XL: https://aclanthology.org/P19-1285.pdf
作者 Zarc
编辑 一口栗子
