




许多Nebula Graph社区用户提出的一个常见问题是如何将我们的图形数据库应用于基于Spark的分析。人们希望将我们强大的图形处理功能与Spark结合使用,Spark是最流行的数据分析引擎之一。
在本文中,我将尝试引导您了解四种不同的方法,让Nebula Graph和Apache Spark协同工作。前三种方法将使用Nebula Graph的三个库:Spark连接器、Nebula Exchange和Nebula算法,而第四种方法将利用PySpark,Python中Spark的接口。
在这段视频中,我介绍了很多Nebula Graph的数据导入方法,包括三种将数据导入Spark的方法。在本文中,我想深入研究这些与Spark相关的项目,如果你想把Nebula Graph和Spark联系起来的话,希望它能为你提供更多帮助.
TL;DR
-
Nebula Spark Connector是一个Spark库,使Spark应用程序能够以数据帧的形式读取和写入Nebula Graph。
-
Nebula Exchange建立在Nebula Spark Connector之上,是一个Spark库和应用程序,用于将不同的数据源(如MySQL、Neo4j、PostgreSQL、ClickHouse、Hive等)迁移到Nebula Graph。除了直接写入Nebula Graph外,它还可以选择性地生成SST文件,以将存储计算从Nebula Graph集群卸载到Spark集群。
-
Nebula算法建立在Nebula Spark Connector和GraphX之上,是一个Spark库,用于在Nebula graph的图形数据之上运行图形算法(PageRank、LPA等)。
-
如果您想使用Python使Spark和Nebula Graph协同工作,PySpark是一个解决方案,我将在最后一节介绍。
Spark连接器
Nebula Spark Connector是一个Spark库,用于使Spark应用程序能够以数据帧的形式读取和写入Nebula图形。
-
代码库:Nebula Spark连接器
-
文档:Nebula Spark文档(版本已定,目前我在这里放了最新发布的版本3.0.2)
-
Jar包:Nebula Spark Jar包
-
代码示例:代码示例
从Nebula Graph读取数据
为了从Nebula Graph中读取数据,Nebula Spark连接器将扫描包含给定标签(TAG)的Nebula Graph 中的所有存储实例。可以使用withLabel参数来指示标签。例如:withLabel(“player”)。您还可以选择指定顶点的属性:withReturnCols(List(“name”,“age”))。
一旦提供了所有必需的属性,就可以运行Spark.read.nebula.loadVerticesToDF,它将从Nebula Graph返回顶点的数据帧。
def readVertex(spark: SparkSession): Unit = {
LOG.info("start to read nebula vertices")
val config =
NebulaConnectionConfig
.builder()
.withMetaAddress("metad0:9559,metad1:9559,metad2:9559")
.withConenctionRetry(2)
.build()
val nebulaReadVertexConfig: ReadNebulaConfig = ReadNebulaConfig
.builder()
.withSpace("basketballplayer")
.withLabel("player")
.withNoColumn(false)
.withReturnCols(List("name", "age"))
.withLimit(10)
.withPartitionNum(10)
.build()
val vertex = spark.read.nebula(config, nebulaReadVertexConfig).loadVerticesToDF()
vertex.printSchema()
vertex.show(20)
println("vertex count: " + vertex.count())
}
writer部分类似,这里一个很大的区别是,写入路径是通过GraphD完成的,因为底层Spark连接器正在执行nGQL插入查询:
def writeVertex(spark: SparkSession): Unit = {
LOG.info("start to write nebula vertices")
val df = spark.read.json("example/src/main/resources/vertex")
df.show()
val config = getNebulaConnectionConfig()
val nebulaWriteVertexConfig: WriteNebulaVertexConfig = WriteNebulaVertexConfig
.builder()
.withSpace("test")
.withTag("person")
.withVidField("id")
.withVidAsProp(false)
.withBatch(1000)
.build()
df.write.nebula(config, nebulaWriteVertexConfig).writeVertices()
}
手动Spark连接器
先决条件:我假设您正在具有internet连接的Linux机器上运行以下过程。理想情况下,您将安装Docker和Docker Compose。
自举Nebula Graph Cluster
首先,让我们使用Nebula Up部署Nebula Graph v3.0和Nebula Studio,它将运行一个脚本,使用Docker和Docker Compose安装这两个工具。如果您尚未安装Docker和Docker Compose,脚本将自动为您安装它们。但为了确保获得最佳体验,您可以在机器上手动预安装Docker和Docker Compose。
curl -fsSL nebula-up.siwei.io/install.sh | bash -s -- v3.0
完成后,我们可以使用Nebula控制台(Nebula Graph的命令行客户端)连接到Nebula Graph实例。
- 使用Nebula控制台进入容器
nebula-console -addr graphd -port 9669 -user root -p nebula
- 激活存储实例,并检查主机状态
参考:Nebula Graph manage store host
ADD HOSTS "storaged0":9779,"storaged1":9779,"storaged2":9779;
SHOW HOSTS;
- 加载测试图数据,这将需要一到两分钟才能完成。
:play basketballplayer;
创建Spark场
得益于大数据欧洲(Big data Europe)提供了Spark Docker的形象,使用Docker创建Spark环境非常容易。
docker run --name spark-master-0 --network nebula-docker-compose_nebula-net \
-h spark-master-0 -e ENABLE_INIT_DAEMON=false -d \
-v ${PWD}/:/root \
bde2020/spark-master:2.4.5-hadoop2.7
使用这个YMAL文件,我们将创建一个名为spark-master-0的容器,其中包含内置的Hadoop 2.7和spark 2.4.5。该容器连接到名为Nebula-docker-compose_Nebula-net的docker网络中的Nebula Graph集群。它还将当前路径映射到spark容器的/根。
然后,我们可以使用以下工具访问Spark环境容器:
docker exec -it spark-master-0 bash
或者,我们可以在容器内安装mvn,以启用maven构建/打包:
docker exec -it spark-master-0 bash
# in the container shell
export MAVEN_VERSION=3.5.4
export MAVEN_HOME=/usr/lib/mvn
export PATH=$MAVEN_HOME/bin:$PATH
wget http://archive.apache.org/dist/maven/maven-3/$MAVEN_VERSION/binaries/apache-maven-$MAVEN_VERSION-bin.tar.gz && \
tar -zxvf apache-maven-$MAVEN_VERSION-bin.tar.gz && \
rm apache-maven-$MAVEN_VERSION-bin.tar.gz && \
mv apache-maven-$MAVEN_VERSION /usr/lib/mvn
which /usr/lib/mvn/bin/mvn
运行Spark连接器
在本节中,我将向您展示如何从其源代码构建Nebula Graph Spark连接器。
git clone https://github.com/vesoft-inc/nebula-spark-connector.git
docker exec -it spark-master-0 bash
cd /root/nebula-spark-connector
/usr/lib/mvn/bin/mvn install -Dgpg.skip -Dmaven.javadoc.skip=true -Dmaven.test.skip=true
vi example/src/main/scala/com/vesoft/nebula/examples/connector/NebulaSparkReaderExample.scala
在这个文件中,我们将放置以下代码,其中两个函数readVertex和ReadEdge是在basketballplayer图形空间上创建的:
package com.vesoft.nebula.examples.connector
import com.facebook.thrift.protocol.TCompactProtocol
import com.vesoft.nebula.connector.connector.NebulaDataFrameReader
import com.vesoft.nebula.connector.{NebulaConnectionConfig, ReadNebulaConfig}
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.slf4j.LoggerFactory
object NebulaSparkReaderExample {
private val LOG = LoggerFactory.getLogger(this.getClass)
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf
sparkConf
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.registerKryoClasses(Array[Class[_]](classOf[TCompactProtocol]))
val spark = SparkSession
.builder()
.master("local")
.config(sparkConf)
.getOrCreate()
readVertex(spark)
readEdges(spark)
spark.close()
sys.exit()
}
def readVertex(spark: SparkSession): Unit = {
LOG.info("start to read nebula vertices")
val config =
NebulaConnectionConfig
.builder()
.withMetaAddress("metad0:9559,metad1:9559,metad2:9559")
.withConenctionRetry(2)
.build()
val nebulaReadVertexConfig: ReadNebulaConfig = ReadNebulaConfig
.builder()
.withSpace("basketballplayer")
.withLabel("player")
.withNoColumn(false)
.withReturnCols(List("name", "age"))
.withLimit(10)
.withPartitionNum(10)
.build()
val vertex = spark.read.nebula(config, nebulaReadVertexConfig).loadVerticesToDF()
vertex.printSchema()
vertex.show(20)
println("vertex count: " + vertex.count())
}
def readEdges(spark: SparkSession): Unit = {
LOG.info("start to read nebula edges")
val config =
NebulaConnectionConfig
.builder()
.withMetaAddress("metad0:9559,metad1:9559,metad2:9559")
.withTimeout(6000)
.withConenctionRetry(2)
.build()
val nebulaReadEdgeConfig: ReadNebulaConfig = ReadNebulaConfig
.builder()
.withSpace("basketballplayer")
.withLabel("follow")
.withNoColumn(false)
.withReturnCols(List("degree"))
.withLimit(10)
.withPartitionNum(10)
.build()
val edge = spark.read.nebula(config, nebulaReadEdgeConfig).loadEdgesToDF()
edge.printSchema()
edge.show(20)
println("edge count: " + edge.count())
}
}
然后构建它:
cd example
/usr/lib/mvn/bin/mvn install -Dgpg.skip -Dmaven.javadoc.skip=true -Dmaven.test.skip=true
在Spark上执行:
/spark/bin/spark-submit --master "local" \
--class com.vesoft.nebula.examples.connector.NebulaSparkReaderExample \
--driver-memory 16g target/example-3.0-SNAPSHOT.jar
结果应该是这样的:
22/04/19 07:29:34 INFO DAGScheduler: Job 1 finished: show at NebulaSparkReaderExample.scala:57, took 0.199310 s
+---------+------------------+---+
|_vertexId| name|age|
+---------+------------------+---+
|player105| Danny Green| 31|
|player109| Tiago Splitter| 34|
|player111| David West| 38|
|player118| Russell Westbrook| 30|
|player143|Kristaps Porzingis| 23|
|player114| Tracy McGrady| 39|
|player150| Luka Doncic| 20|
|player103| Rudy Gay| 32|
|player113| Dejounte Murray| 29|
|player121| Chris Paul| 33|
|player128| Carmelo Anthony| 34|
|player130| Joel Embiid| 25|
|player136| Steve Nash| 45|
|player108| Boris Diaw| 36|
|player122| DeAndre Jordan| 30|
|player123| Ricky Rubio| 28|
|player139| Marc Gasol| 34|
|player142| Klay Thompson| 29|
|player145| JaVale McGee| 31|
|player102| LaMarcus Aldridge| 33|
+---------+------------------+---+
only showing top 20 rows
22/04/19 07:29:36 INFO DAGScheduler: Job 4 finished: show at NebulaSparkReaderExample.scala:82, took 0.135543 s
+---------+---------+-----+------+
| _srcId| _dstId|_rank|degree|
+---------+---------+-----+------+
|player105|player100| 0| 70|
|player105|player104| 0| 83|
|player105|player116| 0| 80|
|player109|player100| 0| 80|
|player109|player125| 0| 90|
|player118|player120| 0| 90|
|player118|player131| 0| 90|
|player143|player150| 0| 90|
|player114|player103| 0| 90|
|player114|player115| 0| 90|
|player114|player140| 0| 90|
|player150|player120| 0| 80|
|player150|player137| 0| 90|
|player150|player143| 0| 90|
|player103|player102| 0| 70|
|player113|player100| 0| 99|
|player113|player101| 0| 99|
|player113|player104| 0| 99|
|player113|player105| 0| 99|
|player113|player106| 0| 99|
+---------+---------+-----+------+
only showing top 20 rows
Spark Connector repo下有更多示例,包括GraphX。请注意,在GraphX中,假设顶点ID为数字,您需要将字符串ID类型即时转换为数字。请参考星云算法中关于如何缓解这种情况的示例。
Nebula 交换
-
代码库:Nebula 交换代码库
-
文档:Nebula Exchange文档(它已经过版本控制,目前我在这里放了最新发布的3.0.2版本)
-
Jar包:Nebula Exchange Jar包
-
配置示例:应用程序。形态
星云交换是一个Spark库,可以从多个来源读取数据,并将其直接写入星云图或星云图SST文件。
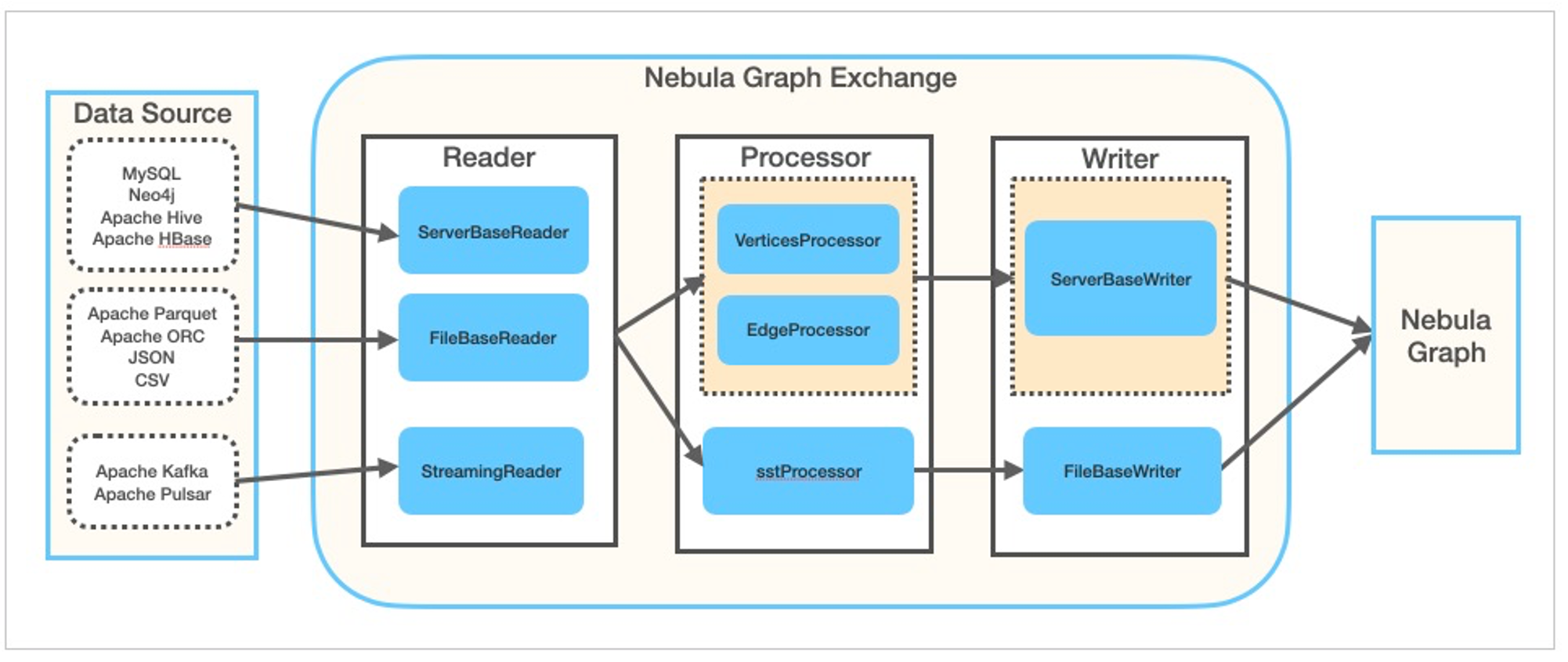
要使用Nebula Exchange,我们需要在conf文件中配置“从何处获取数据源”和“向何处写入图形数据”,并在指定conf文件的情况下将交换包提交给spark。
现在,让我们用上一章中创建的相同环境对星云交换进行一个动手测试。
实践Nebula Exchange
在这里,我们使用Nebula Exchange来使用CSV文件中的数据,其中第一列是顶点ID,第二列和第三列分别是“name”和“age”。
player800,"Foo Bar",23
player801,"Another Name",21
- 让我们登录上一章创建的Spark容器,下载Nebula Exchange的Jar包:
docker exec -it spark-master bash
cd /root/
wget https://github.com/vesoft-inc/nebula-exchange/releases/download/v3.0.0/nebula-exchange_spark_2.4-3.0.0.jar
-
创建一个名为exchange的conf文件。HOCONformat中的conf,其中:
.nebula 下,Nebula Graph Cluster有关的信息已配置;
.tags 下,有关顶点的信息,如必填字段在数据源中的反映方式(在本例中,它是CSV文件)。
{
# Spark relation config
spark: {
app: {
name: Nebula Exchange
}
master:local
driver: {
cores: 1
maxResultSize: 1G
}
executor: {
memory: 1G
}
cores:{
max: 16
}
}
# Nebula Graph relation config
nebula: {
address:{
graph:["graphd:9669"]
meta:["metad0:9559", "metad1:9559", "metad2:9559"]
}
user: root
pswd: nebula
space: basketballplayer
# parameters for SST import, not required
path:{
local:"/tmp"
remote:"/sst"
hdfs.namenode: "hdfs://localhost:9000"
}
# nebula client connection parameters
connection {
# socket connect & execute timeout, unit: millisecond
timeout: 30000
}
error: {
# max number of failures, if the number of failures is bigger than max, then exit the application.
max: 32
# failed import job will be recorded in output path
output: /tmp/errors
}
# use google's RateLimiter to limit the requests send to NebulaGraph
rate: {
# the stable throughput of RateLimiter
limit: 1024
# Acquires a permit from RateLimiter, unit: MILLISECONDS
# if it can't be obtained within the specified timeout, then give up the request.
timeout: 1000
}
}
# Processing tags
# There are tag config examples for different dataSources.
tags: [
# HDFS csv
# Import mode is client, just change type.sink to sst if you want to use client import mode.
{
name: player
type: {
source: csv
sink: client
}
path: "file:///root/player.csv"
# if your csv file has no header, then use _c0,_c1,_c2,.. to indicate fields
fields: [_c1, _c2]
nebula.fields: [name, age]
vertex: {
field:_c0
}
separator: ","
header: false
batch: 256
partition: 32
}
]
}
最后,让我们创建播放器.csv和exchange.conf文件,应列出如下:
# ls -l
-rw-r--r-- 1 root root 1912 Apr 19 08:21 exchange.conf
-rw-r--r-- 1 root root 157814140 Apr 19 08:17 nebula-exchange_spark_2.4-3.0.0.jar
-rw-r--r-- 1 root root 52 Apr 19 08:06 player.csv
我们可以将Exchange写为:
/spark/bin/spark-submit --master local \
--class com.vesoft.nebula.exchange.Exchange nebula-exchange_spark_2.4-3.0.0.jar \
-c exchange.conf
结果应该是这样的:
...
22/04/19 08:22:08 INFO Exchange$: import for tag player cost time: 1.32 s
22/04/19 08:22:08 INFO Exchange$: Client-Import: batchSuccess.player: 2
22/04/19 08:22:08 INFO Exchange$: Client-Import: batchFailure.player: 0
有关更多数据源,请参阅Nebula Exchange文档和配置示例。关于如何将Spark数据写入SST文件,您可以参考文档和Nebula Exchange SST 2.x实践指南。
Nebula 算法
Nebula算法建立在Nebula Spark Connector和GraphX之上,是一个Spark库和应用程序,用于在Nebula graph中的图形数据之上运行图形算法(Pagerank、LPA等)。
-
代码库:Nebula算法
-
文档:Nebula算法文档(版本已定,目前我在这里放了最新发布的3.0.2版本)
-
Jar包:Nebula算法Jar包
-
代码示例:Nebula算法代码示例
使用Spark—submit呼叫
当我们用spark submit调用Nebula算法时,从如何运行的角度来看,它与Nebula Exchange非常相似。
在代码中调用Nebula算法库
我们也可以将Spark中的星云算法称为库。这种方法将使您能够更好地控制算法的输出格式。此外,使用这种方法,可以对非数值顶点ID类型执行算法,请参见此处。
PySpark Nebula Graph
最后,如果您想使用Python使Spark和Nebula Graph协同工作,PySpark是一个可行的解决方案。在本节中,我将向您展示如何在PySpark的帮助下使用Nebula Spark连接器连接Spark和Nebula Graph。PySpark能够在Python内部调用Java或Scala包,这使得将Spark连接器与Python一起使用变得非常容易。
在这里,我从/spark/bin/PySpark中的PySpark入口点执行此操作,使用–driver-class-path和–jars指定Nebula连接器的Jar包
docker exec -it spark-master-0 bash
cd root
wget https://repo1.maven.org/maven2/com/vesoft/nebula-spark-connector/3.0.0/nebula-spark-connector-3.0.0.jar
/spark/bin/pyspark --driver-class-path nebula-spark-connector-3.0.0.jar --jars nebula-spark-connector-3.0.0.jar
然后,不要将NebulaConnectionConfig和ReadNebulaConfig传递给spark。阅读Nebula,我们应该称之为Spark.read.form(“com.vesoft.nebula.connector.NebulaDataSource”)。
df = spark.read.format(
"com.vesoft.nebula.connector.NebulaDataSource").option(
"type", "vertex").option(
"spaceName", "basketballplayer").option(
"label", "player").option(
"returnCols", "name,age").option(
"metaAddress", "metad0:9559").option(
"partitionNumber", 1).load()
>>> df.show(n=2)
+---------+--------------+---+
|_vertexId| name|age|
+---------+--------------+---+
|player105| Danny Green| 31|
|player109|Tiago Splitter| 34|
+---------+--------------+---+
我还使用Scala建立了相同的连接,尽管我几乎没有Scala知识。
参考文献:
读者应该如何称呼
def loadVerticesToDF(): DataFrame = {
assert(connectionConfig != null && readConfig != null,
"nebula config is not set, please call nebula() before loadVerticesToDF")
val dfReader = reader
.format(classOf[NebulaDataSource].getName)
.option(NebulaOptions.TYPE, DataTypeEnum.VERTEX.toString)
.option(NebulaOptions.SPACE_NAME, readConfig.getSpace)
.option(NebulaOptions.LABEL, readConfig.getLabel)
.option(NebulaOptions.PARTITION_NUMBER, readConfig.getPartitionNum)
.option(NebulaOptions.RETURN_COLS, readConfig.getReturnCols.mkString(","))
.option(NebulaOptions.NO_COLUMN, readConfig.getNoColumn)
.option(NebulaOptions.LIMIT, readConfig.getLimit)
.option(NebulaOptions.META_ADDRESS, connectionConfig.getMetaAddress)
.option(NebulaOptions.TIMEOUT, connectionConfig.getTimeout)
.option(NebulaOptions.CONNECTION_RETRY, connectionConfig.getConnectionRetry)
.option(NebulaOptions.EXECUTION_RETRY, connectionConfig.getExecRetry)
.option(NebulaOptions.ENABLE_META_SSL, connectionConfig.getEnableMetaSSL)
.option(NebulaOptions.ENABLE_STORAGE_SSL, connectionConfig.getEnableStorageSSL)
if (connectionConfig.getEnableStorageSSL || connectionConfig.getEnableMetaSSL) {
dfReader.option(NebulaOptions.SSL_SIGN_TYPE, connectionConfig.getSignType)
SSLSignType.withName(connectionConfig.getSignType) match {
case SSLSignType.CA =>
dfReader.option(NebulaOptions.CA_SIGN_PARAM, connectionConfig.getCaSignParam)
case SSLSignType.SELF =>
dfReader.option(NebulaOptions.SELF_SIGN_PARAM, connectionConfig.getSelfSignParam)
}
}
dfReader.load()
}
- 选项字符串应该是什么样子
object NebulaOptions {
/** nebula common config */
val SPACE_NAME: String = "spaceName"
val META_ADDRESS: String = "metaAddress"
val GRAPH_ADDRESS: String = "graphAddress"
val TYPE: String = "type"
val LABEL: String = "label"
/** connection config */
val TIMEOUT: String = "timeout"
val CONNECTION_RETRY: String = "connectionRetry"
val EXECUTION_RETRY: String = "executionRetry"
val RATE_TIME_OUT: String = "reteTimeOut"
val USER_NAME: String = "user"
val PASSWD: String = "passwd"
val ENABLE_GRAPH_SSL: String = "enableGraphSSL"
val ENABLE_META_SSL: String = "enableMetaSSL"
val ENABLE_STORAGE_SSL: String = "enableStorageSSL"
val SSL_SIGN_TYPE: String = "sslSignType"
val CA_SIGN_PARAM: String = "caSignParam"
val SELF_SIGN_PARAM: String = "selfSignParam"
/** read config */
val RETURN_COLS: String = "returnCols"
val NO_COLUMN: String = "noColumn"
val PARTITION_NUMBER: String = "partitionNumber"
val LIMIT: String = "limit"
/** write config */
val RATE_LIMIT: String = "rateLimit"
val VID_POLICY: String = "vidPolicy"
val SRC_POLICY: String = "srcPolicy"
val DST_POLICY: String = "dstPolicy"
val VERTEX_FIELD = "vertexField"
val SRC_VERTEX_FIELD = "srcVertexField"
val DST_VERTEX_FIELD = "dstVertexField"
val RANK_FIELD = "rankFiled"
val BATCH: String = "batch"
val VID_AS_PROP: String = "vidAsProp"
val SRC_AS_PROP: String = "srcAsProp"
val DST_AS_PROP: String = "dstAsProp"
val RANK_AS_PROP: String = "rankAsProp"
val WRITE_MODE: String = "writeMode"
val DEFAULT_TIMEOUT: Int = 3000
val DEFAULT_CONNECTION_TIMEOUT: Int = 3000
val DEFAULT_CONNECTION_RETRY: Int = 3
val DEFAULT_EXECUTION_RETRY: Int = 3
val DEFAULT_USER_NAME: String = "root"
val DEFAULT_PASSWD: String = "nebula"
val DEFAULT_ENABLE_GRAPH_SSL: Boolean = false
val DEFAULT_ENABLE_META_SSL: Boolean = false
val DEFAULT_ENABLE_STORAGE_SSL: Boolean = false
val DEFAULT_LIMIT: Int = 1000
val DEFAULT_RATE_LIMIT: Long = 1024L
val DEFAULT_RATE_TIME_OUT: Long = 100
val DEFAULT_POLICY: String = null
val DEFAULT_BATCH: Int = 1000
val DEFAULT_WRITE_MODE = WriteMode.INSERT
val EMPTY_STRING: String = ""
}
关于作者
顾是Nebula Graph的开发者拥护者。他热衷于将图形技术推广到开发人员社区,并尽最大努力使分布式图形数据库更易于访问。在推特上关注他吧。
原文标题:4 Different Ways to Work With Nebula Graph in Apache Spark
原文作者:Wey Gu
原文链接:https://dzone.com/articles/4-different-ways-to-work-with-nebula-graph-in-apac
