




ClickHouse简介
ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)。
架构
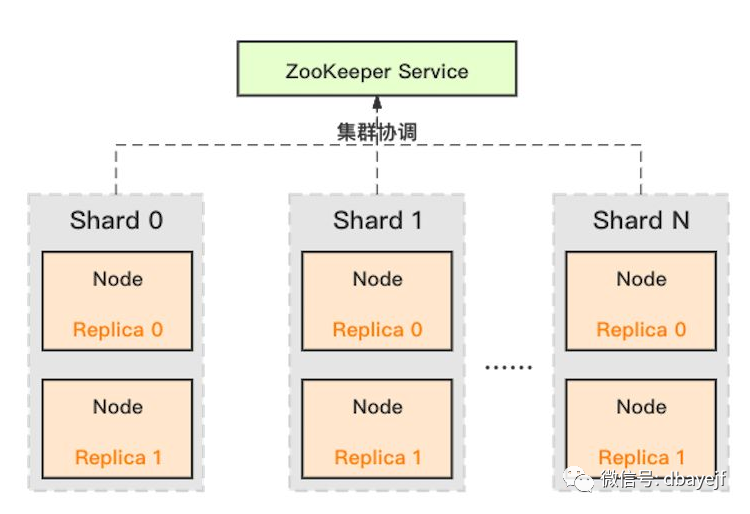
主要特性
真正的列式数据库管理系统
多主架构
数据列式压缩存储
多线程并发和分布式处理
向量化引擎
支持SQL
适合在线查询
角色访问控制
限制
没有完整的事务支持
缺少高频率,低延迟的修改或删除已存在数据的能力。仅能用于批量删除或修改数据
稀疏索引使得ClickHouse不适合通过其键检索单行的点查询
管理与运维
用户配置
20版本之前用户配置只能通过xml文件来管理,之后版本可以通过SQL方式来设置RBAC权限控制,推荐使用。
clickhouse自带default用户,但是该用户拥有所有权限且没有设置登陆密码和开启RBAC
配置管理员帐号和RBAC权限控制
users.xml
配置添加
<users>
<admin> ## clickhouse自带default用户,但是该用户拥有所有权限且没有设置登陆密码和开启RBAC
<password>pwd</password>
<access_management>1</access_management>
<networks incl="networks" replace="replace">
<ip>::/0</ip>
</networks>
<profile>default</profile>
<quota>default</quota>
</admin>
</users>
access_management 默认为0,设置为1标识开启RBAC权限控制,使用SQL来管理用户
admin 配置的用户名
password 用户对应的密码
或者SHA256 哈希分配密码(修改了密码认证方式需要重启服务生效)
[root@dn2 ~]# echo -n "pwd" | sha256sum | tr -d '-'
a1159e9df3670d549d04524532629f5477ceb7deec9b45e47e8c009506ecb2c8
修改 users.xml
<!-- <password>pwd</password> -->
<password_sha256_hex>a1159e9df3670d549d04524532629f5477ceb7deec9b45e47e8c009506ecb2c8</password_sha256_hex>networks 运行访问的客户端ip、host
profile clickhouse角色
quota 配额,分配给该用户的资源
确认config.xml以下配置有开启
## 用来存储创建的用户和角色
<access_control_path>/var/lib/clickhouse/access/</access_control_path>
此配置必须有 否则会报:DB::Exception: Not found a storage to insert user,重启后生效
创建普通用户
查看创建用户语句
SHOW CREATE USER
┌─CREATE USER───────────────────────────────────────────────────────────────────┐
│ CREATE USER admin IDENTIFIED WITH plaintext_password SETTINGS PROFILE default │
└───────────────────────────────────────────────────────────────────────────────┘
使用刚才创建具有RBAC权限控制的管理员用户admin登陆,使用SQL来管理用户
dn1 :) CREATE USER u1 HOST IP '127.0.0.1' IDENTIFIED WITH PLAINTEXT_PASSWORD BY '123' DEFAULT ROLE ALL ;
CREATE USER u1 IDENTIFIED WITH plaintext_password BY '123' HOST LOCAL DEFAULT ROLE ALL
Ok.
0 rows in set. Elapsed: 0.001 sec.
dn1 :) show users;
SHOW USERS
┌─name────┐
│ admin │
│ default │
│ test │
│ u1 │
└─────────┘
查看创建用户的配置文件
[root@dn1 access]# cat /var/lib/clickhouse/access/9545470b-351f-e7e4-6e49-ab05592f1d87.sql
ATTACH USER u1 IDENTIFIED WITH plaintext_password BY '123' HOST LOCAL;
[root@dn1 access]# cat 0b41a120-656c-11c1-5fad-e1acc271c19e.sql
ATTACH USER u2 IDENTIFIED WITH plaintext_password BY '123';
创建用户并不限制ip登陆
dn1 :) CREATE USER u2 HOST IP '0.0.0.0/0' IDENTIFIED WITH PLAINTEXT_PASSWORD BY '123';
修改用户的连接ip限制
dn1 :) alter USER u2 HOST IP '127.0.0.1';
修改用户密码
alter USER u2 HOST IP '0.0.0.0/0' IDENTIFIED WITH PLAINTEXT_PASSWORD BY '111';
各分片上创建用户
dn1 :) CREATE USER u2 HOST IP '0.0.0.0/0' IDENTIFIED WITH PLAINTEXT_PASSWORD BY '123' ON CLUSTER cluster_shard3_replica1;
权限管理
角色是权限的集合,用来定义用户行使权限的范围。
示例
创建角色并给角色对应权限
CREATE ROLE r_read_all SETTINGS max_memory_usage = 5000000 READONLY ON CLUSTER cluster_shard3_replica1;
GRANT create database ON *.* to r_read_all;
GRANT create table ON *.* to r_read_all;
GRANT drop table ON *.* to r_read_all;
创建用户,并把前面创建的角色权限赋权用户
CREATE USER u2 HOST IP '0.0.0.0/0' IDENTIFIED WITH PLAINTEXT_PASSWORD BY '123' ON CLUSTER cluster_shard3_replica1 ;
grant r_read_all to u2;
-- revoke r_read_all from u2;
或者
CREATE USER u2 HOST IP '0.0.0.0/0' IDENTIFIED WITH PLAINTEXT_PASSWORD BY '123' default role r_read_all ON CLUSTER cluster_shard3_replica1 ;
使用u2用户登陆,没有赋权角色权限时,show databases看不到数据库,赋权后就可以看到了
dn1 :) show databases;
SHOW DATABASES
Ok.
0 rows in set. Elapsed: 0.009 sec.
dn1 :) show databases;
SHOW DATABASES
┌─name───────────────────────────┐
│ _temporary_and_external_tables │
│ default │
│ system │
│ temp │
└────────────────────────────────┘
表权限例子
grant all on edw.* to ototest on cluster default_cluster;
revoke all on edw.* from ototest on cluster default_cluster;
服务监控
集群状态监控
没有找到监控的命令,思路是监控每个分片的连接是否正常
以及几个集群系统相关的日志表
select * from system.metrics limit 5
select * from system.events limit 5
select * from system.asynchronous_metrics limit 5
查看集群配置
select * from system.clusters;
cluster
( String ) — 集群名称。shard_num
( UInt32 ) — 集群中的分片编号,从 1 开始。shard_weight
( UInt32 ) — 写入数据时分片的相对权重。replica_num
( UInt32 ) — 分片中的副本编号,从 1 开始。host_name
( String ) — 配置中指定的主机名。host_address
( String ) — 从 DNS 获得的主机 IP 地址。port
( UInt16 ) — 用于连接到服务器的端口。is_local
( UInt8 ) — 指示主机是否为本地的标志。user
( String ) — 用于连接到服务器的用户名。default_database
( String ) — 默认数据库名称。errors_count
( UInt32 ) — 此主机无法到达副本的次数。slowdowns_count
( UInt32 ) — 与对冲请求建立连接时导致更改副本的速度减慢次数。estimated_recovery_time
( UInt32 ) — 在副本错误计数归零并被视为恢复正常之前剩余的秒数。
日志查询
线程的执行查询的信息
select * from system.query_thread_log
order by event_time DESC;
select * from system.query_log
order by event_time DESC ;
杀查询进程
找到对应的会话
select
query_id,read_rows,total_rows_approx,memory_usage,
initial_user,initial_address,elapsed,query
from system.processes
order by read_rows desc;
# 字段含义
# query_id 查询id,
# read_rows 从表中读取的行数,
# total_rows_approx 应读取的行总数的近似值,
# memory_usage 请求使用的内存量
# initial_user 进行查询的用户
# initial_address 请求的 IP 地址
# elapsed 求执行开始以来的秒数
# query 查询语句
或者
SHOW PROCESSLIST
进行kil操作
kill query where query_id='d03438bf-cd25-48fe-a4fd-e3e2c72eff2e'
数据备份
目前Clickhouse的备份方式有以下几种:
文本文件导入导出
ALTER TABLE…FREEZE
备份工具Clickhouse-Backup
文本文件导入导出
导出到csv文件
clickhouse-client -h 127.0.0.1 -u admin --password pwd --query="select * from default.user_cluster FORMAT CSV" > tmp.csv
[root@dn1 ~]# wc -l tmp.csv
12 tmp.csv
从CSV文件导入
-- 创建简单的内存引擎表
create table default.tmp engine=Memory as select * from default.user_cluster where 1=2 ;
-- 把csv文件导入
[root@dn1 ~]# cat tmp.csv |clickhouse-client -h 127.0.0.1 -u admin --password pwd --query="insert into default.tmp(id,name) FORMAT CSV"
[root@dn1 ~]# clickhouse-client -h 127.0.0.1 -u admin --password pwd --query="select count(*) from default.tmp"
12
模拟错误数据导入,查看返回值是非0
[root@dn1 ~]# echo "1,2,3" >tmp2.csv
[root@dn1 ~]# cat tmp2.csv |clickhouse-client -h 127.0.0.1 -u admin --password pwd --query="insert into default.tmp(id,name) FORMAT CSV"
Code: 117. DB::Exception: Expected end of line: (at row 1)
Row 1:
Column 0, name: id, type: Int32, parsed text: "1"
Column 1, name: name, type: String, parsed text: "2"
ERROR: There is no line feed. "3" found instead.
It's like your file has more columns than expected.
And if your file have right number of columns, maybe it have unquoted string value with comma.
[root@dn1 ~]# echo $?
117
ALTER TABLE…FREEZE
不支持复制表
freeze的备份本质上是通过对原始目录文件进行硬链接实现的,所以不会导致额外的空间存储上涨。
语法
ALTER TABLE table_name FREEZE [PARTITION partition_expr]
该操作为指定分区创建一个本地备份。如果 PARTITION 语句省略,该操作会一次性为所有分区创建备份。整个备份过程不需要停止服务
备份
echo -n 'alter table default.user_local freeze' | clickhouse-client -h 127.0.0.1 -u admin --password pwd
[root@dn1 user_local]# ll /var/lib/clickhouse/shadow/1/data/default/
total 0
drwxr-x---. 8 clickhouse clickhouse 99 Nov 12 17:11 user_local
内存表和分布式表不支持
FREEZE PARTITION 只复制数据, 数据默认保存在/var/lib/clickhouse/shadow,shadow目录下的N是一个自增长的整数,表示freeze执行的次数。
不备份元数据,元数据默认在文件 var/lib/clickhouse/metadata/database/table.sql
可将备份出来的文件保存到其它地方
恢复
创建表
CREATE TABLE default.user_tmp
(
id Int32,
name String
)
ENGINE = MergeTree()
PARTITION BY id
PRIMARY KEY id
ORDER BY id;
-- select data_paths from `system`.tables t where database ='default' and name='user_tmp'
['/var/lib/clickhouse/data/default/user_tmp/']
恢复目录数据
[root@dn1 user_local]# cp -r /var/lib/clickhouse/shadow/1/data/default/user_local/* /var/lib/clickhouse/data/default/user_tmp/
[root@dn1 user_tmp]# chown -R clickhouse:clickhouse /var/lib/clickhouse/data/default/user_tmp
重新装载数据
DETACH table default.user_tmp
attach table default.user_tmp
分区表语法:alter table tbattachpartitionpar;
REMOTE
使用remote从集群节点可以远程访问另外一个集群节点,把数据备份到本地
insert into test.xxx select * from remote('192.168.x.x', schema.table,'default','password') ;
Clickhouse-Backup
下载地址
https://github.com/AlexAkulov/clickhouse-backup
下载编译好的包
解压使用
[root@nna ck]# tar -zxvf clickhouse-backup.tar.gz
[root@nna clickhouse-backup]# ll
total 36540
-rwxr-xr-x. 1 hadoop 121 37410707 Oct 25 00:43 clickhouse-backup
-rw-r--r--. 1 hadoop 121 1961 Oct 25 00:43 config.yml
使用帮助
[root@nna clickhouse-backup]# /opt/ck/clickhouse-backup/clickhouse-backup --help
NAME:
clickhouse-backup - Tool for easy backup of ClickHouse with cloud support
USAGE:
clickhouse-backup <command> [-t, --tables=<db>.<table>] <backup_name>
VERSION:
1.2.0
DESCRIPTION:
Run as 'root' or 'clickhouse' user
COMMANDS:
tables Print list of tables
create Create new backup
create_remote Create and upload
upload Upload backup to remote storage
list Print list of backups
download Download backup from remote storage
restore Create schema and restore data from backup
restore_remote Download and restore
delete Delete specific backup
default-config Print default config
server Run API server
help, h Shows a list of commands or help for one command
GLOBAL OPTIONS:
--config FILE, -c FILE Config FILE name. (default: "/etc/clickhouse-backup/config.yml") [$CLICKHOUSE_BACKUP_CONFIG]
--help, -h show help
--version, -v print the version
从使用帮助可以看到默认的配置文件是/etc/clickhouse-backup/config.yml
编译配置文件
# /etc/clickhouse-backup/config.yml
general:
remote_storage: none
max_file_size: 107374182400
disable_progress_bar: true
backups_to_keep_local: 0
backups_to_keep_remote: 0
log_level: info
allow_empty_backups: false
download_concurrency: 1
upload_concurrency: 1
clickhouse:
username: default
password: "test123"
host: localhost
port: 9000
disk_mapping: {}
skip_tables:
- system.*
timeout: 5m
freeze_by_part: false
secure: false
skip_verify: false
sync_replicated_tables: false
log_sql_queries: false
config_dir: /etc/clickhouse-server/
restart_command: systemctl restart clickhouse-server
debug: false
如果需要全配置运行命令 clickhouse-backup default-config输出
显示备份的表
[root@nna clickhouse-backup]# ./clickhouse-backup tables
default.test 0B default
default.user_cluster 0B default
default.user_local 1.03KiB default
创建备份
[root@nna clickhouse-backup]# ./clickhouse-backup create
2021/11/15 14:27:22 info done backup=2021-11-15T06-27-22 operation=create table=default.test
2021/11/15 14:27:22 info done backup=2021-11-15T06-27-22 operation=create table=default.user_cluster
2021/11/15 14:27:22 info done backup=2021-11-15T06-27-22 operation=create table=default.user_local
2021/11/15 14:27:22 info done backup=2021-11-15T06-27-22 duration=64ms operation=create
查看备份
[root@nna clickhouse-backup]# ./clickhouse-backup list
2021-11-15T06-27-22 2.04KiB 15/11/2021 06:27:22 local
注意,出于性能原因,本地备份不计算“大小”。
备份存储在中
/var/lib/clickhouse/backup/BACKUPNAME
。备份名称默认为时间戳,但是您可以选择使用–name标志指定备份名称。备份包含两个目录:一个“元数据”目录,其中包含重新创建架构所需的DDL SQL语句;以及一个“影子”目录,其中包含作为ALTER TABLE ... FREEZE
操作结果的数据
恢复备份
查看数据及删除表
SELECT *
FROM user_local
ORDER BY id ASC
┌─id─┬─name─┐
│ 2 │ b │
└────┴──────┘
┌─id─┬─name─┐
│ 4 │ d │
└────┴──────┘
┌─id─┬─name─┐
│ 6 │ f │
└────┴──────┘
┌─id─┬─name─┐
│ 22 │ b │
└────┴──────┘
┌─id─┬─name─┐
│ 44 │ d │
└────┴──────┘
┌─id─┬─name─┐
│ 66 │ f │
└────┴──────┘
6 rows in set. Elapsed: 0.008 sec.
nna :) drop table user_local;
DROP TABLE user_local
Ok.
0 rows in set. Elapsed: 0.003 sec.
nna :) select * from user_local order by id ;
SELECT *
FROM user_local
ORDER BY id ASC
Received exception from server (version 20.8.3):
Code: 60. DB::Exception: Received from 127.0.0.1:9000. DB::Exception: Table default.user_local doesn't exist..
0 rows in set. Elapsed: 0.096 sec.
从备份数据中恢复,验证数据恢复成功
[root@nna clickhouse-backup]# ./clickhouse-backup restore --table default.user_local 2021-11-15T06-27-22
2021/11/15 14:39:49 info done backup=2021-11-15T06-27-22 operation=restore table=default.user_local
2021/11/15 14:39:49 info done backup=2021-11-15T06-27-22 duration=39ms operation=restore
2021/11/15 14:39:49 info done backup=2021-11-15T06-27-22 operation=restore
SELECT count(*)
FROM user_local
┌─count()─┐
│ 6 │
└─────────┘
数据库引擎
默认情况下,ClickHouse使用Atomic
数据库引擎。它提供了可配置的表引擎
和SQL语法
其它的数据库引擎还有:
MySQL
MaterializeMySQL
Lazy
Atomic
PostgreSQL
MaterializedPostgreSQL
Replicated
Atomic和Ordinary区别:
SELECT
name,
engine,
metadata_path
FROM system.databases AS d
WHERE name IN ('test', 'test1')
Query id: 67e8d895-2ab2-44d8-960d-73204b1979dd
┌─name──┬─engine───┬─metadata_path────────────────────────────────────────────────────┐
│ test │ Atomic │ /data/clickhouse/store/4e6/4e6c2ebe-d137-419b-be6f-c0f3579ff310/ │
│ test1 │ Ordinary │ /data/clickhouse/metadata/test1/ │
[root@ck03 data]# ll test
total 0
lrwxrwxrwx. 1 clickhouse clickhouse 63 Dec 16 17:32 ds_cmh_sales -> /data/clickhouse/store/853/85301653-a51c-4275-b943-7bc59e35810a
lrwxrwxrwx. 1 clickhouse clickhouse 63 Dec 16 16:58 ds_cmh_sales1 -> /data/clickhouse/store/9de/9de4e5cb-e109-4b87-840e-094107b4be91
[root@ck03 data]#
[root@ck03 data]# ll test1
total 0
drwxr-x---. 3 clickhouse clickhouse 48 Dec 27 18:02 tmp
Atomic引擎生成的表会指向uuid,Ordinary生成的表就是表目录
常用表引擎
表引擎(即表的类型)决定了:
数据的存储方式和位置,写到哪里以及从哪里读取数据
支持哪些查询以及如何支持。
并发数据访问。
索引的使用(如果存在)。
是否可以执行多线程请求。
数据复制参数。
合并树家族
MergeTree
主要特点:
存储的数据按主键排序。这使得您能够创建一个小型的稀疏索引来加快数据检索。
如果指定了 分区键 的话,可以使用分区。
在相同数据集和相同结果集的情况下 ClickHouse 中某些带分区的操作会比普通操作更快。查询中指定了分区键时 ClickHouse 会自动截取分区数据。这也有效增加了查询性能。
支持数据副本。
ReplicatedMergeTree
系列的表提供了数据副本功能。支持数据采样。需要的话,您可以给表设置一个采样方法。
创建表语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...]
[SETTINGS name=value, ...]
ReplacingMergeTree
该引擎和 MergeTree 的不同之处在于它会删除排序键值相同的重复项。
数据的去重只会在数据合并期间进行。合并会在后台一个不确定的时间进行,因此你无法预先作出计划。有一些数据可能仍未被处理。尽管你可以调用 OPTIMIZE
语句发起计划外的合并,但请不要依靠它,因为 OPTIMIZE
语句会引发对数据的大量读写。
因此,ReplacingMergeTree
适用于在后台清除重复的数据以节省空间,但是它不保证没有重复的数据出现。
建表语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = ReplacingMergeTree([ver])
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
ReplacingMergeTree 的参数
ver
— 版本列。类型为UInt*
,Date
或DateTime
。可选参数。在数据合并的时候,
ReplacingMergeTree
从所有具有相同排序键的行中选择一行留下:如果
ver
列未指定,保留最后一条。如果
ver
列已指定,保留ver
值最大的版本。
SummingMergeTree
该引擎继承自 MergeTree。区别在于,当合并 SummingMergeTree
表的数据片段时,ClickHouse 会把所有具有相同主键的行合并为一行,该行包含了被合并的行中具有数值数据类型的列的汇总值。如果主键的组合方式使得单个键值对应于大量的行,则可以显著的减少存储空间并加快数据查询的速度。
建表语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = SummingMergeTree([columns])
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
SummingMergeTree 的参数
columns ,包含了将要被汇总的列的列名的元组。可选参数。所选的列必须是数值类型,并且不可位于主键中。
如果没有指定
columns
,ClickHouse 会把所有不在主键中的数值类型的列都进行汇总。
使用示例
CREATE TABLE summtt
(
key UInt32,
value UInt32
)
ENGINE = SummingMergeTree()
ORDER BY key;
INSERT INTO summtt Values(1,1),(1,2),(2,1)
查看表数据
dn1 :) select * from summtt ;
SELECT *
FROM summtt
Query id: b3c71148-7c7f-4fd5-bb62-d09a463c4827
┌─key─┬─value─┐
│ 1 │ 3 │
│ 2 │ 1 │
└─────┴───────┘
发现已经汇总过,但只是按数据段汇总,因为数据量少所以看不出,实际要看汇总还得要用语句查询
SELECT key, sum(value) FROM summtt GROUP BY key;
执行optimize会强制触发聚合
optimize table tablename;
AggregatingMergeTree
该引擎继承自 MergeTree,并改变了数据片段的合并逻辑。ClickHouse 会将一个数据片段内所有具有相同主键(准确的说是 排序键)的行替换成一行,这一行会存储一系列聚合函数的状态。
聚合物化视图的示例
CREATE MATERIALIZED VIEW test.basic
ENGINE = AggregatingMergeTree() PARTITION BY toYYYYMM(StartDate) ORDER BY (CounterID, StartDate)
AS SELECT
CounterID,
StartDate,
sumState(Sign) AS Visits,
uniqState(UserID) AS Users
FROM test.visits
GROUP BY CounterID, StartDate;
CollapsingMergeTree
该引擎继承于 MergeTree,并在数据块合并算法中添加了折叠行的逻辑,仅支持单串行并发
建表语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = CollapsingMergeTree(sign)
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
CollapsingMergeTree 参数
sign
— 类型列的名称:1
是«状态»行,-1
是«取消»行。列数据类型 —Int8
。
该引擎提出一个折叠行的概念,使用sign来标识。个人理解是,对于不断变化的表,因为做update或delete的操作很慢,所以把这两种操作类型换成insert,用sign等于-1来标识,后台进行异步的折叠合并
使用示例
CREATE TABLE UAct
(
UserID UInt64,
PageViews UInt8,
Duration UInt8,
Sign Int8
)
ENGINE = CollapsingMergeTree(Sign)
ORDER BY UserID;
INSERT INTO UAct VALUES (4324182021466249494, 5, 146, 1);
INSERT INTO UAct VALUES (4324182021466249494, 5, 146, -1),(4324182021466249494, 6, 185, 1);
dn1 :) select * from UAct;
┌──────────────UserID─┬─PageViews─┬─Duration─┬─Sign─┐
│ 4324182021466249494 │ 5 │ 146 │ 1 │
└─────────────────────┴───────────┴──────────┴──────┘
┌──────────────UserID─┬─PageViews─┬─Duration─┬─Sign─┐
│ 4324182021466249494 │ 5 │ 146 │ -1 │
│ 4324182021466249494 │ 6 │ 185 │ 1 │
└─────────────────────┴───────────┴──────────┴──────┘
我们可以使用聚合函数来提前查看折叠后的数据
SELECT
UserID,
sum(PageViews * Sign) AS PageViews,
sum(Duration * Sign) AS Duration
FROM UAct
GROUP BY UserID
HAVING sum(Sign) > 0;
或者使用FINAL来进行折叠,但这种查询数据的方法是非常低效的
SELECT * FROM UAct FINAL;
VersionedCollapsingMergeTree
引擎继承自 MergeTree 并将折叠行的逻辑添加到合并数据部分的算法中。VersionedCollapsingMergeTree
用于相同的目的 折叠树 但使用不同的折叠算法,允许以多个线程的任何顺序插入数据。特别是, Version
列有助于正确折叠行,即使它们以错误的顺序插入。相比之下, CollapsingMergeTree
只允许严格连续插入。
允许快速写入不断变化的对象状态。
删除后台中的旧对象状态。这显着降低了存储体积。
这个引擎跟CollapsingMergeTree 原理差不多,但允许以多个线程的任何顺序插入
使用示例
CREATE TABLE UAct2
(
UserID UInt64,
PageViews UInt8,
Duration UInt8,
Sign Int8,
Version UInt8
)
ENGINE = VersionedCollapsingMergeTree(Sign, Version)
ORDER BY UserID
INSERT INTO UAct2 VALUES (4324182021466249494, 5, 146, 1, 1);
INSERT INTO UAct VALUES (4324182021466249494, 5, 146, -1, 1),(4324182021466249494, 6, 185, 1, 2);
select * from UAct2 ;
┌──────────────UserID─┬─PageViews─┬─Duration─┬─Sign─┬─Version─┐
│ 4324182021466249494 │ 5 │ 146 │ 1 │ 1 │
└─────────────────────┴───────────┴──────────┴──────┴─────────┘
自定义分区键
MergeTree 系列的表(包括 可复制表 )可以使用分区。基于 MergeTree 表的 物化视图 也支持分区。
通过 PARTITION BY expr
子句指定的。分区键可以是表中列的任意表达式。例如,指定按月分区,表达式为 toYYYYMM(date_column)
:
CREATE TABLE visits
(
VisitDate Date,
Hour UInt8,
ClientID UUID
)
ENGINE = MergeTree()
PARTITION BY toYYYYMM(VisitDate)
ORDER BY Hour;
分区键也可以是表达式元组(类似 主键 )。例如:
ENGINE = ReplicatedCollapsingMergeTree('/clickhouse/tables/name', 'replica1', Sign)
PARTITION BY (toMonday(StartDate), EventType)
ORDER BY (CounterID, StartDate, intHash32(UserID));
数据副本
只有 MergeTree 系列里的表可支持副本:
ReplicatedMergeTree
ReplicatedSummingMergeTree
ReplicatedReplacingMergeTree
ReplicatedAggregatingMergeTree
ReplicatedCollapsingMergeTree
ReplicatedVersionedCollapsingMergetree
ReplicatedGraphiteMergeTree
要使用副本,需在配置文件中设置 ZooKeeper 集群的地址。例如:
<zookeeper>
<node index="1">
<host>example1</host>
<port>2181</port>
</node>
<node index="2">
<host>example2</host>
<port>2181</port>
</node>
<node index="3">
<host>example3</host>
<port>2181</port>
</node>
</zookeeper>
创建复制表
在表引擎名称上加上 Replicated
前缀。例如:ReplicatedMergeTree
。
Replicated*MergeTree 参数
zoo_path
— ZooKeeper 中该表的路径。replica_name
— ZooKeeper 中的该表的副本名称。
示例:
CREATE TABLE table_name
(
EventDate DateTime,
CounterID UInt32,
UserID UInt32
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{layer}-{shard}/table_name', '{replica}')
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID))
SAMPLE BY intHash32(UserID)
如上例所示,这些参数可以包含宏替换的占位符,即大括号的部分。它们会被替换为配置文件里 ‘macros’ 那部分配置的值。示例:
<macros>
<layer>05</layer>
<shard>02</shard>
<replica>example05-02-1.yandex.ru</replica>
</macros>
复制表使用中的常见问题
如果服务器启动时 ZooKeeper 不可用,则复制表会切换为只读模式。系统会定期尝试去连接 ZooKeeper。
如果系统检测到损坏的数据片段(文件大小错误)或无法识别的片段(写入文件系统但未记录在 ZooKeeper 中的部分),则会把它们移动到 ‘detached’ 子目录(不会删除)。
如果本地数据集与预期数据的差异太大,则会触发安全机制,导致启动失败
节点数据丢失后恢复
在服务器上安装 ClickHouse。在包含分片标识符和副本的配置文件中正确定义宏配置
非复制表则必须手动复制
从副本服务器上中复制位于
/var/lib/clickhouse/metadata/
中的表定义信息开始恢复复制表数据
ZooKeeper 中创建节点
/path_to_table/replica_name/flags/force_restore_data
,节点内容不限或运行命令来恢复所有复制的表:
sudo -u clickhouse touch var/lib/clickhouse/flags/force_restore_data
MergeTree 转换为 ReplicatedMergeTree
重命名现有的 MergeTree 表,然后使用旧名称创建
ReplicatedMergeTree
表将数据从旧表移动到新表(
/var/lib/clickhouse/data/db_name/table_name/
)目录内的 ‘detached’ 目录中然后在其中一个副本上运行
ALTER TABLE ATTACH PARTITION
,将这些数据片段添加到工作集中
ReplicatedMergeTree 转换为 MergeTree
使用其他名称创建 MergeTree 表
将具有
ReplicatedMergeTree
表数据的目录中的所有数据移动到新表的数据目录中然后删除
ReplicatedMergeTree
表并重新启动服务器如果你想在不启动服务器的情况下清除
ReplicatedMergeTree
表:删除元数据目录中的相应
.sql
文件(/var/lib/clickhouse/metadata/
)删除 ZooKeeper 中的相应路径(
/path_to_table/replica_name
)
ZooKeeper 集群中的元数据丢失或损坏时
1、通过将数据转移到非复制表来保存数据
分布式引擎
分布式引擎本身不存储数据, 但可以在多个服务器上进行分布式查询。
读是自动并行的。读取时,远程服务器表的索引(如果有的话)会被使用。
分布式引擎参数:1、服务器配置文件中的集群名,2、远程数据库名,3、远程表名,4、数据分片键(或者使用rand()随机策略)。
建表示例
CREATE TABLE user_all ON CLUSTER default_cluster
(
`id` Int32,
`name` String
)
ENGINE = Distributed(default_cluster, default, user_local, id)
将会从位于«logs»集群中 default.hits 表所有服务器上读取数据。
数据库名参数除了用数据库名之外,也可用返回字符串的常量表达式。例如:currentDatabase()
向集群写数据的两种方法
自已指定要将哪些数据写入哪些服务器,并直接在每个分片上执行写入。换句话说,在分布式表上«查询»,在数据表上 INSERT。
在分布式表上执行 INSERT
在配置文件中定义权重,权重高的分片写入的数据会多
配置文件中
internal_replication
参数值的影响true:
复制表:写操作只选一个正常的副本写入数据,不副本复制工作交给复制表特性
非复制表:数据只插入到一个副本的本地表中,不会做同步,数据紊乱,不推荐使用
false
非复制表& 复制表:写操作会将数据写入所有副本。
实质上,这意味着要分布式表本身来复制数据。这种方式不如使用复制表的好,因为不会检查副本的一致性,并且随着时间的推移,副本数据可能会有些不一样
数据是异步写入的。对于分布式表的 INSERT,数据块只写本地文件系统。之后会尽快地在后台发送到远程服务器。
启用 max_parallel_replicas 选项后,会在分表的所有副本上并行查询处理
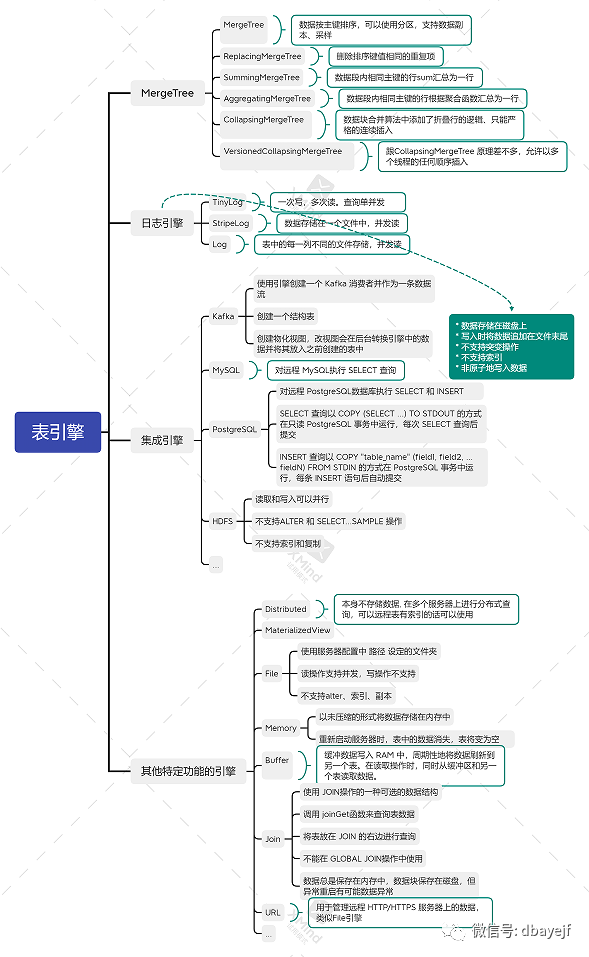
各种表引擎主要特性图
数据类型
创建表例子
drop table tmp;
create table tmp (
a character varying(255)
,b character varying
,c numeric(20,2)
,d text
,e bigint
)ENGINE = MergeTree()
ORDER BY a;
配置文件
服务的配置文件config.xml
用户的配置文件user.xml
用户及访问权限控制均可由配置文件直接进行标准化配置,一般由user.xml
文件设置
users.xml主要由以下三部分设置组成:
profile:类似于用户角色,可以实现最大内存、负载方式等配置的服用
users:设置包括用户名、密码、权限等
quotas:限制一段时间内的资源使用等
<?xml version="1.0"?>
<yandex>
<profiles>
<default>
<max_memory_usage>10000000000</max_memory_usage>
<load_balancing>random</load_balancing>
<constraints><!-- 配置约束-->
<max_memory_usage>
<min>5000000000</min>
<max>20000000000</max>
</max_memory_usage>
<load_balancing>
<readonly/>
</load_balancing>
</constraints>
</default>
</default>
<readonly>
<readonly>1</readonly>
</readonly>
</profiles>
<users>
<default>
<password></password>
<networks incl="networks" replace="replace">
<ip>::1</ip>
<ip>127.0.0.1</ip>
</networks>
<profile>default</profile>
<quota>default</quota>
</default>
<!--下面两个用户为测试用户,可以不配置-->
<seluser>
<password>meiyoumima</password>
<networks incl="networks" replace="replace">
<ip>::/0</ip>
</networks>
<profile>readonly</profile>
<quota>default</quota>
</seluser>
<inuser>
<password>meiyoumima</password>
<networks incl="networks" replace="replace">
<ip>::/0</ip>
</networks>
<profile>default</profile>
<quota>default</quota>
</inuser>
</users>
<!-- Quotas. -->
<quotas>
<default>
<interval>
<duration>3600</duration>
<queries>0</queries>
<errors>0</errors>
<result_rows>0</result_rows>
<read_rows>0</read_rows>
<execution_time>0</execution_time>
</interval>
</default>
</quotas>
</yandex>
profile设置详解
user.xml
用户配置文件中profiles
部分定义了一些可复用的配置,他的作用类似于用户角色,可定义多个profile,并为不同的profile定义不同的配置,其中每个参数的含义可参考前面的参考网页二,并在后续使用中不断完善,以下面配置为例:
<yandex>
<!--定义profiles-->
<profiles>
<!--可自定义名称,default是默认存在的角色名称-->
<default>
<max_memory_usage>10000000000</max_memory_usage>
<load_balancing>random</load_balancing>
<constraints><!-- 配置约束-->
<max_memory_usage>
<min>5000000000</min>
<max>20000000000</max>
</max_memory_usage>
<load_balancing>
<readonly/>
</load_balancing>
</constraints>
</default>
<!--自定义readonly角色-->
<readonly>
<readonly>1</readonly>
</readonly>
</profiles>
profile中有约束条件,从而限制其中的参数值被任意修改,约束条件有三种规则:
Min:最小值约束,对应参数取值不能小于该值
Max:最大值约束,对应参数取值不能大雨该值
Readonly:只读约束,对应参数禁止修改
profile中default的constraints配置约束会作为全局约束,自动被其他profile继承。
users配置详解
user.xml用户配置文件中users模块可以自定义配置用户属性,例如用户名、密码、权限等,用官网默认配置会发现user.xml文件中会默认创建default用户,使用clickhouse-client无参数登陆会通过该用户登陆,将以下面的示例进行说明:
<users>
<!--default用户会默认存在-->
<default>
<password></password>
<networks incl="networks" replace="replace">
<ip>::1</ip>
<ip>127.0.0.1</ip>
</networks>
<profile>default</profile>
<quota>default</quota>
</default>
<!--下面两个用户为测试用户,可以不配置-->
<seluser>
<password>meiyoumima</password>
<networks incl="networks" replace="replace">
<ip>::/0</ip>
</networks>
<profile>readonly</profile>
<quota>default</quota>
</seluser>
<inuser>
<password>meiyoumima</password>
<networks incl="networks" replace="replace">
<ip>::/0</ip>
</networks>
<profile>default</profile>
<quota>default</quota>
</inuser>
</users>
一个完整的用户设置,需要包含下面的属性
username:用户名
password:密码设置
登陆密码,clickhouse支持明文、SHA256加密、double_sha1三种设置方式,但SHA256和sha1都是散列算法,明文和密文一一对应,也可通过密文很容易进行解
明文登陆
<!--直接在用户中通过password标签定义,中间字符即为登陆密码-->
<password>meiyoumima</password>
<!--类似上述default用户,中间为空即代表没有密码-->
<password></password>SHA256加密登陆
## 官方推荐生成密码方式,RSZ4QZMc为随机的明文密码,21d076f...为最终密文
[root@xxxx docker_compose]# PASSWORD=
PASSWORD"; echo -n "不能识别此Latex公式:
(base64 < /dev/urandom | head -c8); echo "不能识别此Latex公式:
PASSWORD" | sha256sum | tr -d '-'
RSZ4QZMc
21d076f8340b5d836769a35c4d658d7b3091e7e1ccb18d66e9e1a7b6eef823df
### 也可通过openssl生成密文,明文为123,输出为密文
[root@xxxx docker_compose]# echo -n 123 | openssl dgst -sha256
(stdin)= a665a45920422f9d417e4867efdc4fb8a04a1f3fff1fa07e998e86f7f7a27ae3设置方式
<password_sha256_hex>21d076f8340b5d836769a35c4d658d7b3091e7e1ccb18d66e9e1a7b6eef823df</password_sha256_hex>double_sha1加密登陆# 官方推荐生成密码方式,+0agrMRX为urandom生成的明文,407732...为最终密文
[root@xxxx docker_compose]# PASSWORD=(base64 < dev/urandom | head -c8); echo "PASSWORD";echo¨E45En"PASSWORD" | sha1sum | tr -d '-' | xxd -r -p | sha1sum | tr -d '-' +0agrMRX 407732ce14cdea57dc0a2ff9c64773472f8cd666 ### 通过openssl生成密文,明文为123,输出为密文 [root@xxxx docker_compose]# echo -n 123 | openssl dgst -sha1 -binary | openssl dgst -sha1 (stdin)= 23ae809ddacaf96af0fd78ed04b6a265e05aa257设置方式
<password_double_sha1_hex>407732ce14cdea57dc0a2ff9c64773472f8cd666</password_double_sha1_hex>networks:网络设置,一般用来限制可登陆的客户端地址
networks表示允许被登陆clickhouse服务器的客户端列表,支持通过ip、host、host_regexp方式设置
ip设置
¨K81K
<ip>1.1.1.1</ip>
<ip>10.0.0.1/8</ip>
¨K82K
<ip>::/0</ip>
¨K83K
<ip>::1</ip>
<ip>127.0.0.1</ip>
host设置
<host>example1.host.com</host>
host_regexp设置
¨K84K
<host_regexp>^example\d\d-\d\d-\d\.host\.ru$</host_regexp>
profile
该用户所使用的profile设置,直接写入即可
<default>
<profile>default</profile>
</default>quota
该用户单位时间内的资源限制,直接使用quotas设置的名称即可
<quota>default</quota>database设置
该设置可以限制当前用户select时返回的行,以完成简单的行数据安全,示例如下:
<!--以下配置强制用户user1只能看到database_name.table1表中id为1000的行,其中filter支持UInt8类型的值,并支持比较和逻辑运算符-->
<user1>
<databases>
<database_name>
<table1>
<filter>id = 1000</filter>
</table1>
</database_name>
</databases>
</user1>
quotas属性详情
duration设置
duration表示累计的时间周期,单位为秒,达到该时间周期后,清除所有收集的值,接下来的周期,将重新开始计算,当服务重启时,也会清除所有的值,重新开始新的周期。
<duration>3600</duration>
queris设置
queris表示在该周期内,允许执行的查询次数,0为不限制。
<!--在duration设置周期时间内只允许查询1000次-->
<queries>1000</queries>
errors设置
errors表示在该周期内,允许引发异常的查询次数,0为不限制。
<errors>0</errors>
result_rows设置
result_rows表示在周期内,允许查询返回的结果行数,0为不限制。
<result_rows>0</result_rows>
read_rows设置
read_rows表示在周期内,允许远程节点读取的数据行数,0为不限制。
<read_rows>0</read_rows>
execution_time设置
execution_time表示允许查询的总执行时间(又叫wall time),单位为秒,0为不限制。
<execution_time>0</execution_time>
常用命令
连接集群
clickhouse-client -h 192.168.43.130 --port 9000 -u default --password test123
常用查询
查看版本
select version()
查看当前用户
select user();
查看当前进程
SELECT
user,
query_id,
read_rows,
total_rows_approx,
memory_usage,
initial_user,
initial_address,
elapsed,
query,
client_hostname
FROM system.processes
order by elapsed ;
或者
show processlist;
查看内存使用
SELECT
metric,
formatReadableSize(value)
FROM system.metrics
WHERE metric = 'MemoryTracking'
使用技巧
把查询结果转成列显示
SELECT * FROM system.clusters LIMIT 2 FORMAT Vertical;
Row 1:
──────
cluster: cluster_shard3_replica1
shard_num: 1
shard_weight: 1
replica_num: 1
host_name: dn1
host_address: 192.168.43.130
port: 9000
is_local: 1
user: default
default_database:
errors_count: 0
estimated_recovery_time: 0
Row 2:
──────
cluster: cluster_shard3_replica1
shard_num: 1
shard_weight: 1
replica_num: 2
host_name: nna
host_address: 192.168.43.128
port: 9000
is_local: 0
user: default
default_database:
errors_count: 0
estimated_recovery_time: 0
分布式建表
CREATE TABLE IF NOT EXISTS user_local on cluster default_cluster
(`id` Int32,`name` String)
ENGINE = MergeTree()
PARTITION BY id
PRIMARY KEY id
ORDER BY id;
分布式赋权
grant select on _fd_data to ototest on cluster default_cluster;
马上删除表数据
在ck上删除表数据是异步执行的,即你提交了删除操作,数据是一点点减少
alter table month_sales_local on cluster default_cluster delete where period='202111' ;
如果需要马上对源数据进行删除,需要运行以下命令,但注意会占用较多资源,特别是删除一个大表的时候,因为它还要对数据进行去重以及合并分区
optimize table _month_sales_local on cluster default_cluster final
这时再查看是删除后的真正数据量,但后面目存储还未完全删除,ck会有一段时间后自动删除过期的数据目录
clickhouse-client客户端输入时支持换行
启动时加入 -m 参数
clickhouse-client -m
create table as例子
drop table default.copy_test1_local on cluster default_cluster;
create table default.copy_test1_local on cluster default_cluster
as dm.oto_month_sales_local ;
drop table default.copy_test1_all on cluster default_cluster;
create table default.copy_test1_all on cluster default_cluster
as dm.oto_month_sales_all
ENGINE = Distributed('default_cluster', 'default', 'copy_test1_local', rand());
insert into default.copy_test1_all select * from dm.oto_month_sales_all limit 1000000;
select count(*) from default.copy_test1_all; --1000000
