




PG Phriday:稳定存储踩踏
在调整数据库存储大小时,我们并不总是考虑每秒操作数等性能指标。这样做的直接后果可能是我们无法达到我们所寻求的性能。然而,这里还有一个更隐蔽的副作用,它深埋在操作系统本身的内部:内存刷新。
在 SSD 和 NVMe 设备可以从所有云提供商处获得并且价格合理的裸机服务器的时代,很容易忘记写入缓存的影响。毕竟,这些设备每秒可以轻松吸收数万次操作!无需将数据刷新到中间存储控制器缓存,我们可以有效地直接写入设备本身,因为它非常快。
但是,当我们的 SSD 或 NVMe 设备不堪重负时,实际会发生什么呢?对于如此高性能的设备,这甚至可能吗?
一点背景
在 EDB 执行与内部项目相关的一些基准测试时,我们注意到一些特别奇怪的行为。在基准测试的前几分钟,性能实际上仍然相当不起眼,然后突然从悬崖上掉下来,永远不会恢复。pgbench 上的平均 TPS 不是 1700,而是 800。
在这些情况下让我们感到困惑的是,我们没有在本地数据中心的裸机硬件上观察到相同的行为。相反,吞吐量的不稳定下降发生在一小群 Amazon c5ad.4xlarge实例上,具有明显的规律性。即使是亚马逊性能相对较低的通用卷也配备了与 SSD 等效的硬件,从 1500 IOPS 开始分配 500GB。
那么,为什么像 pgbench 这样的标准 Postgres 基准测试会提供相当好的性能,但很快就会出现一些不那么美味的东西呢?大多数情况下,与 SSD 不同的是,服务器硬盘驱动器通常隐藏在配备高级 RAID 和缓存功能的复杂存储控制器后面。一段时间以来,我们已经知道传统硬盘的性能受到严重影响,这与它们的几何形状和物理限制有关。为了减轻这种影响,这些磁盘控制器可能会提供几 GB 的 RAM 来缓冲对古老的 spin rust 技术的写入。
另一方面,SSD 并不总是装备精良。它们是如此之快,我们几乎都忘记了控制器级别的写入缓存的概念,只是简单地用写入来爆破设备,无论它是否能够吸收它们。通常,SSD 承载缓存的最大程度是一些微不足道的超级电容器支持的内存芯片,纯粹是为了克服NAND 闪存单元固有的写入放大效应。这仅保护正在进行中且尚未提交到实际内存单元的写入,让所有未决的操作系统级写入刷新自行解决。
考虑到这些知识,我们决定看看 AWS EBS 存储在各种 Postgres 工作负载上的表现如何。
初步印象
我们从引起我们兴趣的硬件开始:配备 500GB EBS gp2 的 c5ad.4xlarge EC2 实例,默认分配 1500 IOPS,具有高达 3000 IOPS 的突发性能。对于初学者,c5ad.4xlarge 提供 16 个 AMD EPYC CPU 线程和 32GB 的 RAM。然后,我们包含了一个专用的 c5.xlarge(4 个 CPU,8GB RAM)驱动程序系统,以将基准测试软件与正在测试的实例分离。
我们使用 10,000 规模的 pgbench 数据库引导这些系统,相当于大约 150GB 的数据,并使用 32 个并发客户端运行所有测试。为了尽可能地隔离,我们将max_wal_size增加到 32GB 以防止在测试中间出现检查点,并将checkpoint_timeout增加到 15 分钟,这样我们的 500 秒测试可以不受干扰地运行。我们还将pg_wal目录移动到服务器上的 300GB 本地存储设备之一。这允许测量 pgbench 数据本身的读写性能。这主要是随机 IO,否则会被 WAL 流量的顺序写入访问路径中断。
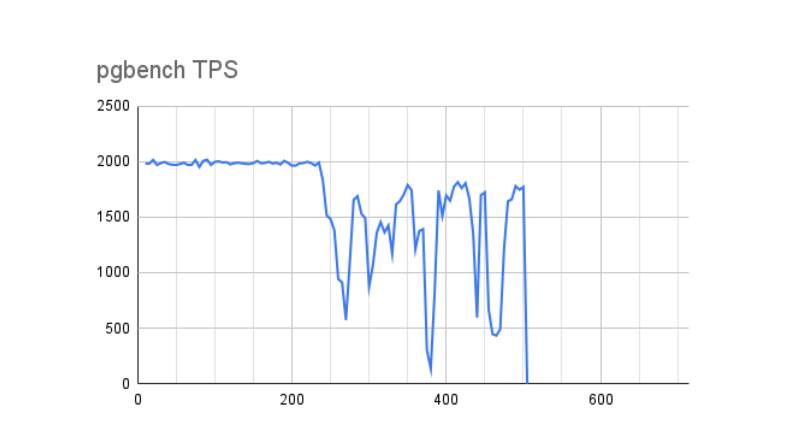
一旦我们运行基准测试并将结果制成表格,问题的根源就变得清晰了。第一张图表概述了 500 秒内映射的 pgbench TPS。
下图显示了同一时期 Linux 脏缓冲区 RAM 分配的大小:
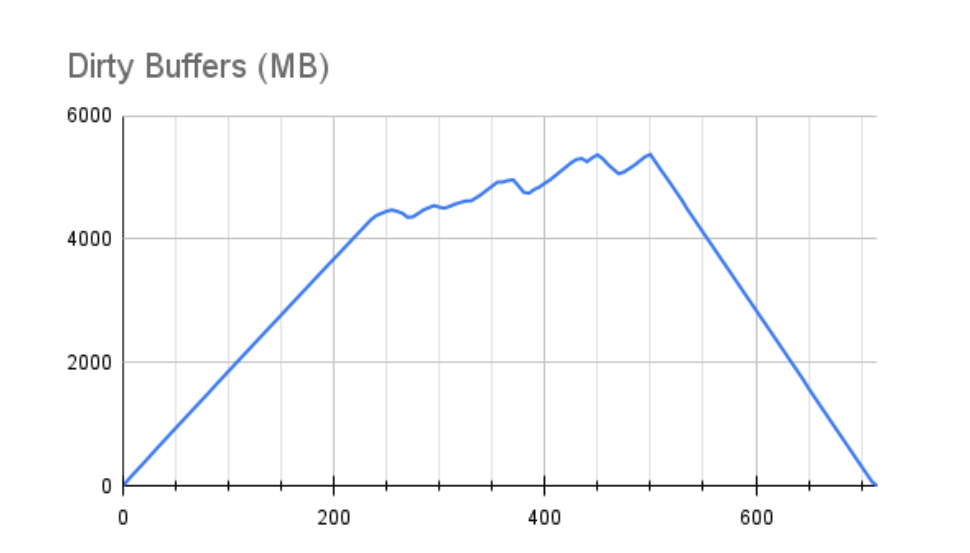
请注意,Dirty Buffers 达到大约 4.5GB 后性能立即下降。在我们的 32GB 服务器上,此图表上的内存范围大约占可用 RAM 的 15-20%。对于熟悉 Linux VM 可调参数的人来说,这种行为是由vm.dirty_ratio内核参数驱动的,该参数通常设置在 10-20% 之间,但在许多情况下可能更高。
当脏缓冲区超过 vm.dirty_ratio 指定的 RAM 量时,Linux 基本上是按顺序进行的,暂停所有挂起的写入以允许写入队列在该比率下耗尽。这两个图表都反映了性能再也没有达到峰值,在测试过程中多次大幅下降几乎达到零 TPS。即使在测试结束后,缓冲区也没有完全排空额外的215 秒。请记住,其中许多缓冲区可能是 fsync 操作,实际上我们的 Postgres 日志显示一些检查点同步操作需要 8-12 秒才能处理。如果我们此时遇到服务器硬件故障会发生什么?
挑战极限
我们的标准调整建议将 vm.dirty_ratio 降低到 10% 或更低,以防止长时间的缓冲区刷新。实际上,在具有 512GB RAM 的服务器上,我们可能不希望 50GB 的缓冲区开始刷新并淹没底层存储。但是仍然存在我们应该增加最大脏缓冲区以保持性能的潜在论点。
为了更好地控制这种情况,我们选择利用vm.dirty_bytes设置而不是 vm.dirty_ratio,因此我们可以指定确切的字节数而不是 RAM 的百分比。我们还将相关的vm.dirty_background_bytes限制为我们选择的 vm.dirty_ratio 值的 25%,以鼓励在达到该最大值之前很久就进行后台写入。
在下一个案例中,我们使用反映 16GB 脏 RAM 的设置进行测试,最终得到以下结果:
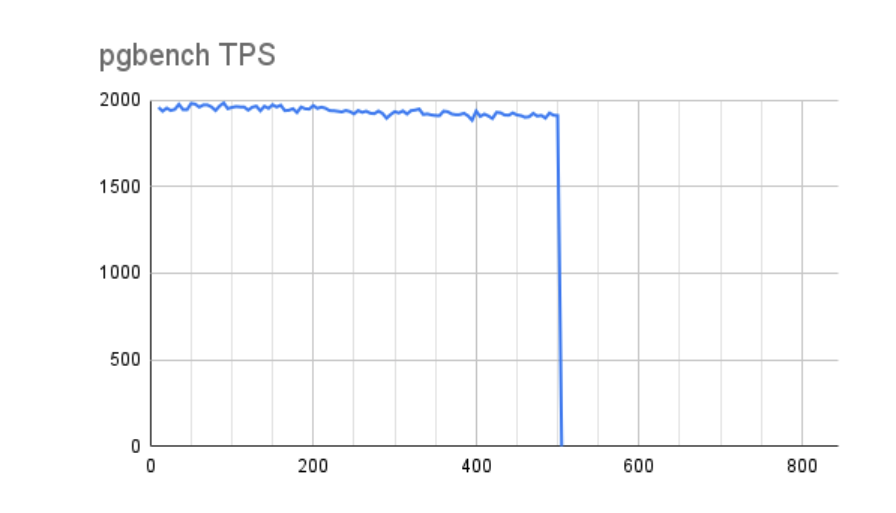
好吧,这看起来确实是一个显着的进步!随着时间的推移,性能会缓慢下降,但没有什么实质性的。但是让我们看看缓冲区:
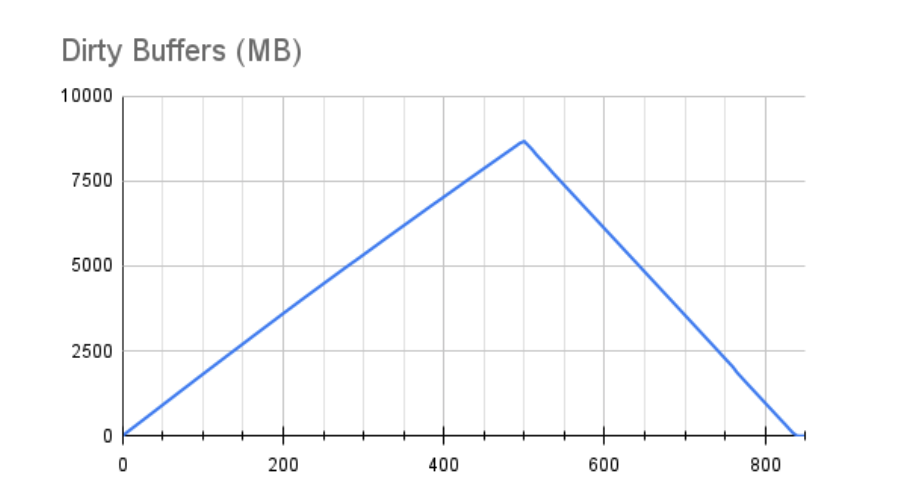
不幸的是,这几乎没有那么令人鼓舞。我们没有看到同样的性能下降的唯一原因是我们只达到了 16GB 可用脏缓冲区中的 8GB。如果我们允许测试运行更长的时间,它将与第一个结果非常相似,但更长的 x 轴代表我们的最大性能。我们也不能忽略排空这些缓冲区需要345 秒!
注意:这些测试都没有修改默认的 vm.dirty_expire_centisecs 或 vm.dirty_writeback_centisecs 内核参数。我们在这里尝试了各种值,但似乎没有明显影响结果。鉴于在这些测试期间底层存储设备似乎已完全饱和,这是意料之中的,因为对内存保留期的微小调整不会显着减少此写入量。
引入缓冲节流阀
这是一种罕见的情况,我们更喜欢吞吐量而不是写入持久性,那么如果我们减少脏缓冲区的最大大小会发生什么?我们通常建议将 vm.dirty_bytes 调整为存储写入缓存的总大小(如果知道)。由于 SSD 和 NVMe 设备往往没有这些,我们改用 1GB 的低值。
这次我们的图表看起来有点不同。首先,我们的 TPS 表现:

虽然我们很快溢出了 1GB 缓冲区,但我们的性能停滞并没有那么明显。我们可以在缓冲区图中看到为什么会出现这种情况:
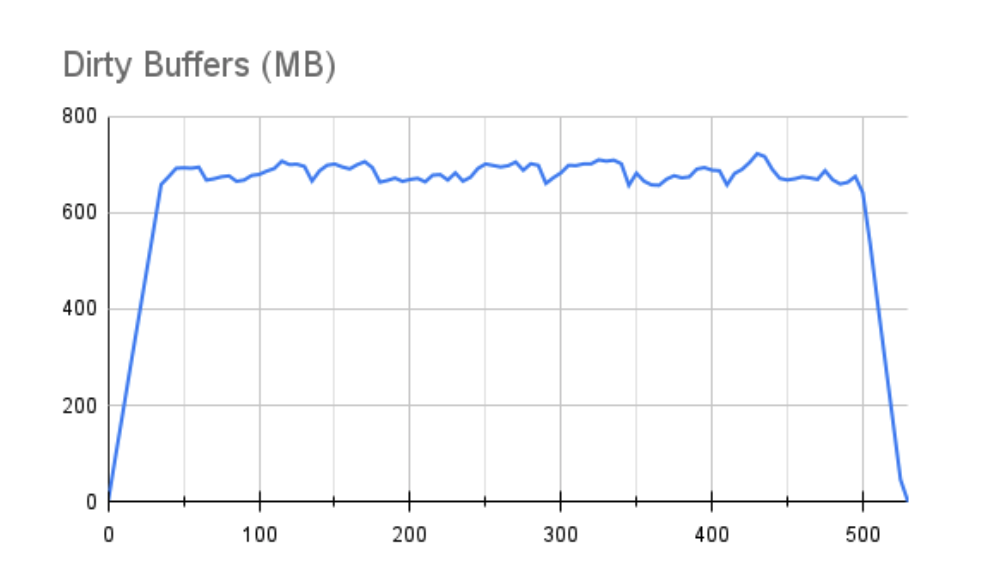
也许最重要的是,一个 1GB 的缓冲区在测试结束后只需要 30 秒就可以耗尽。在所有这些情况下,我们的权衡必须始终包括脏写将继续使用此存储后端累积的事实,原因有两个:
- 我们用写请求压倒了底层存储。
- 没有足够的存储缓存来吸收此写入吞吐量。
尽管底层硬盘驱动器的性能较旧且性能较慢,但存储控制器通常可以通过缓存将这些影响降至最低。AWS EBS 存储没有这种奢侈。还是我们?
金属踏板
解决我们难题的一种方法是简单地分配更高的 IOPS 存储。更高的吞吐量可以更快地耗尽缓冲区积压,甚至可以从一开始就防止这种堆积。Amazon 更高性能的预置 IOPS卷可提供数万 IOPS(有成本),因此可以简单地花钱解决问题。
因此,我们使用 10,000 IOPS io2 设备重新运行了 8GB 和 1GB vm.dirty_bytes 测试,以查看结果比较。首先,让我们看看 8GB 的脏缓冲区是如何影响 pgbench 事务吞吐量的:
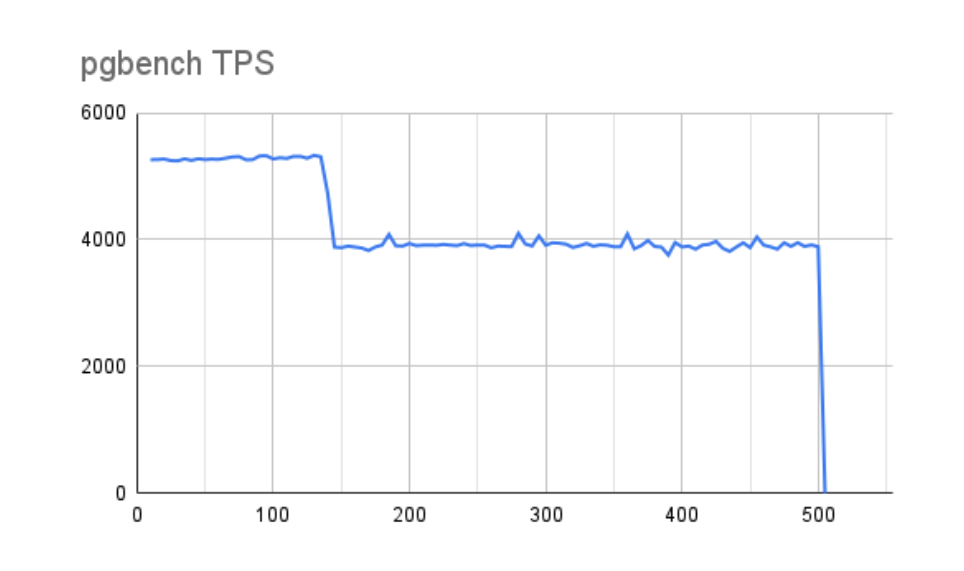
这实际上是相当令人鼓舞的。不仅我们的最大 TPS 几乎增加了三倍,而且即使在考虑了缓冲区并且性能下降之后,我们的平均吞吐量仍然几乎是使用较慢存储的最佳测量值的两倍。该图的锯齿状也少得多,这表明只要 Linux 暂停写入,存储就会迅速赶上。此行为反映在随附的缓冲区图表中:
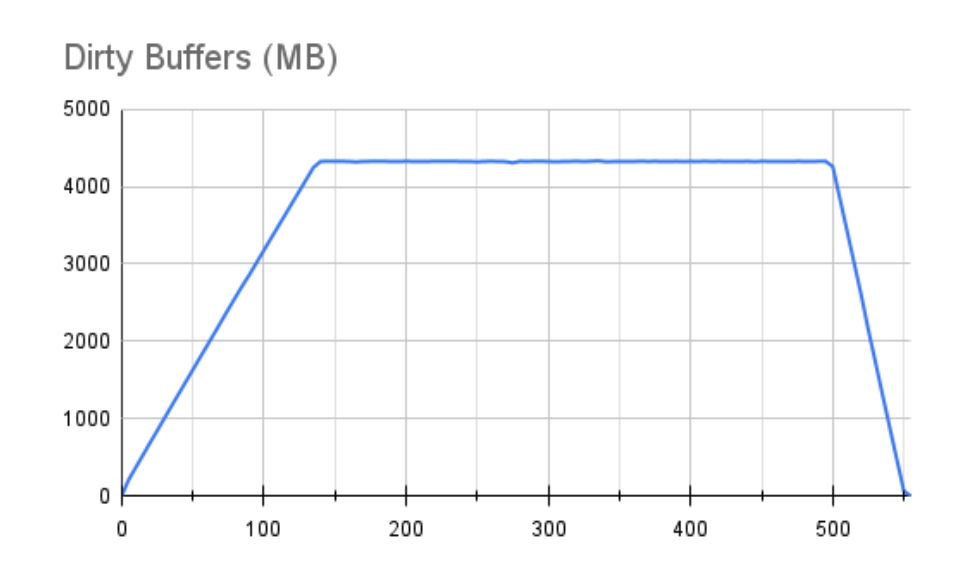
一旦我们达到最大数量的脏缓冲区,它就不是一条破坏性的锯齿线,它几乎是平坦的。这仍然不是一个理想的情况,因为很明显我们仍然在使用写入吞吐量来压倒底层存储,但这是一个更好的情况。即使有这么大的缓冲区,它也在 55 秒内被完全刷新。
当我们移动到 1GB 缓冲区并检查 pgbench TPS 吞吐量时,情况类似:
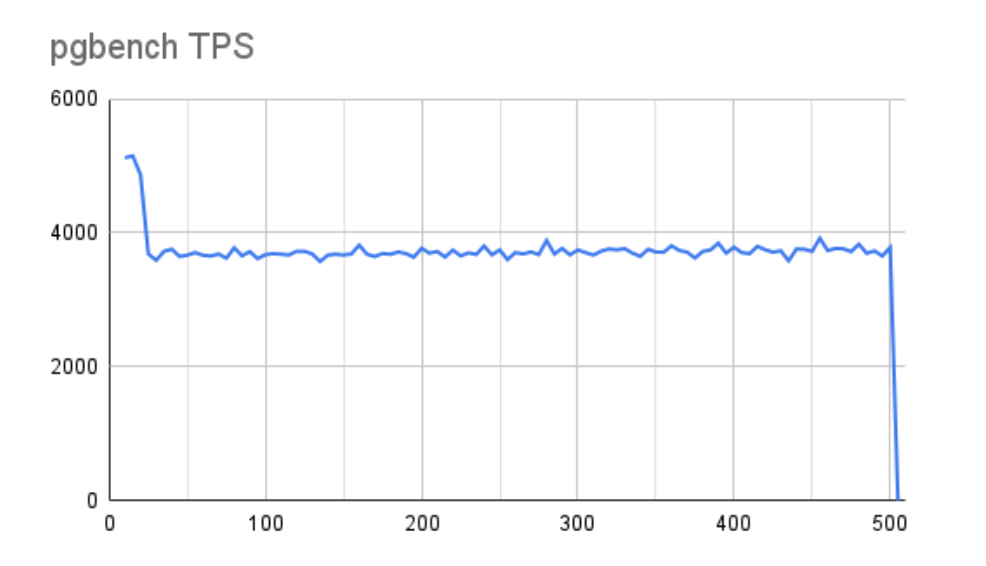
使用更激进的 1GB 缓冲区,我们确实会损失一些整体性能,但并不像我们在较慢的存储中看到的那么多。此外,线路更加稳定。测试期间缓冲区的状态也反映了这一点:
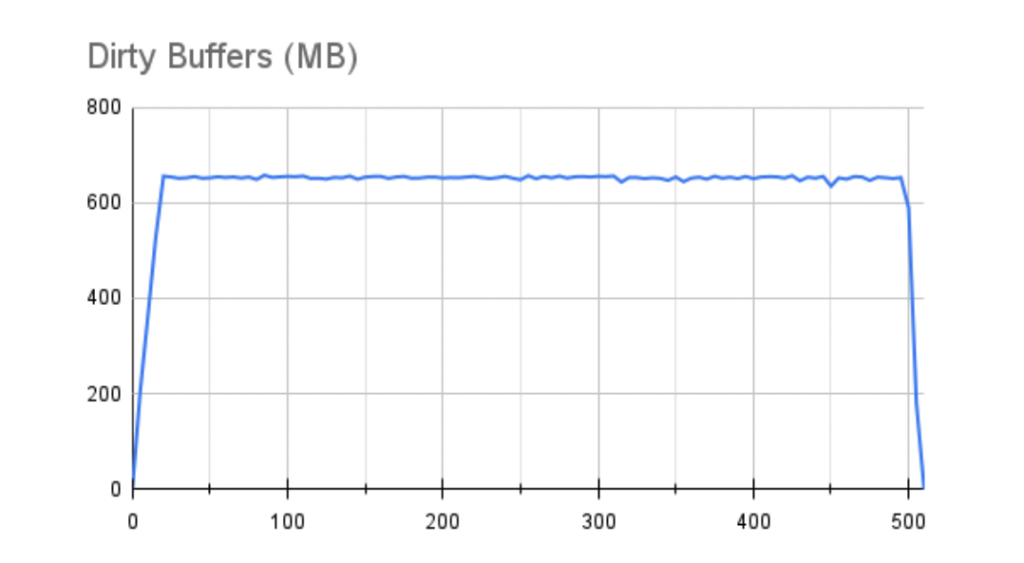
更好的是,一个 1GB 的缓冲区在不到 10 秒的时间内完全耗尽。这使我们更接近我们在配备控制器的服务器中看到的行为,该服务器可以立即吸收 1GB 缓冲区刷新。我们还应该承认,对于 EC2 实例和 EBS 存储的这种组合,我们只使用了最多 64,000 次 IOPS 中的 10,000 次。
存储摘要
基本上我们可以从中吸取两个教训:
- 由于缺少硬件控制器缓存,监控云实例中的脏缓冲区尤为重要。
- 将存储分配与预期工作负载相匹配同样重要。
AWS 在其预置的 IOPS 文档和手册中直接引用关系数据库工作负载是有原因的。它们的通用存储可以达到类似的性能数据,但 IOPS 与卷大小严格相关,并且需要在软件 RAID 中组合多个卷才能真正达到这些水平。
高性能存储所涉及的费用也并非微不足道。我们微不足道的 10k TPS 500GB io2 卷的 EBS存储成本计算器每月花费超过 700 美元,其中 650 美元来自我们的 IOPS 规范。因此,为了降低成本,供应不足可能很诱人。但正如我们从操作系统缓冲区图表中看到的那样,这样做的结果可能是灾难性的,由于同步时间过长而导致数据丢失。
最后,从底层硬件和大小实例相应地收集大量性能统计数据至关重要。如果我们没有观察到过多的缓冲区保留,我们可能会缩小我们的实例或存储卷分配。相反,我们可能需要根据此处提供的图表来增加。如果没有中间机制(例如磁盘控制器)来吸收大量写入刷新,我们必须完全依赖底层存储的能力。因此,迁移到云端可能会带来意想不到的成本。
在我们的具体案例中,这只会对一些基准产生不利影响。高度可用的生产环境将提供更严格的性能和耐用性保证。记得注意那些缓冲区!
 在过去的 20 年里,Shaun 担任过各种角色,包括 DBA、数据库架构师、开发人员、顾问、会议发言人、作者等等。这些天来,他将精力集中在 Postgres 高可用性上,因为他的大部分会议演讲、网络研讨会和用户组演示......
在过去的 20 年里,Shaun 担任过各种角色,包括 DBA、数据库架构师、开发人员、顾问、会议发言人、作者等等。这些天来,他将精力集中在 Postgres 高可用性上,因为他的大部分会议演讲、网络研讨会和用户组演示......
原文标题:Steady Storage Stampede
原文作者:肖恩·托马斯
原文地址:https://www.enterprisedb.com/blog/steady-storage-stampede
