




ClickHouse介绍
Clickhouse是一个面向联机分析处理(Olap)的开源的面向列式数据库管理系统(DBMS)。在2016年开源,开发语言为C++,是一款PB级的交互式分析数据库,与Hadoop, Spark相比,ClickHouse很轻量级。主要用于在线分析处理查询(OLAP),能够使用SQL查询实时生成分析数据报告。
ClickHouse特点
列式存储
以下面的表为例:
| Id | Name | Age |
|---|---|---|
| 1 | 张三 | 18 |
| 2 | 李四 | 22 |
| 3 | 王五 | 34 |
采用行式存储时,数据在磁盘上的组织结构为:
| 1 | 张三 | 18 |
|---|---|---|
| 2 | 李四 | 22 |
| 3 | 王五 | 34 |
好处是想查某个人所有的属性时,可以通过一次磁盘查找加顺序读取就可以。但是当想查所有人的年龄时,需要不停的查找,或者全表扫描才行,遍历的很多数据都是不需要的。
采用列式存储时,数据在磁盘上的组织结构为:
| 1 | 2 | 3 |
|---|---|---|
| 张三 | 李四 | 王五 |
| 18 | 22 | 34 |
这时想查所有人的年龄只需把年龄那一列拿出来就可以了
列式储存的好处:
对于列的聚合,计数,求和等统计操作原因优于行式存储。
由于某一列的数据类型都是相同的,针对于数据存储更容易进行数据压缩,每一列选择更优的数据压缩算法,大大提高了数据的压缩比重。
由于数据压缩比更好,一方面节省了磁盘空间,另一方面对于cache也有了更大的发挥空间。
行存和列存查询性能区别
行式:从存储系统读取所有满足条件的行数据,然后在内存中过滤出需要的字段,速度较慢。
列式:仅从存储系统中读取必要的列数据,无用列不读取,速度非常快。
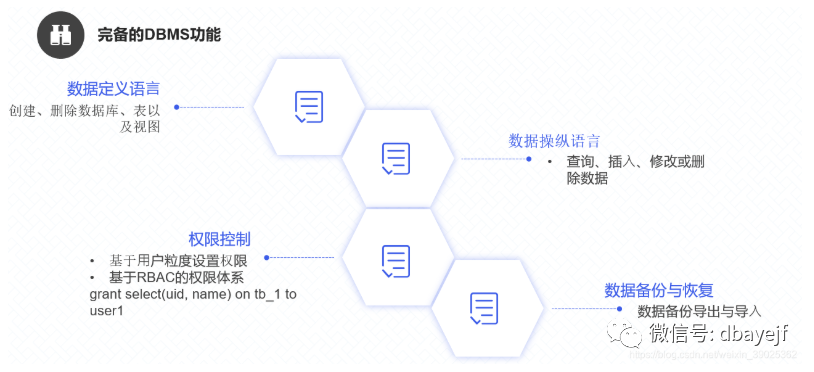
DBMS的功能
几乎覆盖了标准SQL的大部分语法,包括 DDL和 DML,以及配套的各种函数,用户管理及权限管理,数据的备份与恢复。
向量引擎
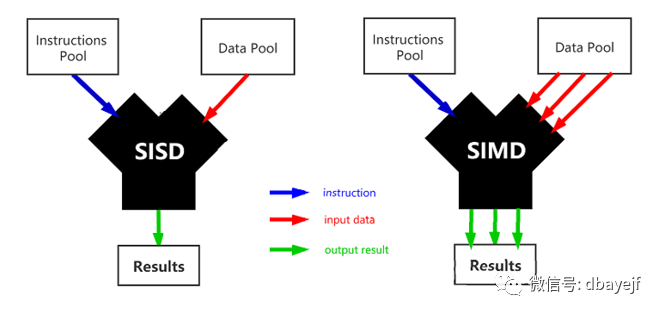
向量化执行与SIMD
SIMD (Single lnstruction Multiple Data)即单条指令操作多条数据,它是通过数据并行以提高性能的一种方式;
可以简单理解为在寄存器层面对程序中的数据做并行处理。
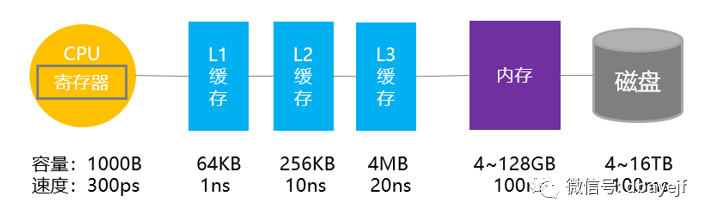
距离CPU越远,数据访问的速度越慢。从上面看从寄存器中访问数据的速度,是从内存访问速度的300倍,是从磁盘中访问速度的3000万倍。
在支持列存的基础上,ClickHouse大量的处理操作都是向量化执行的。相比于传统火山模型中的逐行处理模式,向量化执行引擎采用批量处理模式,可以大幅减少函数调用开销(一个batch调用一次SIMD指令,而非一行),降低指令、数据的CacheMiss (CPU cache预读能力),提升CPU利用效率,带来数倍的性能提升。
分布式计算
在ClickHouse中,数据可以保存在不同的shard上,每一个shard都由一组用于容错的replica组成,查询可以并行地在所有shard上进行处理。这些对用户来说是透明的 。
分布式查询示意图:
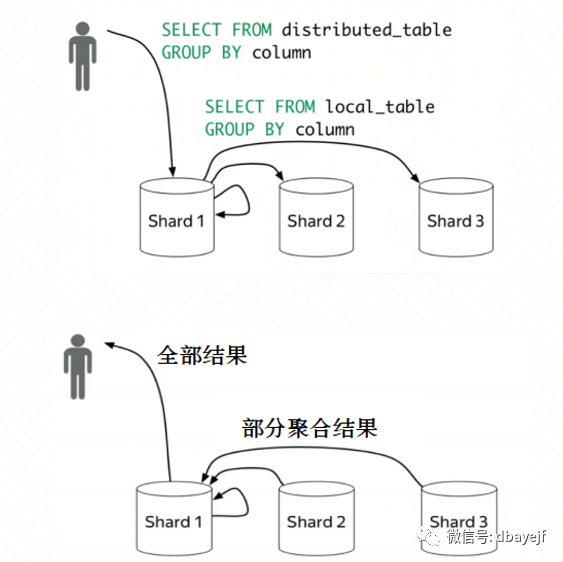
数据分区与线程级并行
ClickHouse将数据划分为多个partition,每个partition再进一步划分为多个index granularity(索引粒度),然后通过多个CPU核心分别处理其中的一部分来实现并行数据处理。在这种设计下,单条Query就能利用整机所有CPU。极致的并行处理能力,极大的降低了查询延时。
所以,ClickHouse即使对于大量数据的查询也能够化整为零平行处理。但是有一个弊端就是对于单条查询使用多cpu,就不利于同时并发多条查询。所以对于高qps的查询业务,ClickHouse并不是强项。
多样化引擎
ClickHouse和MySQL类似,把表级的存储引擎插件化,根据表的不同需求可以设定不同的存储引擎。目前包括合并树、日志、接口和其他四大类20多种引擎。
ClickHouse局限
没有完整的事务支持。
缺少高频率,低延迟的修改或删除已存在数据的能力。仅能用于批量删除或修改数据。
稀疏索引使得ClickHouse不适合通过其键检索单行的点查询。
稀疏索引在表引擎MergeTree会介绍
ClickHouse应用场景
绝大多数请求都是用于读访问的
数据需要以大批次(大于1000行)进行更新,而不是单行更新;或者根本没有更新操作
数据只是添加到数据库,没有必要修改
读取数据时,会从数据库中提取出大量的行,但只用到一小部分列
表很“宽”,即表中包含大量的列
查询频率相对较低(通常每台服务器每秒查询数百次或更少)
对于简单查询,允许大约50毫秒的延迟
列的值是比较小的数值和短字符串(例如,每个URL只有60个字节)
在处理单个查询时需要高吞吐量(每台服务器每秒高达数十亿行)
不需要事务
数据一致性要求较低
每次查询中只会查询一个大表。除了一个大表,其余都是小表
查询结果显著小于数据源。即数据有过滤或聚合。返回结果不超过单个服务器内存大小
