




SHAP 是 Python 开发的一个"模型解释"包,可以解释任何机器学习模型的输出。其名称来源于SHapley Additive exPlanation,在合作博弈论的启发下SHAP构建一个加性的解释模型,所有的特征都视为“贡献者”。对于每个预测样本,模型都产生一个预测值,SHAP value就是该样本中每个特征所分配到的数值。
本文从代码实践层面来举例 Shap 包中几种常见 Explainer 的API调用,包括 Tree,Permutation,Exact 和 Kernel Explainer。文中例子以CatBoostRegressor 来拟合经典的 Boston House Price 作为模型。后续会解读 Shapley 的经典论文和深入理解。
本文代码可以通过关注MyEncyclopedia公众号后回复 jupyter-shap
获得链接,或者直接访问以下网址也可获得https://app.myencyclopedia.top/download_code/jupyter-shap
CatBoost 波士顿房价模型
from catboost import *
import shap
shap.initjs()
波士顿住房数据集由 1978 年波士顿周围的 506 个街区组成,我们的目标是根据 14 个不同的特征预测每个街区的房价中位数(以千计):
CRIM - 城镇人均犯罪率 ZN - 超过 25,000 平方英尺的住宅用地比例。 INDUS - 每个城镇的非零售商业用地的比例。 CHAS - 查尔斯河虚拟变量(如果区域边界河流,则为 1;否则为 0) NOX - 一氧化氮浓度(百万分之一) RM - 每个住宅的平均房间数 AGE - 1940 年之前建造的自有单位的比例 DIS - 到波士顿五个就业中心的加权距离 RAD - 高速公路可达性指数 TAX - 每 10,000 美元的全额财产税税率 PTRATIO - 城镇师生比例 B - 1000(Bk - 0.63)^2 其中 Bk 是城镇中黑人的比例 LSTAT - 人口地位较低的百分比 MEDV - 自住房屋的中位数价值 1000 美元
训练一个最基本的 CatBoostRegressor 模型。
X,y = shap.datasets.boston()
model = CatBoostRegressor(iterations=300, learning_rate=0.1, random_seed=123)
model.fit(X, y, verbose=False, plot=False)
out:
<catboost.core.CatBoostRegressor at 0x2146600da00>
Shapley 简单介绍
基于 Shapley 价值的机器学习模型解释背后的核心思想是使用合作博弈论的公平分配结果来为模型的输出分配信用 f(x) 在它的输入特征中。为了将博弈论与机器学习模型联系起来,既要将模型的输入特征与游戏中的玩家相匹配,又要将模型函数与游戏规则相匹配。由于在博弈论中玩家可以加入或不加入游戏,我们需要一种方法让特征“加入”或“不加入”模型。定义特征“加入”模型意味着什么的最常见方法是,当我们知道该特征的价值时,说该特征“加入了模型”,而当我们不知道该特征时,它还没有加入模型知道该功能的价值。评估现有模型 f 当只有一个子集 S 的特征是模型的一部分,我们使用条件期望值公式整合了其他特征。这个公式可以有两种形式:

在第一种形式中,我们知道 S 中特征的值,因为我们观察它们。在第二种形式中,我们知道 S 中特征的值,因为我们设置了它们。一般来说,第二种形式通常更可取,因为它告诉我们如果我们要干预和改变它的输入,模型会如何表现,也因为它更容易计算。在本教程中,我们将完全专注于第二个公式。我们还将使用更具体的术语 SHAP 值来指代应用于机器学习模型的条件期望函数的 Shapley 值。
TreeExplainer
对于 CatBoostRegressor 用 TreeExplainer 是最合适的。
%%time
tree_explainer = shap.TreeExplainer(model)
tree_shap_values = tree_explainer.shap_values(X)
out:
Wall time: 89.1 ms
tree_explainer.shap_values(X)
对每个 X 中的实例都计算了 Shap value,从它执行的时间来看很快。
tree_shap_values.shape
out:
(506, 13)
tree_shap_value
的 shape 表示有 506 个实例,每个实例有 13 维特征。
force_plot
可视化 X 中第一个实例的特征影响
shap.force_plot(tree_explainer.expected_value, tree_shap_values[0,:], X.iloc[0,:])

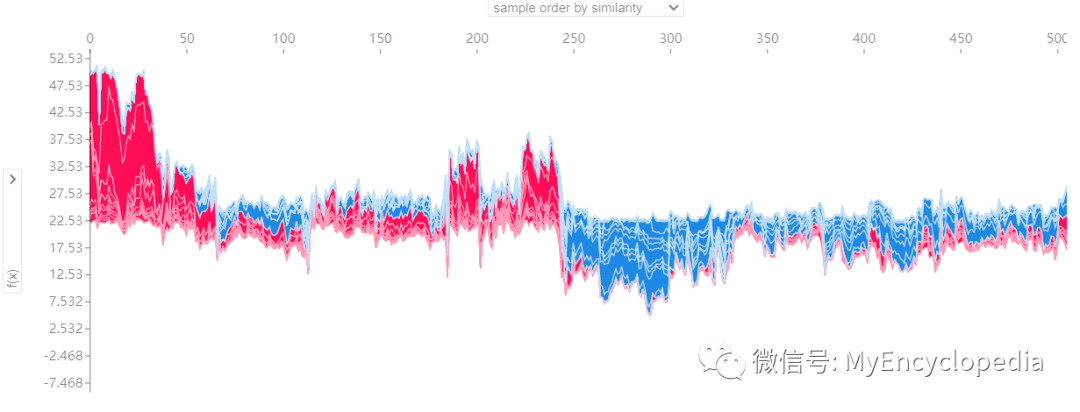
上面的解释显示了每个有助于将模型输出从基值(我们传递的训练数据集上的平均模型输出)贡献到模型输出值的特征。将预测推高的特征以红色显示,将预测推低的特征以蓝色显示。
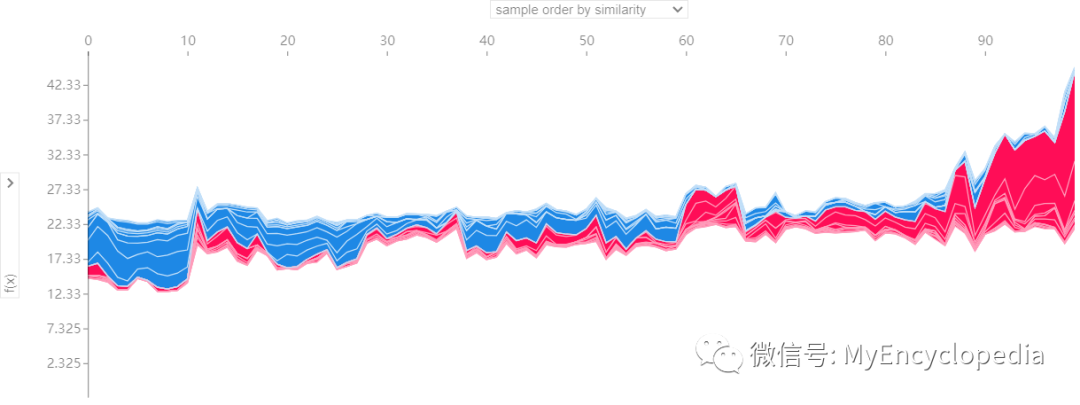
如果我们采取许多实例来聚合显示解释,如下图所示,将它们旋转 90 度,然后将它们水平堆叠,我们可以看到整个数据集的解释(在 Notebook 中,此图是交互式的):
# visualize the training set predictions
shap.force_plot(tree_explainer.expected_value, tree_shap_values, X)
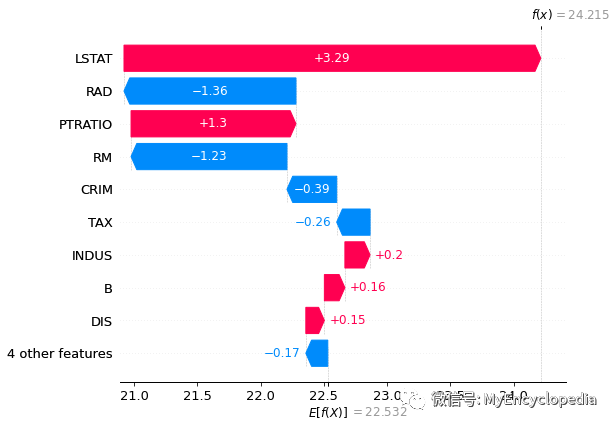
waterfall
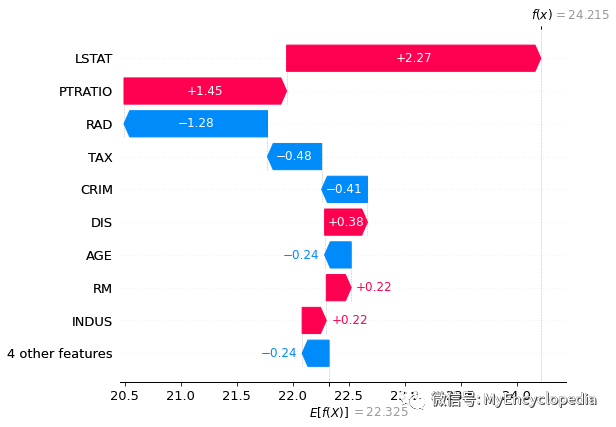
对第一个实例的特征贡献图也可用 waterfall 方式展示
# not support waterfall() but waterfall_legacy()
# shap.plots.waterfall(tree_shap_values[0])
shap.plots._waterfall.waterfall_legacy(
tree_explainer.expected_value,
tree_shap_values[0],
feature_names=X.columns)
summary_plot
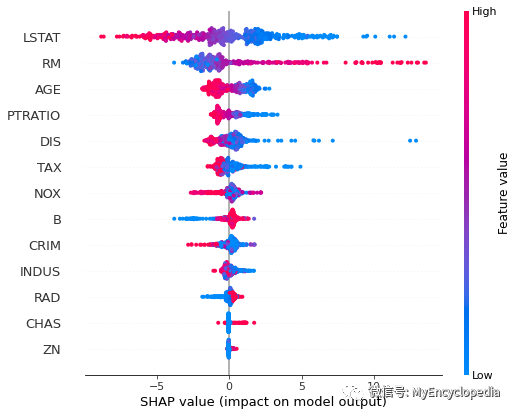
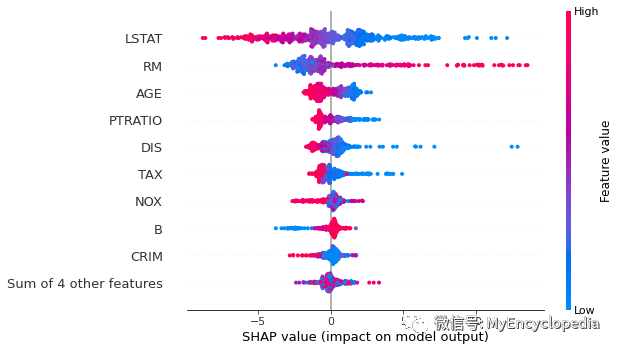
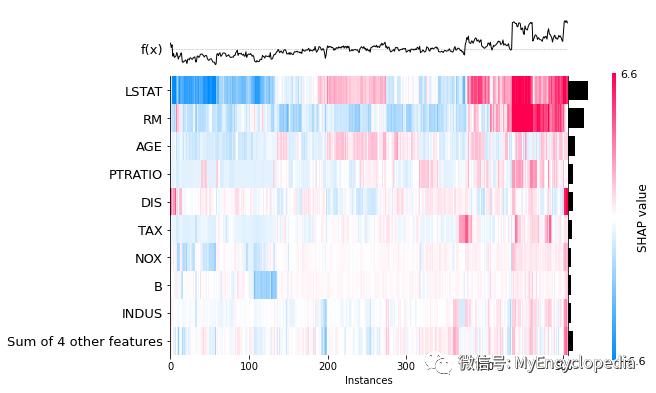
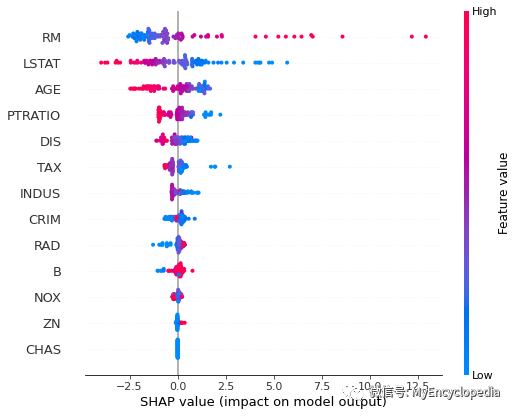
为了大致了解哪些特征对模型最重要,我们可以绘制每个样本的每个特征的 SHAP 值。下图按所有样本的 SHAP 值大小之和对特征进行排序,并使用 SHAP 值显示每个特征对模型输出的影响分布。颜色代表特征值(红色高,蓝色低)。例如,这表明较高的 LSTAT(人口地位较低的百分比)会降低预测的房价。
# summarize the effects of all the features
shap.summary_plot(tree_shap_values, X)

dependence_plot
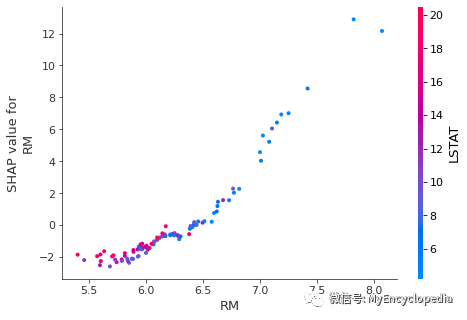
要了解单个特征如何影响模型的输出,可以绘制该特征的 SHAP 值与数据集中所有示例的特征值。由于 SHAP 值表示特征对模型输出变化的责任,因此下图表示预测房价随 RM 变化而发生的变化。单个 RM 值的垂直离散度表示与其他特征的相互作用效应。为了帮助揭示这些相互作用,dependence_plot 自动选择另一个特征进行着色。在这种情况下,RAD 的着色强调了 RM 对靠近高速公路的地区的房价影响较小。
# create a SHAP dependence plot to show the effect of a single feature across the whole dataset
shap.dependence_plot("RM", tree_shap_values, X)

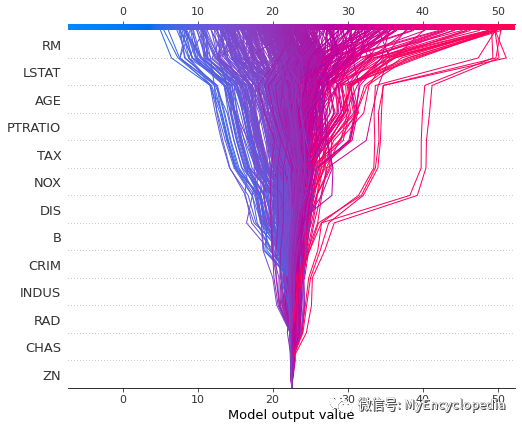
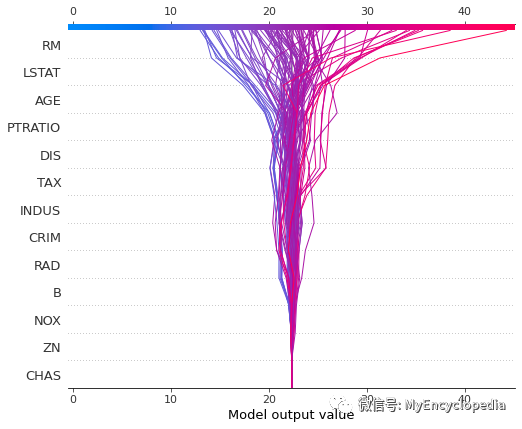
decision_plot
decision_plot
也能可视化每种特征对于整体预测值的影响。
shap.decision_plot(tree_explainer.expected_value, tree_shap_values, X)
其他
# Not supported by Tree Explainer
# shap.plots.bar(tree_shap_values)
# shap.plots.beeswarm(tree_shap_values)
# shap.plots.scatter(tree_shap_values[:,"LSTAT"])
Permutation Explainer
若直接调用 shap.Explainer
获得的是 Permutation Explainer。我们需要定义一个新的方法 call_catboost
,它接受 X
来传给构造函数。
def call_catboost(X):
return model.predict(Pool(X))
explainer = shap.Explainer(call_catboost, X)
type(explainer)
out:
shap.explainers._permutation.Permutation
下面为506个实例生成 permuation shap value 花了24.9s,远远慢于 tree explainer 的 89ms。
%%time
perm_explainer = explainer
perm_shap_values = perm_explainer(X)
out:
Permutation explainer: 507it [00:24, 20.40it/s]
Wall time: 24.9 s
单个数据点绘图
force_plot
不支持 force_plot。
# Not supported by Permutation Explainer
# shap.force_plot(perm_explainer.expected_value, perm_shap_values[0,:], X.iloc[0,:])
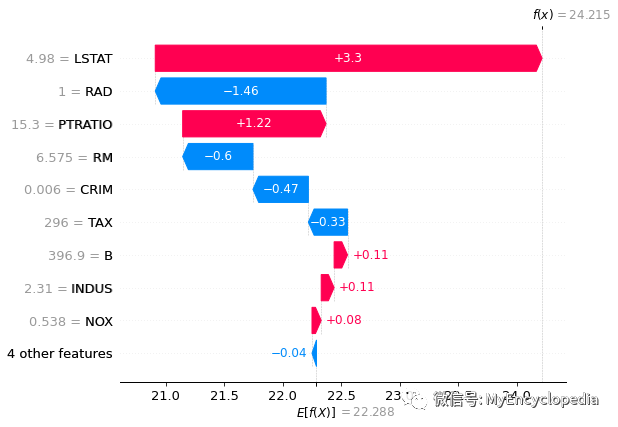
waterfall
shap.plots.waterfall(perm_shap_values[0])
聚合绘图
force_plot
还是不支持 force_plot。
# Not supported by Permutation Explainer
# shap.force_plot(perm_explainer.expected_value, perm_shap_values, X)
summary_plot
shap.summary_plot(perm_shap_values, X)
不支持 dependence_plot decision_plot
# Not supported by Permutation Explainer
# shap.dependence_plot("RM", perm_shap_values, X)
# shap.decision_plot(perm_explainer.expected_value, perm_shap_values, X)
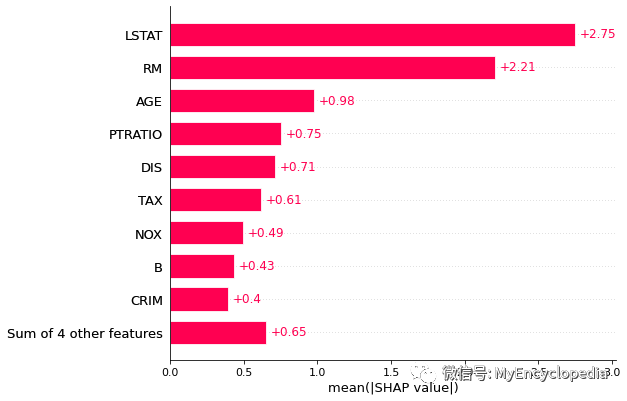
plots.bar
shap.plots.bar(perm_shap_values)
plots.beeswarm
shap.plots.beeswarm(perm_shap_values)
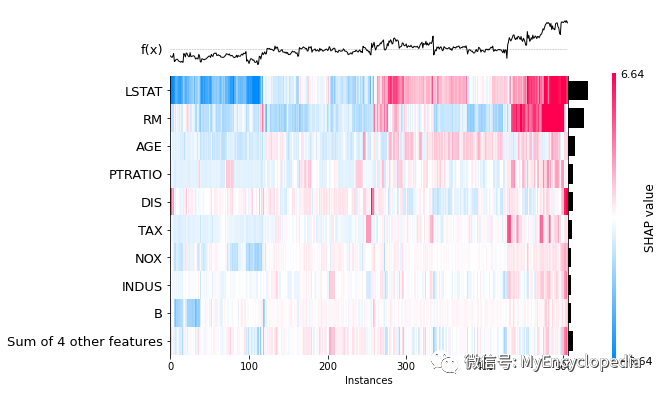
plots.heatmap
shap.plots.heatmap(perm_shap_values)
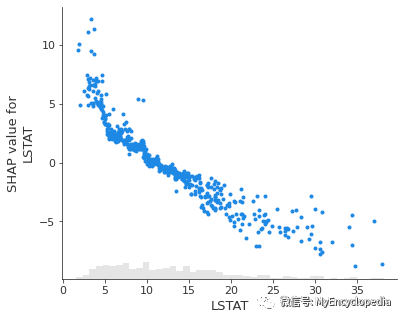
plots.scatter
shap.plots.scatter(perm_shap_values[:,"LSTAT"])
Exact Explainer
Exact Explainer 是最原始无优化的 explainer,生成506个实例花了 1分34秒。
exact_explainer = shap.explainers.Exact(call_catboost, X)
%%time
exact_shap_values = exact_explainer(X)
out:
Exact explainer: 507it [01:34, 5.38it/s]
Wall time: 1min 34s
单个数据点绘图
不支持 force_plot
# Not supported by Exact Explainer
# shap.force_plot(exact_explainer.expected_value, exact_shap_values[0,:], X.iloc[0,:])
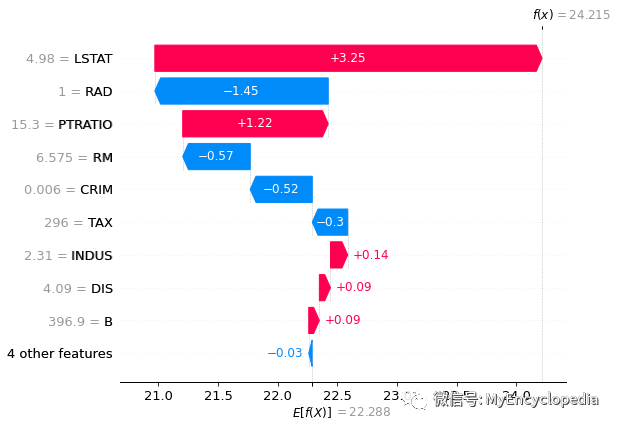
waterfall
shap.plots.waterfall(exact_shap_values[0])
聚合绘图
summary_plot
shap.summary_plot(exact_shap_values, X)

不支持 dependence_plot decision_plot
# Not supported by Exact Explainer
#shap.dependence_plot("RM", exact_shap_values, X)
#shap.decision_plot(exact_explainer.expected_value, exact_shap_values, X)
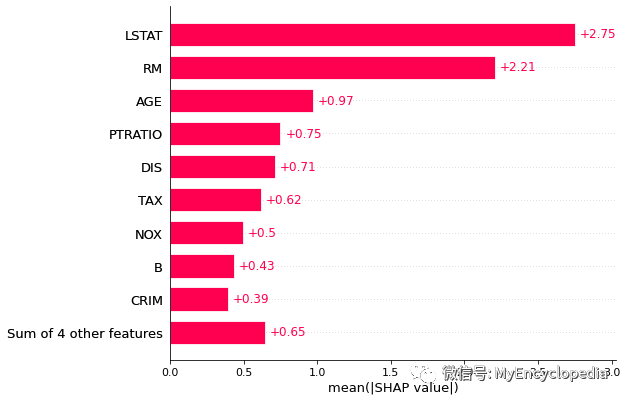
plots.bar
shap.plots.bar(exact_shap_values)
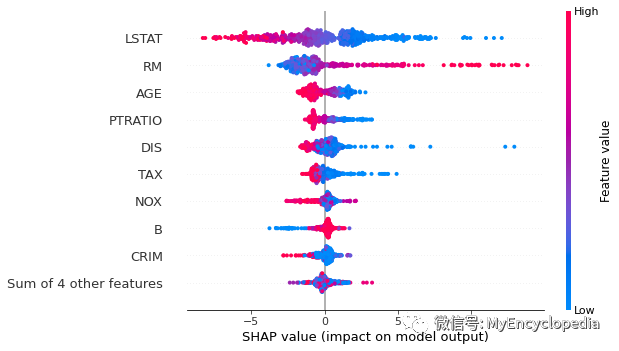
plots.beeswarm
shap.plots.beeswarm(exact_shap_values)
plots.heatmap
shap.plots.heatmap(exact_shap_values)
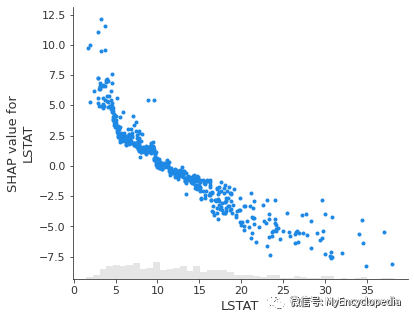
plots.scatter
shap.plots.scatter(exact_shap_values[:,"LSTAT"])
KernelExplainer
KernelExplainer 在 CatBoostRegressor 模型最慢。前100个实例用了 2分06秒。
%%time
X_sub = X[0:100]
kernel_explainer = shap.KernelExplainer(call_catboost, X_sub)
kernel_shap_values = kernel_explainer.shap_values(X_sub)
out:
HBox(children=(FloatProgress(value=0.0), HTML(value='')))
Wall time: 2min 6s
单个数据点绘图
force_plot
shap.force_plot(kernel_explainer.expected_value, kernel_shap_values[0,:], X.iloc[0,:])

waterfall
# not support waterfall() but waterfall_legacy()
# shap.plots.waterfall(kernel_shap_values[0])
shap.plots._waterfall.waterfall_legacy(
kernel_explainer.expected_value,
kernel_shap_values[0],
feature_names=X.columns)
聚合绘图
force_plot
shap.force_plot(kernel_explainer.expected_value, kernel_shap_values, X)
summary_plot
shap.summary_plot(kernel_shap_values, X_sub)
dependence_plot
shap.dependence_plot("RM", kernel_shap_values, X_sub)
decision_plot
shap.decision_plot(kernel_explainer.expected_value, kernel_shap_values, X_sub)
其他不支持
# Not supported by Kernel Explainer
# shap.plots.bar(kernel_shap_values)
# shap.plots.beeswarm(kernel_shap_values)
# shap.plots.scatter(kernel_shap_values[:,"LSTAT"])
